PDF zu Markdown konvertieren 2026 (Kostenlos + RAG-tauglich)
PDFs sauber nach Markdown konvertieren — kostenlose Online-Tools, Pandoc und KI-gestützte Extraktoren im Vergleich. Mit RAG-Workflows und OCR-Tipps.

Wer schon einmal einen Absatz aus einem PDF kopiert und in ein Wirrwarr aus Zeilenumbrüchen, zerrissenen Bindestrichen und verlorener Formatierung verwandelt gesehen hat, weiß genau, warum die Konvertierung von PDF zu Markdown 2026 zu einem ernsthaften Workflow-Problem geworden ist.
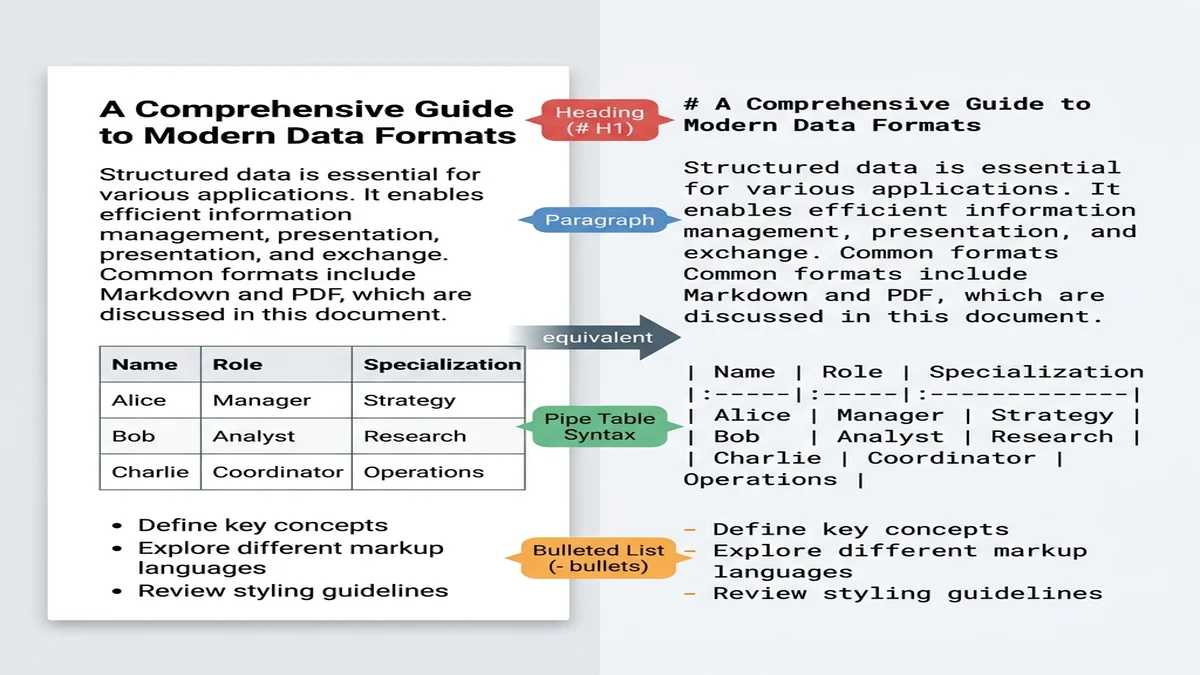
PDFs sind die universelle Tauschwährung für Dokumente. Sie sind aber auch ein miserables Quellformat. Sobald Sie diesen Inhalt in eine RAG-Pipeline speisen, in eine Dokumentationsseite einbinden oder einfach in Ihrer Notiz-App ablegen wollen, brauchen Sie strukturierten Text — Überschriften als Überschriften, Tabellen als Tabellen, Code als Code.
Dieser Guide zeigt drei ehrliche Wege, PDFs nach Markdown zu konvertieren: einen Online-Konverter ohne Installation, Pandoc auf der Kommandozeile und die neue Generation KI-gestützter Extraktoren wie marker und Docling. Sie erfahren, welcher Weg für welche Aufgabe taugt, wie Sie deren typische Schwächen (Tabellen, Mathematik, Scans) reparieren und wie die Ausgabe in einer LLM-Pipeline landet, ohne sie zweimal aufzuräumen.
