WordからMarkdownへ:2026年版・実践移行ガイド
Word文書をGitワークフローやObsidianで使える綺麗なMarkdownに変換する方法を解説。表・リスト・画像の処理、Pandocやオンラインコンバーターの使い分け、クリーンアップの実践テクニックまで。

依頼は、たいてい軽い一言から始まります。「このWord文書、チームのWikiに移せませんか?」
共有ドライブを開くと、300個の .docx ファイルが並んでいます。ポリシー、運用手順書、議事録、仕様書 — 10年分の社内ドキュメントが一貫性のない命名でフォルダに散らばっています。Gitでdiffは取れず、検索もまともに効かない。そして誰かが「四半期末までに全部Git管理のMarkdownに移す」と決めてしまった。
私はこの手の移行を2回経験しました。一度はコンプライアンス関連のアーカイブ(約200ファイル)、もう一度はエンジニアリングのナレッジベース(約500ファイル)です。2回とも得た教訓は同じで、WordからMarkdownへの変換はワンクリックで終わる作業ではありません。それは変換・検査・クリーンアップという3段階のパイプラインであり、時間の大半はクリーンアップに費やされます。
この記事では、実務で本当に使える3つの変換方法、Wordのどの機能が変換を生き延びて(どれがひっそり失われるのか)、そして手作業の手戻りを何時間も減らす変換後チェックリストを紹介します。
そもそもなぜWordからMarkdownへ移行するのか
How の前に、まず Why を整理しましょう。チーム内で理由を言語化できていないと、移行は定着しません。
- 差分が取れる履歴。 Wordの
.docxはZIP圧縮されたXMLの塊です。Gitから見ると、2つのバージョンはただのランダムなバイナリにしか見えません。Markdownはプレーンテキストなので、すべての変更が読めるdiffになります。 - 検索と grep。
rg "インシデント対応" docs/なら、数千のMarkdownファイルを横断してミリ秒で検索できます。Wordで同じことをやろうとすると、専用の検索ツールが必要です。 - 自動化。 Markdownは静的サイトジェネレーター、ドキュメントツール(Docusaurus、MkDocs、Nextra)、LLMの取り込みパイプライン、CIシステム、Linterなどで消費できます。WordはほぼWordでしか消費できません。
- 長寿命。 プレーンテキストファイルはソフトウェアベンダーより長生きします。DOCXは現時点では安定したフォーマットですが、古いバイナリ形式の
.docの互換性はすでに怪しくなりつつあります。
どれもチームに当てはまらないなら、移行する必要はないかもしれません。1つでも刺さるなら、この記事はあなた向けです。
変換で残るもの、失われるもの
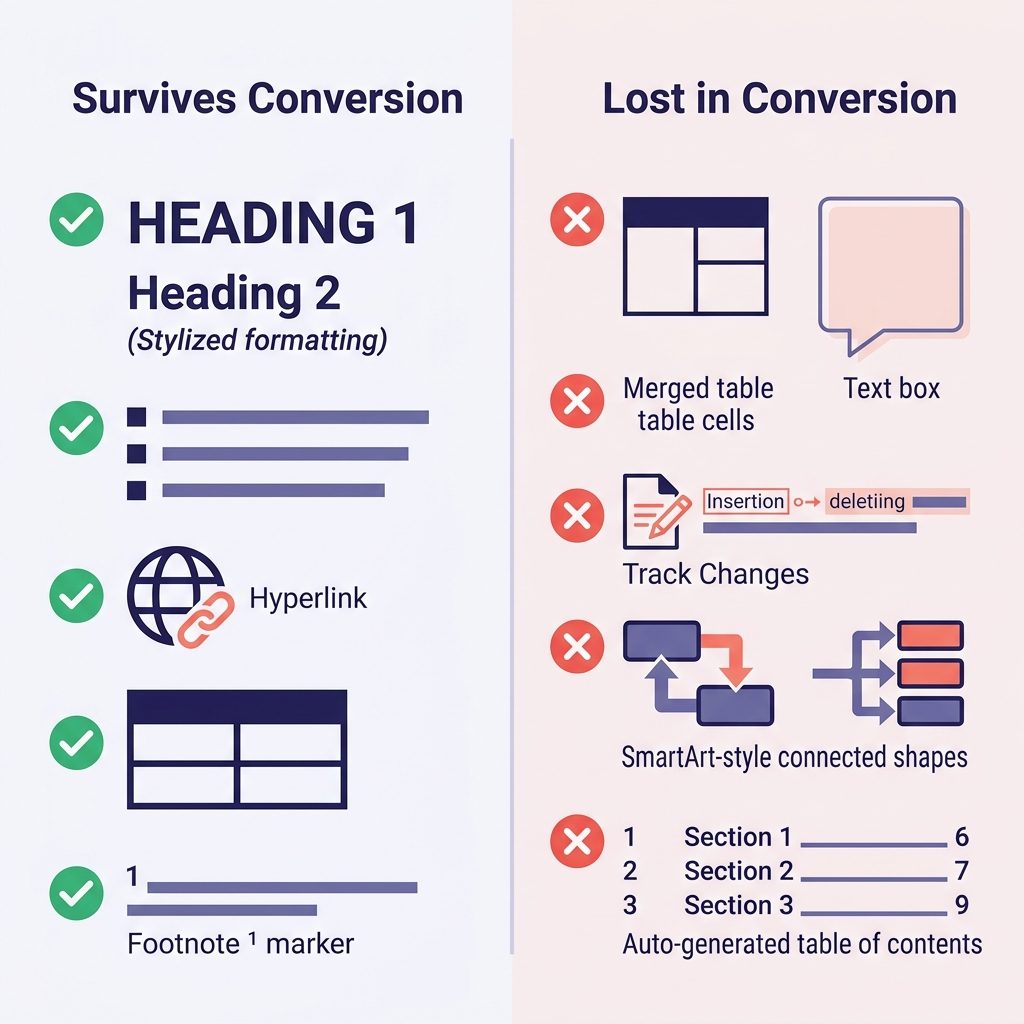
最初に期待値を合わせておくのが、結局いちばん時間の節約になります。数百回の変換で観察したパターンをまとめたのが次の表です。
