PDFをMarkdownに変換する方法 2026年版(無料・RAG対応)
2026年版・正しいPDFからMarkdownへの変換ガイド。無料オンラインツール、Pandoc、AI抽出器を徹底比較。RAG対応ワークフローとOCR対処法まで。

PDFから段落をコピペした瞬間に、改行が散乱し、ハイフンが分断され、書式が消し飛んで意味不明な文字列に化ける——そんな経験があれば、なぜ2026年にPDFからMarkdownへの変換が深刻なワークフロー課題になったのか、もう理解されているはずです。
PDFはドキュメント共有の共通通貨です。同時に、ソース形式としては最悪の部類に入ります。その中身をRAGパイプラインに流し込みたい、ドキュメントサイトに取り込みたい、ノートアプリに保管したい——そう思った瞬間、必要になるのは構造化されたテキスト、つまり見出しは見出しとして、表は表として、コードはコードとして扱われた状態です。
本ガイドでは、PDFをMarkdownに変換する3つの現実的なアプローチをご紹介します:インストール不要のオンラインコンバーター、コマンドラインのPandoc、そして新世代のAI抽出器であるmarkerやDoclingです。どの用途にどれを選ぶべきか、彼らが壊しがちなもの(表、数式、スキャンページ)をどう直すか、そして二度手間にならずにLLMパイプラインへ送り込む方法までを順に解説します。
なぜPDFをMarkdownに変換するのか
同じ変換ニーズが、3つの異なるコミュニティから繰り返し挙がっています。それぞれ動機は微妙に違うのですが、目指す出力形式は同じです。
RAGとLLMパイプラインにクリーンなテキストを供給する
検索拡張生成(RAG)パイプラインは、生のPDFテキストを好みません。ページ区切りのアーティファクト、2段組レイアウトが1列に潰れた結果、各ページに繰り返されるヘッダーとフッター——こうした要素はすべてベクトルデータベースにとってノイズとなり、検索品質を汚染します。
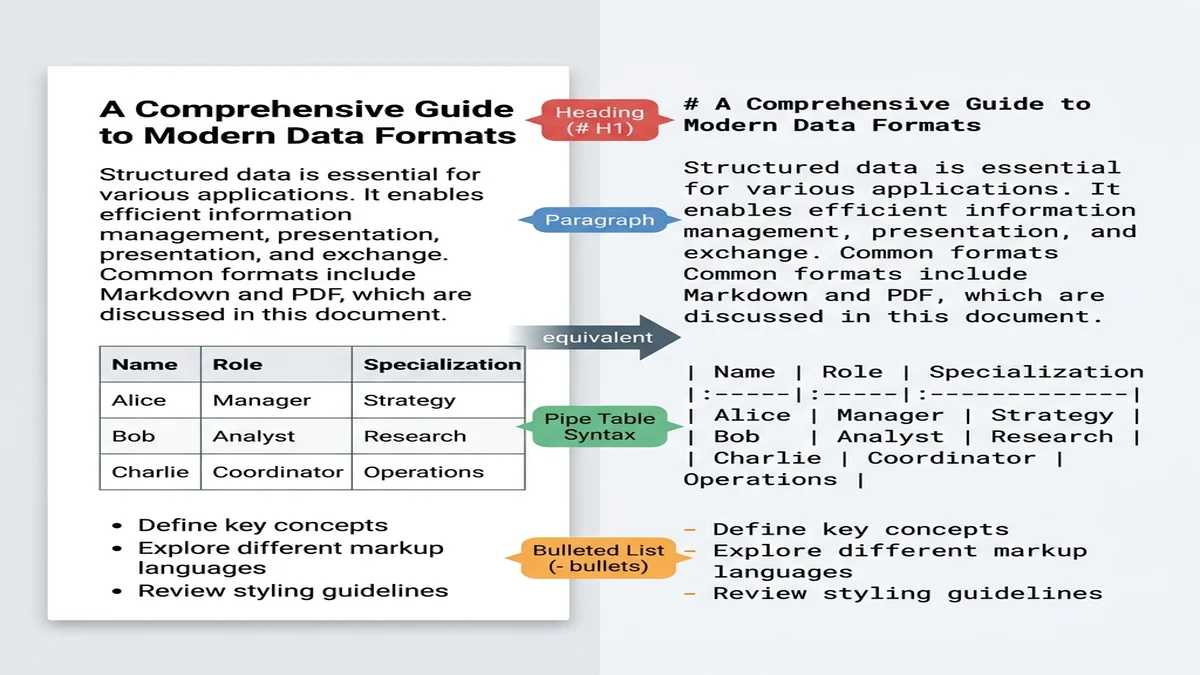
Markdownは、現実的な選択肢の中で「構造化されたプレーンテキスト」に最も近い形式です。Web上のデータで訓練された大規模モデルは、何十億ものMarkdownドキュメント(READMEファイル、Stack Overflowの回答、ブログ記事)に触れているため、特別な指示なしに#を見出しの区切り、|を表のセパレータとして認識してくれます。
レガシーPDFを現代的なドキュメントシステムへ移行する
Docusaurus、MkDocs、Astro Starlight、Hugo——いずれもMarkdownを要求します。チームが200本のレガシー社内資料をPDFで抱えているなら、コピペ大作戦は避けたいところです。必要なのは、見出し階層を保ったまま変換してくれるツールです。そうすればナビゲーションは自動で構築されます。
検索可能な「セカンドブレイン」を構築する
Obsidian、Logseq、Foam、Roam——現代のノートアプリはすべてMarkdownを話します。紙のアーカイブをデジタル化する研究者、議事録を蓄積するナレッジワーカー、文献ライブラリを整備する研究者、いずれも求めているものは同じです。見出しが保たれたクリーンなMarkdownファイルです。そうすれば後で数百のドキュメントを横断してgrepできます。