Warum PDF zu Markdown konvertieren?
Dasselbe Konvertierungsproblem taucht in drei verschiedenen Communities auf. Jede hat ihre eigenen Motive, das Zielformat ist aber identisch.
Saubere Texte für RAG- und LLM-Pipelines
Retrieval-Augmented-Generation-Pipelines vertragen rohen PDF-Text schlecht. Seitenumbruch-Artefakte, in eine Spalte zusammengequetschte Zweispalter, sich auf jeder Seite wiederholende Kopf- und Fußzeilen — alles davon wird zu Rauschen in der Vektor-Datenbank und verschmutzt das Retrieval.
Markdown kommt "strukturiertem Klartext" näher als jedes andere praktikable Format. Große Modelle, die auf Web-Daten trainiert wurden, haben Milliarden Markdown-Dokumente gesehen (README-Dateien, Stack-Overflow-Antworten, Blogposts) und erkennen #-Überschriften als Abschnittsgrenzen sowie |-Pipes als Tabellentrenner, ohne dass man sie darauf hinweisen muss.
Alt-PDFs in moderne Dokumentations-Systeme migrieren
Docusaurus, MkDocs, Astro Starlight und Hugo wollen alle Markdown sehen. Wenn Ihr Team 200 PDFs interner Altdokumente vor sich hat, brauchen Sie keine Copy-Paste-Armee — sondern einen Konverter, der die Überschriftenhierarchie erhält, damit sich die Navigation von selbst aufbaut.
Ein durchsuchbares zweites Gehirn bauen
Obsidian, Logseq, Foam, Roam — jede moderne Notiz-App spricht Markdown. Wissenschaftler, die Papierarchive digitalisieren, Wissensarbeiter, die Sitzungsprotokolle archivieren, und Forschende, die Literaturbibliotheken aufbauen, brauchen alle dasselbe: eine saubere Markdown-Datei mit intakten Überschriften, damit sie später hunderte Dokumente per grep durchsuchen können.
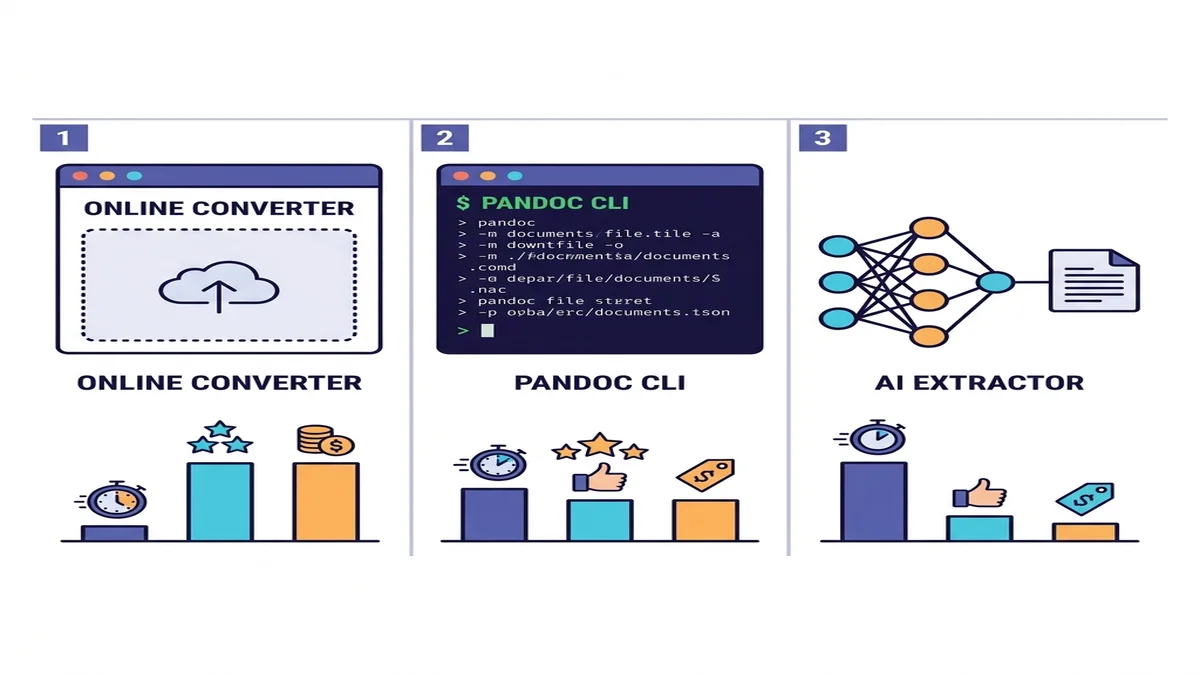
Die drei Ansätze (wann welcher passt)
Es gibt Dutzende Tools, aber im Grunde nur drei Kategorien. Wählen Sie die Zeile, die zu Ihrer Lage passt.