| Wordの機能 | 残るか | 備考 |
|---|---|---|
| 見出し(Heading 1–6 スタイル) | ○ はい | # 〜 ###### にそのままマッピング |
| 太字・斜体・下線 | ○ 太字と斜体は残る | 下線はMarkdownに相当する記法がない(斜体になるかHTMLの <u> になる) |
| 箇条書き・番号付きリスト | ○ だいたい残る | 深いネストが潰れることがある |
| ハイパーリンク | ○ はい | URLとリンクテキストが保持される |
| 表 | △ シンプルなものは残る | セル結合、セルの色、罫線は失われる |
| インライン画像 | ○ はい | フォルダに抽出され、リンクが書き換えられる |
| 脚注 | ○ はい(GFM) | [^1] 記法に変換される |
コード(Code スタイル段落の場合) | △ ケースバイケース | フェンスなしのプレーンテキストに潰れがち |
| 数式 | △ 部分的 | LaTeXに変換されることもあれば、潰れることもある |
| 変更履歴 | × なし | すべて承認または拒否してから変換する |
| コメント | × なし | 事前に解決するか、別途エクスポートする |
| テキストボックス、SmartArt、図形 | × なし | 完全に失われる — 事前に画像かプレーンテキストに置き換えておく |
| 自動生成の目次 | × なし | ドキュメントツール側で再生成する |
| Wordのフィールド(日付、相互参照) | × なし | エクスポート前にプレーンテキストに変換する |
移行時に一番びっくりするのは、だいたい次の2つです。(1)見出し「のように見える」部分が、実は手動の太字+フォントサイズ変更で作られていて、変換後はただの太字テキストになり構造が消えている、というケース。(2)セル結合のある表が、見た目も崩れて再構築が必要になるケース。
一括変換を始める前に、ソース文書を10個ほどランダムに眺めて、この種の問題にマークを付けておきましょう。30分もあればできる作業で、後のやり直しを大幅に減らせます。
方法1:オンラインコンバーター
単発のファイルや小規模な一括処理(50ファイル以下くらい)なら、これが私のおすすめです。セットアップ不要で、.docx から綺麗なMarkdownに辿り着く最短ルートです。
- Word to Markdown変換ツールを開く
- アップロードエリアに
.docxファイルをドラッグする - 変換されたMarkdownをプレビューする
.mdファイルをダウンロードする(画像がある場合は別途まとめられます)
出力はGitHub Flavored Markdown(GFM)なので、表・タスクリスト・脚注は保持されます。見出しは # レベルに、リストは階層構造を保ったまま、ハイパーリンクはアンカーテキスト付きで変換されます。
補足として、標準的な文書は基本的にブラウザ内で変換処理が走ります。大きなファイルを扱うときや機密情報を含む文書の場合、ファイルが外部サーバーに出ないというのは単なる宣伝文句ではなく実質的なメリットです。