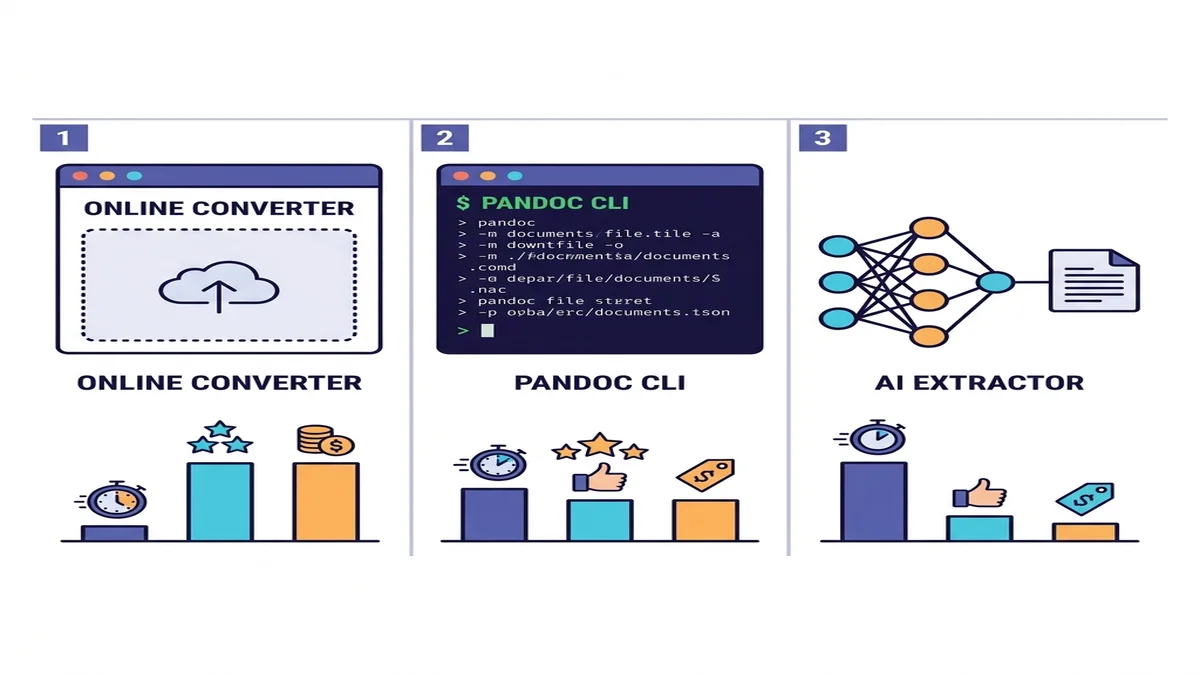
3つのアプローチ(使い分けの指針)
ツールは何十とありますが、本質的にはカテゴリは3つだけです。ご自身の状況に当てはまる行を選んでください。
| 手法 | 速度 | シンプルなPDF | 複雑なPDF | スキャン用OCR | 導入 |
|---|---|---|---|---|---|
| オンラインコンバーター | 速い | 優秀 | 良好 | 内蔵または自動 | 不要 |
| Pandoc + pdftotext | 速い | 良好 | 表は苦手 | 非対応 | CLIインストール |
| AI抽出器(marker / Docling) | 遅い | 優秀 | 優秀 | あり | Python + ML依存 |
迷ったら、まずはオンラインコンバーターから始めてください。試すのに1分もかかりませんし、単発や少量バッチの用途ならそれで完結することがほとんどです。プログラマティックなパイプラインや、密度の高い学術コンテンツが対象であれば、表の下の行へ進んでください。より広いツール群との比較は無料Markdownコンバーターのまとめ記事でご覧いただけます。
手法1:オンラインでPDFをMarkdownに変換する(無料・インストール不要)
最速の手段でありながら、ほとんどの人が「あまりに簡単すぎる」という理由で見過ごしてしまうアプローチです。議事録、記事、単章のレポートといった日常業務の圧倒的多数では、ブラウザベースのコンバーターで十分すぎるほどです。
そのままファイルを無料のPDF→Markdownコンバーターに投げ込めば、本セクションの残りは読み飛ばしていただいて構いません。
ステップごとのワークフロー
- PDFをアップロードエリアにドラッグ&ドロップ(クリックでファイル選択も可)。
- パーサーの処理を数秒待ちます。20ページ未満のファイルなら、この文章を二度読み終わる前に変換が完了します。
- 右側でソースとレンダリング結果を並べてプレビュー。
- ソースをコピーするか、
.mdファイルとしてダウンロード。
これだけです。アカウント登録もメール入力も、出力に透かしが入ることもありません。
こんなときに最適
- 何もインストールせず単発で変換したいとき。
- プログラマティックなパイプラインに投資する前のスポットチェックとして。
- 機密性の高いファイルを第三者APIに送りたくないとき。当サービスはファイルをメモリ上で処理し、即座に破棄します——永続ストレージはありません。
制約
オンラインコンバーター全般(当サービスに限らず)が抱える失敗パターンは2つあります。
1つ目は、非常に大きい、あるいは特殊なPDFです。埋め込みフォントと動的フォームを含む600ページのスキャン済み法務開示書類は、どんなツールでも「ドロップしてダウンロード」では済みません。該当する場合は、AI抽出器のセクションへ進んでください。
2つ目は、テキストレイヤーのないスキャンPDFです。抽出すべきテキストが存在せず、ページは単なる画像です。先にOCRが必要になります。後述の厄介なコンテンツへの対処をご覧ください。
手法2:コマンドラインでPandocを使う
Pandocはドキュメント変換のスイスアーミーナイフです。再現性のあるスクリプト化されたパイプラインが必要で、Webサービスに依存したくない場合に最適です。