| Methode | Tempo | Einfache PDFs | Komplexe PDFs | OCR für Scans | Einrichtung |
|---|---|---|---|---|---|
| Online-Konverter | Schnell | Hervorragend | Gut | Eingebaut oder automatisch | Keine |
| Pandoc + pdftotext | Schnell | Gut | Mittelmäßig bei Tabellen | Nein | CLI-Installation |
| KI-Extraktor (marker / Docling) | Langsam | Hervorragend | Hervorragend | Ja | Python + ML-Deps |
Wenn Sie unsicher sind, starten Sie mit einem Online-Konverter. Der Versuch kostet eine Minute, und für die meisten Einmal- oder Klein-Batch-Jobs endet die Geschichte hier. Für programmgesteuerte Pipelines oder dichte wissenschaftliche Inhalte rutschen Sie eine Zeile tiefer. Den breiteren Marktüberblick liefert unsere Übersicht kostenloser Markdown-Konverter.
Methode 1: PDF zu Markdown online (kostenlos, ohne Installation)
Der schnellste Weg ist auch der, den die meisten überspringen, weil er zu simpel wirkt. Für einen überwältigenden Anteil der Alltagsarbeit — Sitzungsnotizen, Artikel, einkapitelige Berichte — reicht ein browserbasierter Konverter mehr als aus.
Sie können Ihre Datei direkt in unseren kostenlosen PDF-zu-Markdown-Konverter ziehen und den Rest dieses Abschnitts überspringen.
Schritt-für-Schritt-Ablauf
- Ziehen Sie das PDF per Drag-and-Drop auf die Upload-Zone (oder klicken Sie, um eine Datei auszuwählen).
- Warten Sie wenige Sekunden, bis der Parser fertig ist. Alles unter 20 Seiten ist meist konvertiert, bevor Sie diesen Satz zweimal gelesen haben.
- Vergleichen Sie das gerenderte Markdown rechts neben dem Quelltext.
- Kopieren Sie den Quelltext oder laden Sie eine
.md-Datei herunter.
Das war's. Kein Account, keine E-Mail-Hürde, keine Wasserzeichen auf der Ausgabe.
Wann das am besten passt
- Einmalige Konvertierungen, bei denen Sie nichts installieren wollen.
- Schnelle Stichproben, bevor Sie in eine programmgesteuerte Pipeline investieren.
- Vertrauliche Dateien, die Sie nicht durch eine Drittanbieter-API jagen möchten. Unser Konverter verarbeitet Dateien im Arbeitsspeicher und löscht sie sofort — keine persistente Speicherung.
Grenzen
Online-Konverter ganz allgemein (nicht nur unserer) haben zwei Schwachstellen, die man kennen sollte.
Die erste sind sehr große oder ungewöhnliche PDFs. Eine 600-seitige gescannte juristische Offenlegung mit eingebetteten Schriften und dynamischen Formularfeldern ist für kein Tool ein "ziehen-und-laden"-Szenario. Wenn Sie so etwas vor sich haben, springen Sie zum KI-Extraktor-Abschnitt.
Die zweite sind gescannte PDFs ohne Textebene. Es gibt nichts zu extrahieren — die Seite ist nur ein Bild. Sie brauchen erst OCR; siehe Schwierige Inhalte weiter unten.
Methode 2: Pandoc auf der Kommandozeile
Pandoc ist das Schweizer Taschenmesser der Dokumentkonvertierung. Es ist das richtige Werkzeug, wenn Sie eine reproduzierbare, skriptbare Pipeline brauchen und nicht von einem Web-Dienst abhängig sein wollen.
