2026 年 PDF 轉 Markdown 完整指南(免費+RAG 就緒)
2026 年該怎麼把 PDF 正確地轉成 Markdown?線上免費工具、Pandoc 與 AI 抽取器三路橫評,附 RAG 工作流與 OCR 修補方案。

如果你曾經從 PDF 複製一段文字貼到別處,眼睜睜看著它變成一坨亂碼斷行、被截斷的連字號和遺失的格式,那你應該已經懂為什麼 PDF 轉 Markdown 在 2026 年成了一個真正的工作流問題。
PDF 是分享文件的通用貨幣,但作為來源格式它其實很糟。一旦你想把這些內容餵進 RAG 流程、丟進文件網站,或只是存到筆記軟體裡,你要的是有結構的文字 —— 標題就是標題、表格就是表格、程式碼就是程式碼。
這篇指南會老實地走過三條 PDF 轉 Markdown 的路:免安裝的線上轉換器、命令列上的 Pandoc,以及新一代 AI 驅動的抽取器(marker、Docling)。我會告訴你什麼場景挑哪一條、那些工具搞砸的東西(表格、公式、掃描頁)要怎麼補救,以及如何把輸出送進 LLM 流程而不必再清理第二次。
為什麼要把 PDF 轉成 Markdown?
同樣的轉換需求一直在三個不同的圈子裡反覆出現。每個圈子在乎的理由都不太一樣,但目標格式都一樣。
餵乾淨的文字給 RAG 與 LLM 流程
檢索增強生成(RAG)流程很討厭原始的 PDF 文字。分頁產生的雜訊、被壓平成單欄的雙欄版面、每頁重複的頁首頁尾 —— 這些通通會變成向量資料庫裡的雜訊,污染檢索結果。
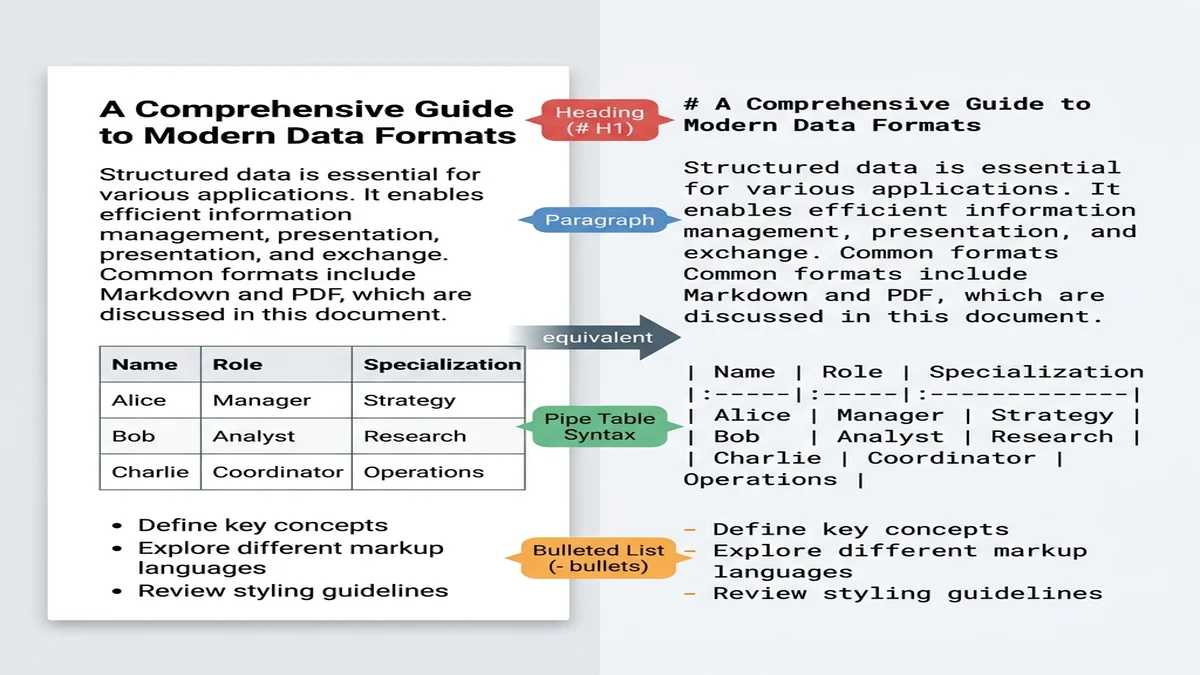
Markdown 比任何實用格式都更接近「有結構的純文字」。在網路資料上訓練的大型模型看過數十億份 markdown 文件(README、Stack Overflow 回答、部落格貼文),不必特別提示就能認出 # 是章節分界、| 是表格分隔符。
把舊 PDF 遷移進現代文件系統
Docusaurus、MkDocs、Astro Starlight、Hugo 都吃 markdown。如果你的團隊有 200 份內部舊文件的 PDF,你不會想養一支複製貼上大軍 —— 你需要的是一個能保留標題層級的轉換器,這樣導覽自動就建好了。
打造可搜尋的第二大腦
Obsidian、Logseq、Foam、Roam —— 每個現代筆記軟體都講 markdown。把紙本檔案數位化的學術工作者、歸檔會議紀錄的知識工作者、建立文獻庫的研究者,需要的都是同一件事:標題完整的乾淨 markdown 檔案,這樣之後才能跨幾百份文件 grep。
三種方法(什麼時候挑哪個)
工具有幾十個,但其實只有三個類別。對照自己的情境挑那一列。
| 方法 | 速度 | 簡單 PDF | 複雜 PDF | 掃描 OCR | 安裝 |
|---|---|---|---|---|---|
| 線上轉換器 | 快 | 優秀 | 良好 | 內建或自動 | 無 |
| Pandoc + pdftotext | 快 | 良好 | 表格普通 | 不支援 | 需裝 CLI |
| AI 抽取器(marker / Docling) | 慢 | 優秀 | 優秀 | 支援 | Python + ML 套件 |