ただし正直に言うと、Pandoc自体は強力なPDFリーダーを持っていません。コミュニティで広まっている流儀は、pdftotext(Popplerユーティリティの一部)を経由し、結果をPandocにパイプで渡す方法です。
# レイアウトを保ったままテキスト抽出し、GFM markdownに変換
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
メモや単段組の記事など、テキスト中心のシンプルなPDFであれば、このコンビは十分に機能し、ミリ秒単位で完了します。
忠実度が重要なとき
PDFがほぼ散文であれば、このパイプラインは段落構造を保ったクリーンなMarkdownファイルを生み出します。ハードラップを嫌う下流ツール向けに調整するなら、-Vと--wrap=noneフラグを追加してください。
Pandocが苦手なところ
- 多段組レイアウト(学術論文、雑誌):
pdftotextが列を入り混じらせ、読めない出力になります。 - 表:最も単純な2列の格子を超えると、たいていMarkdownのパイプではなくスペース区切りの列として出力されます。
- 数式とコードブロック:意味的な保持がなく、LaTeX数式はテキスト化し、等幅のコードは通常段落に化けます。
- スキャンPDF:完全に非対応——Pandoc/pdftotextは画像からテキストを抽出できません。
表に関しては、拡張Markdown構文ガイドで出力を合わせるべきGFM表形式を解説しています。
手法3:AI抽出器(marker、Docling、pymupdf4llm)
2024〜2025年に登場したレイアウト認識型抽出器は、可能性を一変させました。これらのツールは視覚的なレイアウト検出をOCRおよび構造化出力生成と組み合わせるため、この領域は表である、あちらは2段組の本文であると理解できます。複雑なPDFでは出力品質が劇的にクリーンになります。
押さえておきたいプロジェクトを3つご紹介します。
- marker —— surya(レイアウトモデル)とヒューリスティクスを併用。学術論文、数式、コードブロックに強い。Apache 2.0ライセンス。
- Docling —— IBM Research発。表の再構築が秀逸で、LlamaIndexとLangChainにネイティブで統合可能。MITライセンス。
- pymupdf4llm —— PyMuPDFを軽量にラップしたもの。他の2つより高速で、ML依存も少なく、LLM入力用に設計されています。
最小限のPython例
最も小さく実用的なDoclingパイプラインはこちらです。
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
より軽量なpymupdf4llmの場合はこうです。
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
トレードオフ
これらのツールはPandocパイプラインより遅いです。一般的なCPUノートPCでは、30ページの論文に数十秒かかると想定してください。GPUがあればmarkerは数秒まで縮まります。pymupdf4llmは重い視覚モデルをスキップする分、3つの中で最速です。