Der ehrliche Haken: Pandoc selbst hat keinen starken PDF-Leser. Der Community-Workflow läuft über pdftotext (aus den Poppler-Utilities) und leitet das Ergebnis in Pandoc weiter.
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
Für ein einfaches, textlastiges PDF — eine Aktennotiz, einen einspaltigen Artikel — funktioniert diese Kombination gut und läuft in Millisekunden.
Wenn Treue zählt
Wenn Ihr PDF überwiegend Fließtext ist, liefert diese Pipeline eine saubere Markdown-Datei mit erhaltener Absatzstruktur. Ergänzen Sie -V und --wrap=none, um die Ausgabe für nachgelagerte Tools anzupassen, die mit harten Umbrüchen nicht klarkommen.
Wo Pandoc strauchelt
- Mehrspaltige Layouts (wissenschaftliche Arbeiten, Magazine):
pdftotextverschachtelt die Spalten und Sie bekommen unlesbaren Output. - Tabellen: Alles jenseits des simpelsten Zweispalters landet meist als leerzeichengetrennte Spalten statt als Markdown-Pipes.
- Mathematik und Codeblöcke: keine semantische Erhaltung; LaTeX-Gleichungen werden zu Text, Code-Festbreitenschrift wird zu normalen Absätzen.
- Gescannte PDFs: null Unterstützung — Pandoc/pdftotext kann keinen Text aus Bildern extrahieren.
Speziell zu Tabellen: Unser Guide zur erweiterten Markdown-Syntax zeigt das GFM-Tabellenformat, an das die Ausgabe sich halten sollte.
Methode 3: KI-gestützte Extraktion (marker, Docling, pymupdf4llm)
Die Welle layout-bewusster Extraktoren von 2024–2025 hat verändert, was möglich ist. Diese Werkzeuge kombinieren visuelle Layout-Erkennung mit OCR und strukturierter Ausgabegenerierung — sie verstehen, dass diese Region eine Tabelle ist und jene Region ein zweispaltiger Fließtextkörper. Das Ergebnis ist auf komplexen PDFs dramatisch sauberer.
Drei Projekte, die man kennen sollte:
- marker — nutzt surya (ein Layout-Modell) plus Heuristiken. Stark bei wissenschaftlichen Arbeiten, Mathematik und Codeblöcken. Apache 2.0.
- Docling — von IBM Research. Hervorragende Tabellen-Rekonstruktion, dockt nativ an LlamaIndex und LangChain an. MIT-lizenziert.
- pymupdf4llm — leichter Wrapper um PyMuPDF. Schneller als die anderen beiden, weniger ML-Abhängigkeiten, speziell für LLM-Ingestion entwickelt.
Ein minimales Python-Beispiel
Die kleinste nützliche Docling-Pipeline:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
Oder mit pymupdf4llm für den leichtgewichtigen Weg:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
Abwägungen
Diese Werkzeuge sind langsamer als die Pandoc-Pipeline. Auf einem typischen CPU-Laptop dauert eine 30-seitige Arbeit eher Dutzende Sekunden als Millisekunden; mit GPU sinkt das bei marker zurück auf wenige Sekunden. pymupdf4llm ist der schnellste der drei, weil es auf schwere Vision-Modelle verzichtet.
Der zweite Kompromiss ist das Abhängigkeitsgewicht. Ein pip install marker-pdf zieht PyTorch und einige hundert Megabyte Modellgewichte nach sich. Wenn Sie das in einem Container ausliefern, planen Sie die Größe ein.
Schwierige Inhalte
Die Unterschiede zwischen den Methoden werden offensichtlich, sobald Sie aufhören, an sauberen zweiseitigen Notizen zu testen, und reale PDFs durchschicken.
Tabellen, die nicht überleben
Tabellen sind der Punkt, an dem die meisten Konverter versagen. Der Pfad pdftotext + Pandoc produziert fast immer leerzeichenausgerichtete Spaltensuppe, die kein Markdown-Renderer korrekt parst. Online-Konverter und KI-Extraktoren machen das deutlich besser, weil sie die Tabellenregion zuerst erkennen und die Zellen dann rekonstruieren.
Der Trick: Prüfen Sie Ihre erste Tabellenausgabe stichprobenartig, bevor Sie dem Rest vertrauen. Ist die erste Tabelle zerschossen, sind es die anderen 50 ebenfalls.