如果你拿不定主意,先試線上轉換器。一分鐘就能驗證,對大多數一次性或小批次的工作而言這就結束了。要做程式化流程或處理密集的學術內容,再往下挑一列。我們在免費 Markdown 轉換器橫評裡聊過更廣的選擇。
方法 1:線上把 PDF 轉成 Markdown(免費、免安裝)
最快的一條路也是大多數人會跳過的,因為它看起來太簡單了。但對絕大多數日常工作 —— 會議筆記、文章、單章報告 —— 瀏覽器轉換器已經綽綽有餘。
直接把檔案丟進 我們的免費 PDF 轉 Markdown 工具,這一節後面的內容就可以略過。
操作步驟
- 把 PDF 拖到上傳區(或點擊選檔)。
- 等幾秒鐘讓解析器跑完。20 頁以內通常你還沒讀完這句話就轉好了。
- 在右側並排預覽渲染後的 markdown 與原始碼。
- 複製原始碼,或下載
.md檔。
就這樣。不用註冊、不用留 email、輸出沒有浮水印。
最適合的場景
- 一次性轉換、不想裝任何東西。
- 在投資程式化流程之前先快速試水溫。
- 對隱私敏感、不想把文件丟到第三方 API 的檔案。我們的轉換器在記憶體中處理,處理完立刻清除 —— 不做任何持久化存放。
限制
線上轉換器(不只是我們的)整體上有兩種失敗模式值得知道。
第一是非常大或不尋常的 PDF。一份 600 頁、嵌入字型、帶動態表單欄位的掃描法律揭露文件,對任何工具來說都不是「拖進去下載」就能搞定的。如果你手上是這種,直接跳到 AI 抽取器那一節。
第二是沒有文字層的掃描 PDF。它沒有文字可以抽取 —— 整頁就是一張圖。你得先做 OCR,請看下方的 處理棘手內容。
方法 2:在命令列上用 Pandoc
Pandoc 是文件轉換界的瑞士刀。當你需要一條可重現、可腳本化的流程,又不想依賴網路服務時,它就是對的工具。
老實說有個小坑:Pandoc 本身的 PDF 讀取能力不強。社群通用做法是先過 pdftotext(來自 Poppler 套件),再把結果管到 Pandoc。
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
對於以文字為主的簡單 PDF —— 備忘錄、單欄文章 —— 這個組合表現很好,幾毫秒就跑完。
當你在乎保真度
如果你的 PDF 大部分是散文,這條流程能給你一份段落結構完整的乾淨 markdown 檔。可以加上 -V 與 --wrap=none 兩個參數,讓輸出更符合那些不喜歡硬換行的下游工具。
Pandoc 不擅長的地方
- 多欄版面(學術論文、雜誌):
pdftotext會把欄位交錯排列,輸出根本沒法讀。 - 表格:只要稍微超出最簡單的雙欄表,通常會變成空白分隔的欄而不是 markdown 的管線符號。
- 公式與程式碼區塊:完全沒有語意保留;LaTeX 方程式變成普通文字、等寬程式碼變成一般段落。
- 掃描 PDF:完全不支援 —— Pandoc/pdftotext 沒辦法從圖像抽取文字。
表格的部分,我們的 Markdown 進階語法指南 裡有講你輸出該對齊到的 GFM 表格格式。
方法 3:AI 驅動的抽取(marker、Docling、pymupdf4llm)