もう一つのトレードオフは依存関係の重さです。pip install marker-pdfはPyTorchと数百MBのモデルウェイトを引き込みます。コンテナで配布するなら、サイズをあらかじめ織り込んでおいてください。
厄介なコンテンツへの対処
きれいな2ページのメモで試している間は気づきませんが、現実世界のPDFを流し込み始めると、手法間の差が一気に表面化します。
崩れがちな表
表は多くのコンバーターが落とす関門です。pdftotext + Pandocルートは、ほぼ確実にスペース整列の「列スープ」を生成し、どのMarkdownレンダラーも正しく解釈できません。オンラインコンバーターとAI抽出器は、まず表領域を検出してからセルを再構築するため、ここではるかに優秀です。
コツは、信頼する前に最初の表出力をスポットチェックすること。最初の表が崩れていれば、残り50個も同じ運命です。
数式とLaTeXブロック
PDFに数式があるなら、数式領域を検出してMarkdownへ$$...$$ブロックとして出力できるツールが必要です。markerは対応し、Pandocは対応しません。科学技術文書において、AI抽出器の速度コストを払う最大の理由はここにあります。
コードブロックとインラインコード
多くのPDFはコードを等幅フォントで描画していますが、エクスポート時に「これはコードだ」という意味的タグを失います。AI抽出器は視覚的なスタイル——等幅フォントとインデント——からコード領域を再検出し、トリプルバッククォートで囲み直します。Pandocベースのパイプラインはコードを通常段落に押し戻してしまうのが一般的です。
脚注と引用
学術論文は番号付き脚注を用い、本文はページ下部に配置されています。pdftotextルートでは、参照マーカーと脚注本体のリンクが失われます。Doclingとmarkerはこれを適切なMarkdown脚注構文([^1]参照 + [^1]: 本文定義)として保持します。
スキャンPDF(OCR必須)
スキャンPDFはページの画像であり、テキストではありません。先にOCRを走らせない限り、抽出できるものは何もありません。

信頼できる3つの経路があります。
-
ocrmypdf —— スキャンPDFに不可視のOCRテキストレイヤーを付加し、見た目は変えません。レイヤーを付与した後は、どの下流コンバーターでも動作します。
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
OCRモード付きAI抽出器 —— markerとDoclingは、テキストレイヤーのないページを検知して自動でOCRを実行します。出力は統合されているため、中間PDFを挟まずに1つのMarkdownファイルが得られます。
-
自動OCR付きオンラインコンバーター —— 一部のブラウザツール(画像のみPDFに対しては当サービスも含む)は、ユーザーに見えない形でOCRを動かします。便利ですが、対象が英語でない場合は言語サポートを確認してください。
ちょっとした落とし穴:「ボーンデジタル」のPDF(スキャンではなくWord文書から作られたもの)であっても、フラット化された画像としてエクスポートされた場合はテキストレイヤーを欠くことがあります。まずはPDFビューア上でテキストを選択できるか確認してください。選択できればOCRは不要、できなければ実行します。