Mathematische Gleichungen und LaTeX-Blöcke
Wenn Ihr PDF Gleichungen enthält, brauchen Sie ein Werkzeug, das Mathematik-Regionen erkennt und LaTeX-Blöcke ($$...$$) im Markdown ausgibt. marker tut das; Pandoc nicht. Für wissenschaftliche Texte ist das der wichtigste einzelne Grund, den Geschwindigkeitsaufpreis des KI-Extraktors zu zahlen.
Codeblöcke und Inline-Code
Viele PDFs setzen Code in einer Festbreitenschrift, verlieren beim Export aber das semantische "das ist Code"-Tag. KI-Extraktoren erkennen Code-Regionen erneut anhand visueller Merkmale — Festbreitenschrift und Einrückung — und packen sie wieder in dreifache Backtick-Fences. Pandoc-basierte Pipelines plätten Code meist zurück in normale Absätze.
Fußnoten und Zitate
Wissenschaftliche Arbeiten verwenden nummerierte Fußnoten, deren Inhalt am Seitenende steht. Der pdftotext-Pfad verliert die Verbindung zwischen Referenzmarker und Fußnotenkörper. Docling und marker erhalten sie als richtige Markdown-Fußnotensyntax ([^1]-Referenz + [^1]: Text-Definition).
Gescannte PDFs (OCR erforderlich)
Ein gescanntes PDF ist ein Bild einer Seite, kein Text. Es gibt nichts zu extrahieren, bevor Sie OCR laufen lassen.

Drei verlässliche Wege:
-
ocrmypdf — fügt einem gescannten PDF eine unsichtbare OCR-Textebene hinzu, ohne das visuelle Erscheinungsbild zu verändern. Sobald die Ebene drinliegt, funktioniert jeder nachgelagerte Konverter:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
KI-Extraktoren mit OCR-Modus — marker und Docling erkennen, wenn eine Seite keine Textebene hat, und führen OCR automatisch aus. Die Ausgabe ist integriert, Sie erhalten also eine Markdown-Datei statt eines Zwischen-PDFs.
-
Online-Konverter mit Auto-OCR — manche Browser-Tools (unseres eingeschlossen, für reine Bild-PDFs) führen OCR transparent aus. Bequem, aber achten Sie auf die Sprachunterstützung, wenn Ihr Dokument nicht auf Englisch ist.
Eine subtile Falle: "Digital geborene" PDFs (aus einem Word-Dokument exportiert, nicht gescannt) können trotzdem keine Textebene haben, wenn sie als geflattete Bilder exportiert wurden. Prüfen Sie immer zuerst, ob Sie Text im PDF-Viewer markieren können. Wenn ja, überspringen Sie OCR. Wenn nein, lassen Sie es laufen.
Markdown für RAG- / LLM-Ingestion vorbereiten
Wenn das Ziel eine Vektor-Datenbank ist, machen einige kleine Entscheidungen während der Konvertierung die nachgelagerte Retrieval-Qualität spürbar besser.