2024–2025 年這波懂版面的抽取器改寫了可能性。這些工具把視覺版面偵測、OCR 和結構化輸出生成綁在一起,所以它們知道這一塊區域是表格、那一塊是雙欄正文。對複雜 PDF 的輸出乾淨度有著數量級的提升。
三個值得認識的專案:
- marker —— 用 surya(版面模型)加上一些啟發式規則。對學術論文、公式、程式碼區塊都很強。Apache 2.0。
- Docling —— 來自 IBM Research。表格重建非常優秀,原生整合 LlamaIndex 與 LangChain。MIT 授權。
- pymupdf4llm —— PyMuPDF 上的輕量包裝。比前兩者更快、ML 依賴更少,專為 LLM 餵入而設計。
最小可用的 Python 範例
這是最精簡可用的 Docling 流程:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
或者走更輕的 pymupdf4llm:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
取捨
這類工具比 Pandoc 路線慢。一台普通 CPU 筆電上,一篇 30 頁論文大概要幾十秒,而不是幾毫秒;上了 GPU,marker 可以壓回幾秒。pymupdf4llm 是三者中最快的,因為它跳過了重量級的視覺模型。
另一個取捨是依賴的體積。一句 pip install marker-pdf 會拉進 PyTorch 和好幾百 MB 的模型權重。如果你要打進容器發佈,要把這個體積算進去。
處理棘手內容
當你停止只在乾淨的兩頁備忘錄上測試、開始拿真實世界的 PDF 來跑時,各方法的差異就會非常明顯。
撐不過去的表格
表格是大多數轉換器翻車的地方。pdftotext + Pandoc 那條路線幾乎一定會吐出空白對齊的欄位粥,沒有任何 markdown 渲染器能正確解析。線上轉換器和 AI 抽取器在這點上好很多,因為它們會先偵測表格區域、再重建儲存格。
訣竅是:在信任其他輸出之前,先抽查第一張表。如果第一張就糟,剩下 50 張也跑不掉。
數學公式與 LaTeX 區塊
如果你的 PDF 有公式,你需要一個能偵測公式區域、並在 markdown 裡輸出 LaTeX($$...$$)區塊的工具。marker 做得到,Pandoc 做不到。對科學寫作而言,這是付出 AI 抽取器速度成本的最大單一理由。
程式碼區塊與行內程式碼
很多 PDF 把程式碼用等寬字型呈現,但在匯出時丟掉了「這是程式碼」的語意標記。AI 抽取器會用視覺風格 —— 等寬字型加上縮排 —— 重新偵測程式碼區域,再用三反引號圍起來。基於 Pandoc 的流程通常會把程式碼壓回普通段落。
註腳與引文
學術論文常用編號註腳搭配頁底的註文。pdftotext 路線會丟掉參考標記和註文之間的連結。Docling 與 marker 會把它們保留成正規的 markdown 註腳語法([^1] 引用 + [^1]: body 定義)。
掃描 PDF(需要 OCR)
掃描 PDF 是一張頁面的圖,不是文字。在你跑 OCR 之前根本沒東西可抽。

三條可靠的路:
-
ocrmypdf —— 在掃描 PDF 上加一層看不見的 OCR 文字層,視覺外觀不變。鋪好之後任何下游轉換器都能用:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
內建 OCR 模式的 AI 抽取器 —— marker 和 Docling 能偵測一頁沒有文字層、自動跑 OCR。輸出是整合好的,你會直接拿到一個 markdown 檔,不必經過中間 PDF。
-
內建自動 OCR 的線上轉換器 —— 有些瀏覽器工具(包括我們對純圖 PDF 的處理)會自動跑 OCR。方便,但如果你的文件不是英文,記得確認語言支援。
一個容易忽略的陷阱:「原生數位」PDF(從 Word 文件匯出、不是掃描來的)也可能沒有文字層,前提是它被以壓平圖像的方式匯出。先在 PDF 檢視器裡試試能不能選取文字。能選 —— 跳過 OCR。不能選 —— 跑一次。
把 Markdown 準備好餵進 RAG / LLM
如果目的地是向量資料庫,轉換時的幾個小選擇會讓下游的檢索品質明顯更好。
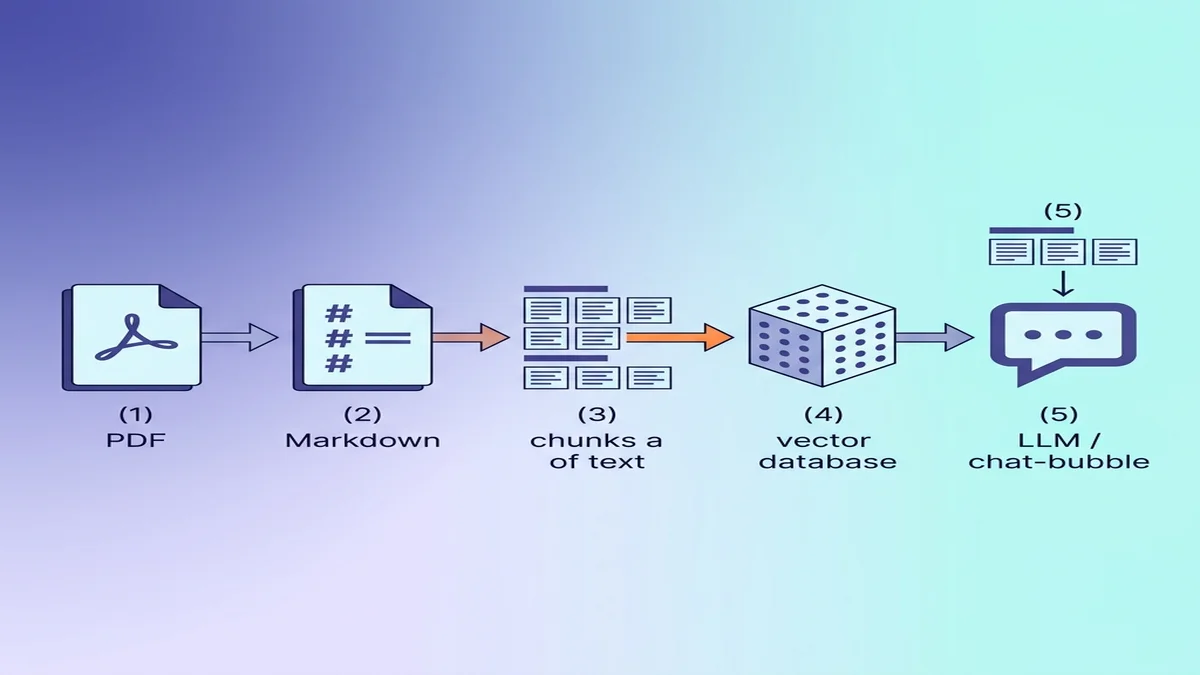
為什麼 Markdown 對 LLM 比純文字更好
Markdown 帶著純文字會丟失的結構。模型讀到 ## Methods 知道進入了新章節;同一段文字若把所有格式剝光,模型只會看到一堆等重的段落。如果你對語法還不熟,Markdown 基本語法指南 5 分鐘可以讀完。
依標題層級切塊
RAG 最常見的錯誤是固定大小切塊 —— 不管結構,硬把文件切成每塊 500 token。Markdown 讓你可以依語意切塊 —— 從 ## H2 邊界切,你拿到的是完整連貫的章節,而不是段落中段的碎片。
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
更好的做法是:把標題視為樹狀結構走,每個 H3 在切塊的 metadata 裡掛上對應的 H2 父節點。
用 frontmatter 保留中繼資料
在每份轉好的檔案最上方加一段 YAML frontmatter,讓來源資訊跟著每一塊文字一起走:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
當 LLM 取回一塊內容時,這些中繼資料就變成引用註腳。它也是你日後不必重跑檢索就能回答「這個說法是哪裡來的?」的關鍵。如果你想從聊天匯出的內容建這類流程,同樣的概念也適用於 ChatGPT/Claude 對話。
常見陷阱與避坑指南
第一次做這件事的人經常踩到下面這幾個。
- 跳過編碼正規化。 PDF 最愛玩 Unicode 把戲:連字(
fi、fl)、智慧引號("vs")、看起來像連字號的破折號。把輸出過一次 Unicode 正規化(Python 裡的 NFKC)再丟到任何地方。 - 保留頁首頁尾。 每頁的
Page 4 of 12頁尾都會變成檢索雜訊。固定間隔重複出現的行記得去掉。 - 信任你看到的第一張表。 至少抽查前兩張表,再假設其他都沒事。
- 把「原生數位」當成「有文字層」。 有些 PDF 雖然源自 Word 但被以壓平圖像的方式匯出。永遠先試試能不能選取文字。