オンラインコンバーター全般(当ツールに限らず)の制約は同じで、バッチ処理には向かず、パイプラインに組み込むスクリプト化もできません。そういうケースは方法2に進みましょう。
方法2:Pandoc(バッチ処理とスクリプト向け)
Pandoc は万能のドキュメントコンバーターです。ファイル数がそこそこあるときや、出力を細かくチューニングしたいときに、私が真っ先に手を伸ばすツールです。
基本コマンド
pandoc document.docx -o document.md
単発ファイルならこれで終わりです。高速に動作し、読みやすい出力を返してくれて、Wordのよくある機能は標準で処理してくれます。ただしPandocの真価はフラグを足したときに出てきます。
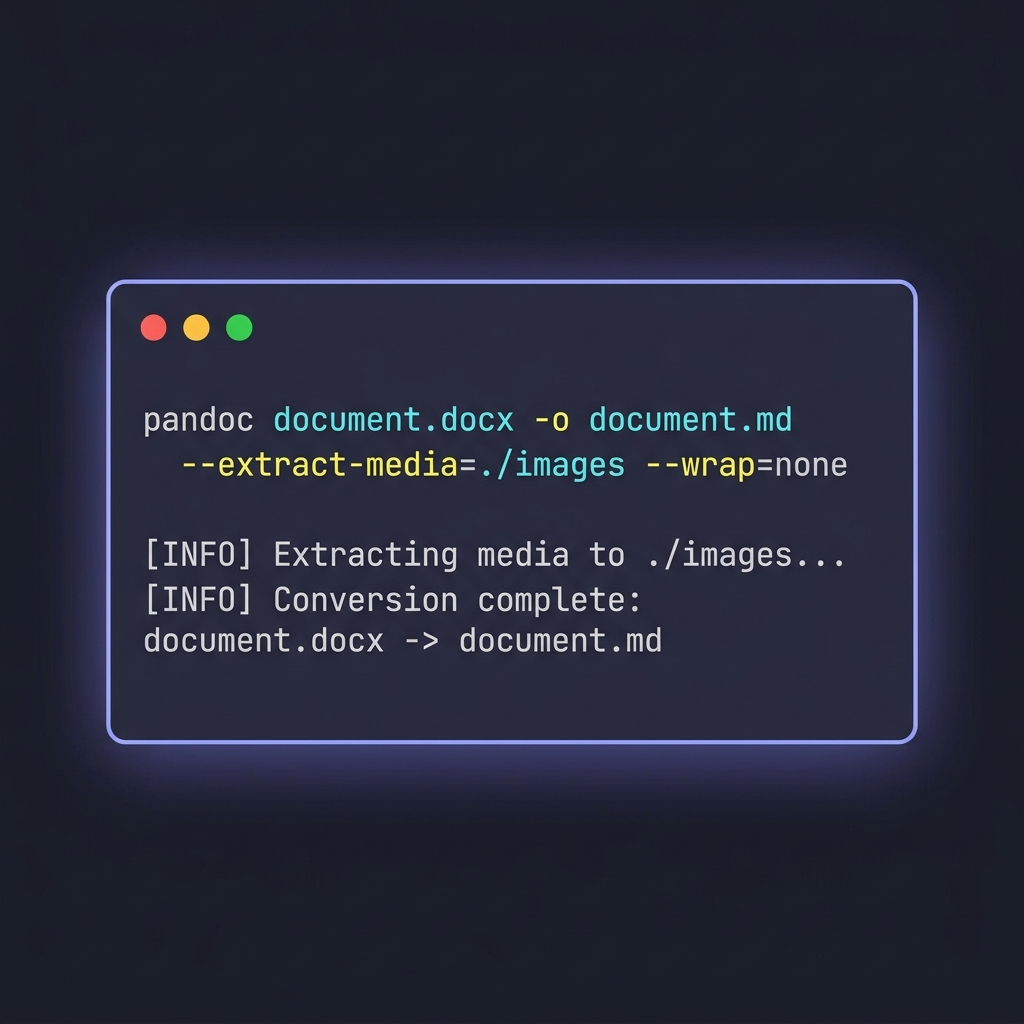
覚えておきたい3つのフラグ
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— DOCXに埋め込まれた画像を抜き出してフォルダに配置し、出力の画像リンクを書き換えます。このフラグを付け忘れると、インライン画像は黙って消えます。--wrap=none— Pandocが80文字付近で行をハード折り返しするのを防ぎます。文章中心のドキュメントでは、ハード折り返しがGitのdiffの読みやすさを壊すので重要です。--markdown-headings=atx— 古いsetextスタイル(====で下線を引く形式)ではなく、# Heading記法を強制します。ATXが現代の標準です。
フォルダの一括変換
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
これをシェルスクリプトに仕込めば、数百ファイルを数分で処理できます。より大きなアーカイブでは、trap とログ出力を追加して、途中で落ちたときに再開できるようにしておくと安心です。
現場で遭遇するハマりどころ
- 箇条書きの記号がバラバラになる。 Pandocは
-を使ったり*を使ったりします。統一したいなら、出力に対してsed -i 's/^\* /- /g'を走らせるか、エディタのMarkdownフォーマッターで設定しましょう。 - 番号付きリストの番号が予期せずリセットされる。 Wordにはしばしば「番号を継続する」指定が入っていますが、Pandocはそれを解釈できません。元は連続していたリストが
1, 2, 1, 2, 3のように数えられることがあります。レビューパスで直せる範囲です。 - 長いセルのある表が可読性の問題を起こす。 Pandocは頑張ってくれますが、GFMの表はWordのようなセル内改行に対応していません。特に複雑な表は、手動でHTMLブロックに変換してしまうのも手です。
PandocにはGUIがありません。これは欠点(非エンジニアのチームメイトには使えない)でもあり、利点(CI/CDパイプラインに簡単に組み込める)でもあります。
方法3:Mammoth.jsによるプログラム的変換