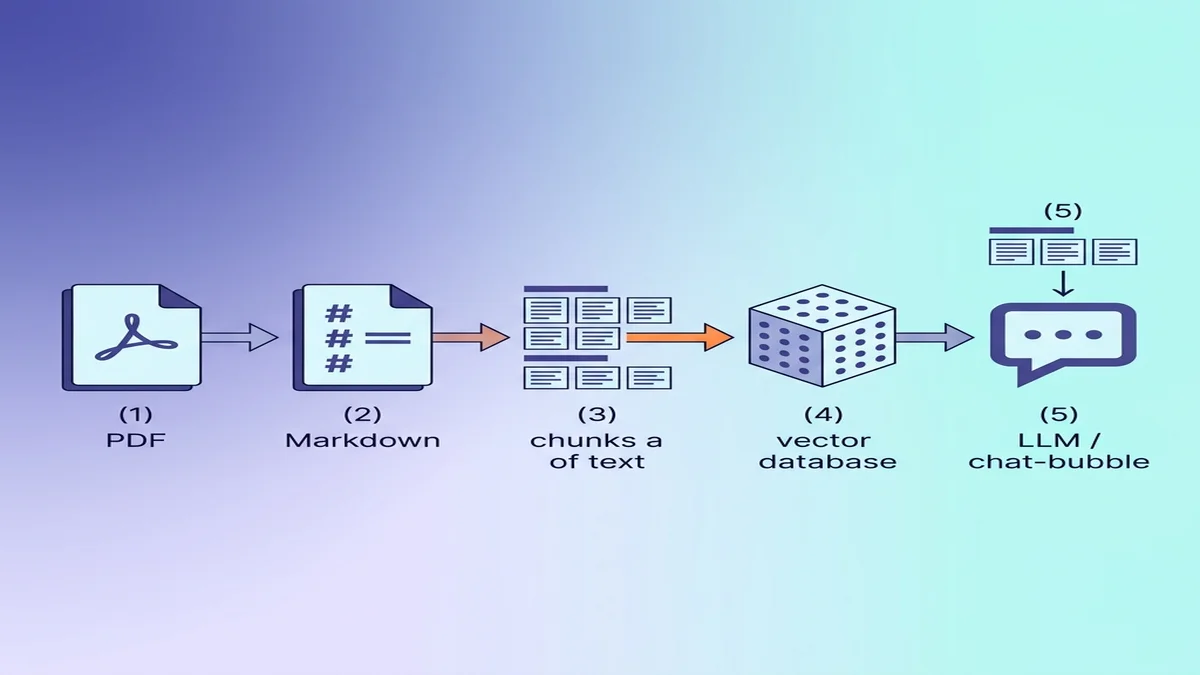
Warum Markdown rohen Text für LLMs schlägt
Markdown trägt Struktur, die Klartext verliert. Ein Modell, das ## Methoden liest, weiß, dass es einen neuen Abschnitt betreten hat; ein Modell, das denselben Text ohne Formatierung sieht, erkennt nur gleichgewichtige Absätze. Wenn Sie neu in der Syntax sind: unser Grundlagen-Guide zu Markdown ist in fünf Minuten gelesen.
Chunking entlang der Überschriftenhierarchie
Der häufigste RAG-Fehler ist Fixgrößen-Chunking — den Text in 500-Token-Blöcke zerlegen, egal welche Struktur er hat. Markdown erlaubt semantisches Chunken — splitten Sie an ## H2-Grenzen, und Sie erhalten zusammenhängende Abschnitte statt Mitten-im-Absatz-Fragmente.
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
Besser: Begehen Sie die Überschriften als Baum und hängen Sie jede H3 in den Chunk-Metadaten an ihre Eltern-H2.
Metadaten im Frontmatter erhalten
Setzen Sie an den Anfang jeder konvertierten Datei einen YAML-Frontmatter, damit die Quellinformationen mit jedem Chunk mitreisen:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
Wenn das LLM einen Chunk abruft, werden diese Metadaten zur Zitations-Fußzeile. Damit beantworten Sie später auch die Frage "Woher stammt diese Behauptung?", ohne das Retrieval neu zu starten. Wenn Sie eine solche Pipeline aus Chat-Exporten aufbauen: dieselbe Idee gilt für ChatGPT/Claude-Transkripte.
Häufige Stolperfallen und wie Sie ihnen ausweichen
Ein paar Dinge erwischen alle, die das zum ersten Mal machen.
- Encoding-Normalisierung weglassen. PDFs lieben Unicode-Tricks: Ligaturen (
fi,fl), typografische Anführungszeichen, Geviertstriche, die wie Bindestriche aussehen. Schicken Sie die Ausgabe durch einen Unicode-Normalisierungsschritt (NFKC in Python), bevor Sie sie irgendwo weiterfüttern. - Seitenkopf- und -fußzeilen stehen lassen. Jede
Seite 4 von 12-Fußzeile wird zu Rauschen im Retrieval. Streichen Sie wiederholte Zeilen, die in regelmäßigen Abständen auftauchen. - Der ersten Tabelle blind vertrauen. Prüfen Sie mindestens die ersten zwei Tabellen, bevor Sie annehmen, dass der Rest in Ordnung ist.
- Annehmen, "digital geboren" heißt "hat eine Textebene". Manche PDFs werden als geflattete Bilder exportiert, obwohl sie als Word-Dokumente begannen. Versuchen Sie immer zuerst, Text zu markieren.