RAG / LLM入力に向けてMarkdownを整える
行き先がベクトルデータベースであれば、変換時のちょっとした選択が、下流での検索品質に目に見える差を生みます。
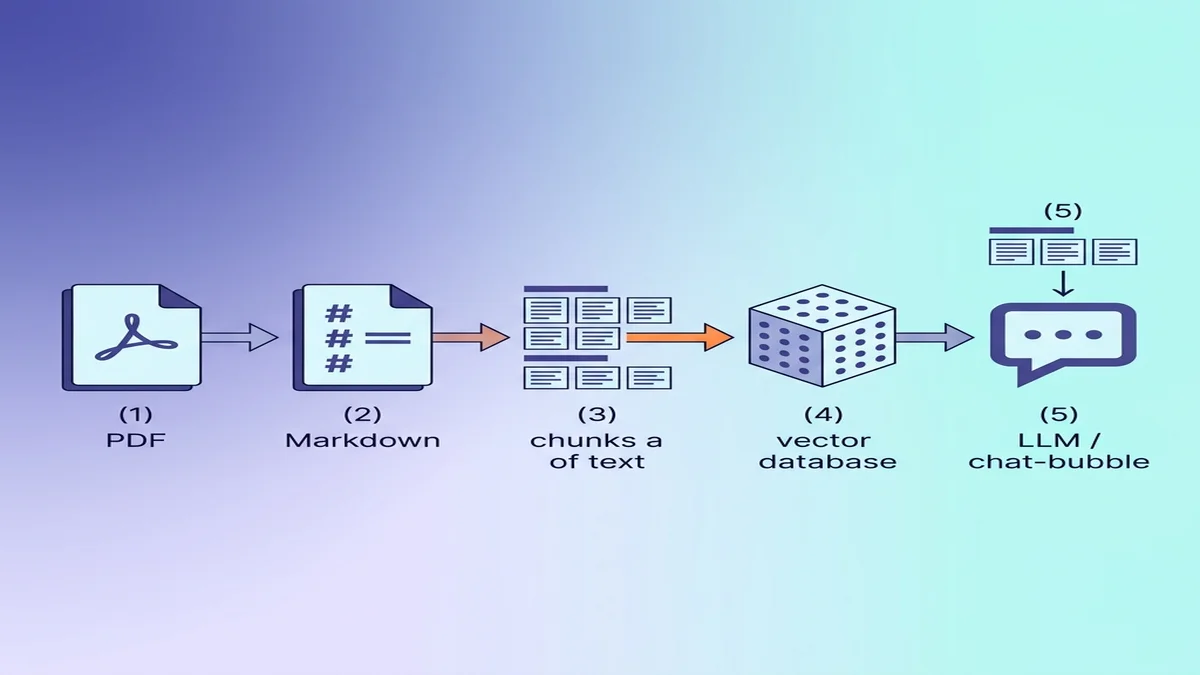
なぜLLMにとってMarkdownはプレーンテキストより優れているのか
Markdownは、プレーンテキストでは失われる構造情報を運びます。## Methodsを読んだモデルは新しいセクションに入ったと認識します。同じ内容を全フォーマット剥ぎ取った状態で読ませると、すべての段落が等しい重みに見えてしまいます。構文に馴染みがなければ、基本Markdownガイドを5分で読めます。
見出し階層によるチャンキング
RAGで最もよくある失敗は、固定サイズのチャンキング——構造を無視して500トークンずつ分割するやり方です。Markdownなら意味的にチャンキングできます。## H2の境界で分割すれば、段落途中の断片ではなく一貫したセクションが得られます。
# 粗いチャンク:H2で分割
sections = markdown.split("\n## ")
# 各セクションがセクションヘッダーから始まり、その配下のサブツリーを含む
さらに望ましいのは、見出しを木構造として歩き、各H3を親H2のチャンクメタデータに紐づけることです。
frontmatterでメタデータを保持する
変換ごとに、ファイル冒頭へYAML frontmatterを追加してください。これでソース情報が各チャンクと一緒に旅をします。
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
LLMがチャンクを取得した際、このメタデータが引用フッターになります。「この主張はどこから来た?」という問いに、検索を再実行せず答えるための仕組みでもあります。同種のパイプラインをチャットのエクスポートから構築する場合、ChatGPT/Claudeのトランスクリプトにも同じ考え方が適用できます。
よくある落とし穴と回避策
初めて取り組む方が引っかかりがちなポイントがいくつかあります。
- エンコーディング正規化をスキップする。 PDFはUnicodeの小技を好みます。リガチャ(
fi、fl)、スマートクォート("と")、ハイフンのように見えるemダッシュなど。下流に投入する前に、Unicode正規化(Pythonの場合はNFKC)を一度かけてください。 - ページのヘッダーとフッターを残したまま。 全ページに出てくる「Page 4 of 12」フッターは、検索におけるノイズです。一定の間隔で繰り返される行は除去しましょう。
- 最初の表を鵜呑みにする。 残りも大丈夫だと判断する前に、少なくとも最初の2つはスポットチェックしてください。
- 「ボーンデジタル」=「テキストレイヤーあり」と決めつける。 元はWord文書でも、フラット化された画像としてエクスポートされたPDFがあります。必ず最初にテキストを選択してみてください。
- 小さなドキュメントを過剰にチャンクする。 3ページのメモなら、Markdown全体をそのままモデルに渡し、RAGステップは丸ごとスキップしましょう。コンテキストウィンドウ > ドキュメントなら検索は過剰です。
FAQ
最高の無料PDF→Markdownコンバーターはどれですか?