パイプラインを構築する場合 — たとえばSharePointからDOCXを取ってきて変換し、Gitにコミットする移行スクリプトのような — WebのUIもPandocへのサブプロセス呼び出しもフィットしないことがあります。Mammoth.js は、Node.js上でDOCXを綺麗なHTMLまたはMarkdownに直接変換できるJavaScriptライブラリです。
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // 変換後のMarkdown出力
console.log(result.messages); // 未対応機能に関する警告
});
Mammothが便利なのは、その割り切った方針にあります。Wordの見た目のスタイルを完全に無視して、意味的な構造(見出し、リスト、表)だけに集中するのです。結果としてPandocより標準で綺麗な出力になりますが、コントロール性は下がります。構造がある程度揃っているレガシーアーカイブの移行にはMammothを選びます。装飾が凝った一点物ドキュメントが多いなら、Pandocの柔軟性に軍配が上がります。
Pythonユーザー向けには python-docx とMarkdownライターを組み合わせる選択肢がありますが、こちらは既製ツールというよりDIY寄りのアプローチです。
誰も警告してくれないクリーンアップ工程

変換が終わると .md ファイルは手に入ります。しかし、それは「コミットしたい .md ファイル」ではまだありません。
私の標準的な変換後チェックリストはこちらです。慣れればドキュメント1つあたり5分ほどで回せます。
- 構造化に失敗した見出しを探す。 出力の中で、見出しっぽいのに実体は
**太字テキスト**が単独行になっているものをチェックします。Wordで見出しスタイルを使わず手動で装飾した箇所です。これらは本物の##見出しに昇格させましょう。 - 最初の表を確認する。 ここで表が正しく見えるなら、残りもだいたい大丈夫です。逆に最初が壊れていたら、全部壊れています。
- リスト項目内の空行を取り除く。 Pandocはたまにリストの連続性を壊す空行を挿入します。
- 画像リンクを検証する。 Markdownプレビュー(VS Codeの組み込みプレビューで十分)でファイルを開き、画像が実際に表示されるか確認します。
- 迷子のアーティファクトを検索する。 よく残るもの: 行末の
\(Wordでは隠れていたハード改行がMarkdownで顕在化したもの)、{.underline}というスタイル属性、<span>タグの取り残し。 - 先頭と末尾の10行を確認する。 Wordのヘッダー、フッター、ページ番号が、空のコンテンツや奇妙なアーティファクトとして出力に漏れてくることがよくあります。
大規模な移行なら、5番と6番はクリーンアップスクリプトで自動化しましょう。それ以外の項目は人の目を通したほうが結果が良いです — 少なくとも、特定のドキュメント系統について「このパターンなら信頼できる」と判断できるだけの経験則が溜まるまでは。