- 小文件硬切塊。 一份 3 頁的備忘錄,直接把整份 markdown 餵給模型就好,跳過 RAG 步驟。context window 比文件大的時候,檢索根本是多餘的。
常見問題
最好的免費 PDF 轉 Markdown 工具是哪一個?
對大多數人而言,線上轉換器是最快的路 —— 拖、放、完成。批次或程式化作業裡,pymupdf4llm(Python)和 Pandoc(CLI)能處理簡單情境。對帶表格與公式的學術論文,marker 和 Docling 的輸出明顯更好。「最好」取決於你要優化安裝時間還是輸出保真度。
ChatGPT 或 Claude 能把 PDF 轉成 Markdown 嗎?
可以,有但書。兩者都能直接讀 PDF 並輸出 markdown,但長文件可能撞上 context 上限,表格與公式的準確度也會在不同回合間漂移。要做確定性的批次轉換,專用轉換器更可靠。相關的往返工作流可以參考 匯出 ChatGPT 到 Word/PDF/HTML。
怎麼把掃描 PDF 轉成 Markdown?
先跑 OCR。最乾淨的路是用 ocrmypdf 加上文字層,之後任何轉換器都能處理這個 OCR 過的 PDF。或者,marker 和 Docling 內建 OCR,可以直接從純圖 PDF 輸出 markdown。
線上 PDF 轉 Markdown 安全嗎?
我們的轉換器在記憶體裡處理檔案、轉完即清除 —— 不必註冊、不做持久化儲存。其他服務情況不一,使用前請看一下隱私政策,機密文件尤其要看。
怎麼讓表格在 PDF 轉 Markdown 時不走樣?
表格多的 PDF 別走 pdftotext + Pandoc 那條路 —— 幾乎一定會壞掉。改用會輸出 GFM 表格的線上轉換器,或用 marker、Docling 這種 AI 抽取器。不管哪一條路,前幾張表都要抽查。
我該留原始 PDF 還是只留 Markdown?
兩個都留。markdown 用於餵入、搜尋與編輯;PDF 是引用與稽核的真實來源。在 markdown 的 frontmatter 裡記下 PDF 檔名與頁碼範圍,這樣你永遠能把任何一個說法追回原始出處。
準備好轉你的第一份 PDF 了嗎?
如果你只想看結果,我們的免費 PDF 轉 Markdown 工具免註冊就能搞定日常需求。接下來那一步 —— 把 markdown 變成一份漂亮的 Word 文件或可分享的 PDF —— 請見我們的 Markdown 轉 Word 指南。
參考資料
- Pandoc User's Guide —— 最權威的 CLI 轉換參考手冊。
- GitHub Flavored Markdown Spec —— 本指南輸出對齊的 markdown 方言。
- Docling (IBM Research) —— 開源、懂版面的 PDF 抽取器。
- marker —— 開源 PDF 轉 markdown,對學術論文處理很強。
- pymupdf4llm —— PyMuPDF 上的輕量 markdown 抽取包裝。
- OCRmyPDF —— 為掃描 PDF 加上可搜尋的文字層。