多くの方にとっては、オンラインコンバーターが最速です。ドラッグ、ドロップ、完了。バッチ処理やプログラマティックな用途には、pymupdf4llm(Python)とPandoc(CLI)がシンプルなケースをカバーします。表や数式を含む学術論文には、markerとDoclingが目に見えて優れた出力を返します。「最高」の選択は、セットアップ時間と出力忠実度のどちらを優先するかで変わります。
ChatGPTやClaudeはPDFをMarkdownに変換できますか?
できますが、留意点があります。両者ともPDFを直接読み込んでMarkdown出力を返せますが、長文だとコンテキスト制限に当たることがあり、表や数式の精度は実行ごとにブレます。決定論的なバッチ変換には専用コンバーターのほうが信頼できます。関連する往復ワークフローについてはChatGPTからWord/PDF/HTMLへのエクスポートをご覧ください。
スキャンPDFをMarkdownに変換するにはどうしますか?
まずOCRを走らせます。最もきれいな経路は、ocrmypdfでテキストレイヤーを付加し、その後はどんなコンバーターでもOCR済みPDFを処理できる、という流れです。あるいは、markerとDoclingはOCRを内蔵しており、画像のみのPDFから直接Markdownを生成します。
オンラインのPDF→Markdown変換はプライベートですか?
当サービスでは、ファイルはメモリ上で処理され、変換後に破棄されます——アカウント不要、永続ストレージなし。他のサービスは様々です。機密文書を扱う際は、必ず利用するツールのプライバシーポリシーをご確認ください。
PDFをMarkdownに変換するとき、表を崩さずに保つには?
表が多いPDFにはpdftotext + Pandocパイプラインを使わないでください——ほぼ確実に崩れます。GFM表を出力するオンラインコンバーターを使うか、markerやDoclingのようなAI抽出器を使ってください。どちらにしても、最初の数個の表はスポットチェックしましょう。
元のPDFとMarkdown、どちらを保管すべきですか?
両方を残してください。Markdownは取り込み、検索、編集のためのもの。PDFは引用と監査のための「信頼できる原本」です。MarkdownのfrontmatterにPDFのファイル名とページ範囲を記録しておけば、いつでも主張をソースまで辿れます。
最初のPDFを変換してみませんか
結果さえ欲しいという場合は、無料のPDF→Markdownコンバーターが登録不要で日常的なケースを処理します。次のステップ——そのMarkdownを洗練されたWord文書や共有可能なPDFに仕上げる方法——はMarkdown→Wordガイドをご覧ください。
References
- Pandoc User's Guide —— CLI変換の正典リファレンス。
- GitHub Flavored Markdown Spec —— 本ガイドが出力先として狙う方言。
- Docling (IBM Research) —— レイアウト認識型のオープンソースPDF抽出器。
- marker —— 学術論文に強いオープンソースのPDF→Markdownツール。
- pymupdf4llm —— PyMuPDFを軽量にラップしたMarkdown抽出器。
- OCRmyPDF —— スキャンPDFに検索可能なテキストレイヤーを付加。