- Kleine Dokumente überchunken. Bei einer 3-seitigen Notiz schicken Sie einfach das ganze Markdown ans Modell und sparen sich den RAG-Schritt komplett. Retrieval ist Overkill, wenn das Kontextfenster größer als das Dokument ist.
FAQ
Was ist der beste kostenlose PDF-zu-Markdown-Konverter?
Für die meisten Nutzer ist ein Online-Konverter der schnellste Weg — ziehen, ablegen, fertig. Für Batch- oder programmgesteuerte Arbeit decken pymupdf4llm (Python) und Pandoc (CLI) die einfachen Fälle ab. Für wissenschaftliche Arbeiten mit Tabellen und Mathematik liefern marker und Docling spürbar bessere Ergebnisse. Die "beste" Wahl hängt davon ab, ob Sie auf Einrichtungszeit oder Ausgabe-Treue optimieren.
Können ChatGPT oder Claude PDF zu Markdown konvertieren?
Können sie, mit Einschränkungen. Beide können ein PDF direkt lesen und Markdown ausgeben, aber bei langen Dokumenten stoßen Sie an Kontext-Grenzen, und die Genauigkeit bei Tabellen und Mathematik schwankt zwischen Durchläufen. Für deterministische Batch-Konvertierungen ist ein spezialisierter Konverter zuverlässiger. Den verwandten Hin-und-Rückweg beschreibt ChatGPT zu Word/PDF/HTML exportieren.
Wie konvertiere ich ein gescanntes PDF zu Markdown?
Lassen Sie zuerst OCR laufen. Der sauberste Weg ist ocrmypdf, um eine Textebene hinzuzufügen, danach funktioniert jeder Konverter auf dem OCR-PDF. Alternativ haben marker und Docling OCR eingebaut und erzeugen Markdown direkt aus reinen Bild-PDFs.
Ist Online-PDF-zu-Markdown-Konvertierung privat?
In unserem Konverter werden Dateien im Arbeitsspeicher verarbeitet und nach der Konvertierung gelöscht — kein Account nötig, keine persistente Speicherung. Andere Dienste variieren; prüfen Sie die Datenschutzerklärung jedes Tools, das Sie verwenden, besonders bei vertraulichen Dokumenten.
Wie erhalte ich Tabellen bei der PDF-zu-Markdown-Konvertierung intakt?
Überspringen Sie die pdftotext + Pandoc-Pipeline bei tabellenlastigen PDFs — sie zerlegt sie fast immer. Nutzen Sie einen Online-Konverter, der GFM-Tabellen ausgibt, oder einen KI-Extraktor wie marker oder Docling. Stichprobenartig die ersten Tabellen prüfen, egal welchen Weg Sie wählen.
Soll ich das Original-PDF behalten oder nur das Markdown?
Behalten Sie beides. Das Markdown ist für Ingestion, Suche und Bearbeitung. Das PDF ist Ihre Quelle der Wahrheit für Zitate und Audits. Verweisen Sie im Markdown-Frontmatter auf Dateinamen und Seitenbereich des PDFs, damit Sie eine Behauptung jederzeit zur Quelle zurückverfolgen können.
Bereit, Ihr erstes PDF zu konvertieren?
Wenn Sie nur das Ergebnis wollen, deckt unser kostenloser PDF-zu-Markdown-Konverter die Alltagsfälle ohne Anmeldung ab. Für den nächsten Schritt — dieses Markdown in ein poliertes Word-Dokument oder ein versandfertiges PDF zu verwandeln — werfen Sie einen Blick auf unseren Markdown-zu-Word-Guide.
Quellen
- Pandoc User's Guide — die kanonische Referenz zur CLI-Konvertierung.
- GitHub Flavored Markdown Spec — der Dialekt, auf den dieser Guide bei der Ausgabe abzielt.
- Docling (IBM Research) — quelloffener layout-bewusster PDF-Extraktor.
- marker — quelloffene PDF-zu-Markdown-Konvertierung mit starker Behandlung wissenschaftlicher Arbeiten.
- pymupdf4llm — leichter Markdown-Extraktions-Wrapper um PyMuPDF.
- OCRmyPDF — fügt gescannten PDFs eine durchsuchbare Textebene hinzu.