実例:200ファイルのコンプライアンスアーカイブの移行
コンプライアンスアーカイブ移行で私が使ったワークフローを紹介します。200ファイルを着手から完了まで2日で片付けました。
1日目・午前:ソースのトリアージ
DOCXを1つずつ開き、見出し数、画像数、表の数をカウントし、変更履歴が残っているものやコメントがあるものにフラグを立てるPythonスクリプトを書きました。出力は複雑度順にソートしたCSVです。この時点ではまだ何も修正しません。目的はこれから向き合う相手を把握することだけです。
1日目・午後:シンプルなファイルの一括変換
200ファイルのうち約140個は素直でした。画像なし、シンプルな表、綺麗な見出し構造。--extract-media と --wrap=none を付けたPandocループに流して、ランダムに20個をサンプリング確認。すべて良好。
2日目・午前:複雑なファイルを個別対応
残りの60ファイルには問題がありました — セル結合のある表、埋め込みスプレッドシートオブジェクト、誰かが先にレビューすべき大量の変更履歴。これらはオンラインコンバーターでケースバイケースに処理し、フラグを変えてPandocを走らせたり、元のDOCX側を先に掃除したりしました。
2日目・午後:クリーンアップとコミット
200ファイル全体に対してクリーンアップスクリプトを実行({.underline} アーティファクトの除去、箇条書き記号の統一、Pandocの折り返し出力の修正)。diffをレビューし、50ファイルずつのバッチに分けてコミットし、移行ブランチにプッシュ。
もしこれを手作業で — Word文書を1つずつ開いてMarkdownエディタに貼り付けて — やろうとしたら、最低でも2週間はかかっていたでしょう。変換ツールはあったほうが良いという次元ではなく、このプロジェクトを現実的なスケジュールに収めるための必須要素です。
よくある問題と対処法
Markdownプレビューで表が崩れて見える
9割のケースで、元の文書にセル結合があるか、非常に長いセル内容があります。GFMの表はそのどちらもうまく扱えません。選択肢は3つ: GFMで表を手動で作り直す、Markdown内にHTMLの <table> ブロックを使う(ほとんどのレンダラーが対応)、大きな表をシンプルな複数の表に分割する。
画像が表示されない
コンバーターが画像を抽出したか確認しましょう。Pandocは --extract-media を付けない限り抽出しません。オンラインコンバーターの場合は、通常MarkdownファイルとZIPにまとめられた images/ フォルダが一緒にダウンロードされるので、両方が正しい場所にあり、Markdown内の画像パスと一致しているかを確認してください。
出力の行末に妙なバックスラッシュが付いている
これはWord由来のハード改行で、Markdownでは強制改行としてレンダリングされます。元のWord文書が、段落区切りではなく改行で段落間の詰まり具合を調整していた場合、Pandocはそれをそのまま保持します。\\$(行末)に対する一括置換で大抵は片付きます。
変換後に見出しレベルがずれている
Word文書は「見出し1」がタイトルページ用に予約されていて、本文が見出し2や見出し3から始まっていることがよくあります。Markdownの慣習では #(H1)から始めます。ドキュメントシステムがどう見出しを表示するかによりますが、全体のレベルを1つ繰り上げる必要があるかもしれません。sed で対応できます: sed -i 's/^## /# /; s/^### /## /; ...' file.md。
Markdownが見た目としてWord文書と全然違う
それは仕様です。Markdownは「構造」を記述するものであり、「見た目」ではありません。見た目は、Markdownをレンダリングするシステム(GitHub、ドキュメントサイト、MkDocsテーマなど)が決めます。ビジュアルの忠実性が重要ならPDFのほうが適したターゲットです — 詳しくはMarkdown PDF変換ガイドで、デザインを保持するワークフローを紹介しています。
双方向変換:MarkdownからWordへ戻す
移行後によく出てくる質問: 「Wordしか開かない人にMarkdownをそのまま送れないとき、どうすれば?」それが逆変換です。Markdownの制約が小さいぶん変換すべき要素も少なく、こちらのほうがずっとクリーンに処理できます。詳細はMarkdown Word変換ガイドにまとめています。
両フォーマットを頻繁に行き来するチームで、うまく機能するワークフローはこうです: Gitの中のMarkdownを「正」とし、レビューや注釈が必要なときだけオンデマンドでWordにエクスポートする。Wordで編集したものをマージして戻すことは絶対にしない — そうしないと、せっかくの移行がじわじわ崩壊していきます。
おわりに
WordからMarkdownへの変換は、ボタン1つで終わる操作ではなく、1つの移行プロジェクトです。オンラインコンバーターは単発ファイル向け、Pandocはバッチ向け、Mammoth.jsはパイプライン向けと、ツールが重労働を引き受けてくれます。ただし本当の仕事は、変換前の検査と変換後のクリーンアップにあります。
最も時間を節約してくれる2つのパターン:
- まずトリアージ。 変換を始める前に、ソースアーカイブに何が入っているかを理解する。15分のサンプリングが、後で驚かされる何時間もを防ぎます。
- クリーンアップを見込んでおく。 1ドキュメントあたり5分のレビュー&仕上げパスを予算に入れる。避けられない工程として扱うことで、移行にかかる時間を現実的に見積もれます。
Markdownに馴染みがなくて出力がどう見えるのか気になる方は、Markdownとは何かと基本構文ガイドから始めるのがおすすめです。表・脚注・タスクリストといった高度な機能については、拡張構文リファレンスがGFMの対応範囲をカバーしています。
Wordではなく Obsidian からの移行なら、Obsidianエクスポートガイドが最初から最後までのフローをまとめています。