Word 转 Markdown 完整迁移指南:三种方法实测对比
把 Word 文档批量转成干净的 Markdown,接入 Git 工作流或 Obsidian 知识库。实测过的三种方法,覆盖表格、列表、图片嵌入的常见坑和修复方案。

每次接到这种需求,开头都差不多:"能不能把这些 Word 文档搬到团队 wiki 里?"
打开共享盘一看:三百个 .docx 文件,十年积累下来的内部文档——制度、操作手册、会议纪要、技术规格——散落在命名混乱的文件夹里。Git 差异看不出来,全文搜索用不上。然后某个领导拍板,这些东西季度结束前必须全部进 Git 仓库,用 Markdown 管理。
这种迁移我做过两次。一次是合规档案(大约 200 个文件),一次是工程知识库(大约 500 个文件)。两次得出的结论都一样:Word 转 Markdown 不是一键搞定的事。它是一条流水线——转换、检查、清理——而真正吃时间的是清理这一步。
这篇指南讲的是实际能用的东西:三种值得掌握的转换方法、哪些 Word 特性能活下来(哪些会悄无声息地丢掉),以及能帮你省下几小时手工修复时间的转换后清理清单。
为什么要把 Word 文档迁到 Markdown
先讲"为什么"再讲"怎么做"。因为如果团队没把迁移的理由说清楚,这事儿推到一半就散了。
- 可 Diff 的历史记录。 Word 的
.docx本质上是压缩过的 XML 包。两个版本在 Git 眼里就是两坨随机二进制。Markdown 是纯文本——每一次改动都是人能读懂的 diff。 - 搜索和 grep。
rg "incident response" docs/在几千个 Markdown 文件里毫秒级返回结果。同样的事在 Word 文档堆里做,得靠专门的检索工具。 - 自动化。 Markdown 可以被静态站点生成器、文档工具(Docusaurus、MkDocs、Nextra)、LLM 数据管道、CI 系统、Linter 等消费。Word 基本上只能被 Word 消费。
- 长期可读性。 纯文本文件比任何软件厂商活得都久。DOCX 今天还算稳定,但老版
.doc二进制格式的兼容性前景已经开始模糊了。
如果上面这几点对你团队都不成立,那其实没必要迁。只要有一条成立,你就看对地方了。
哪些内容能活下来,哪些活不下来
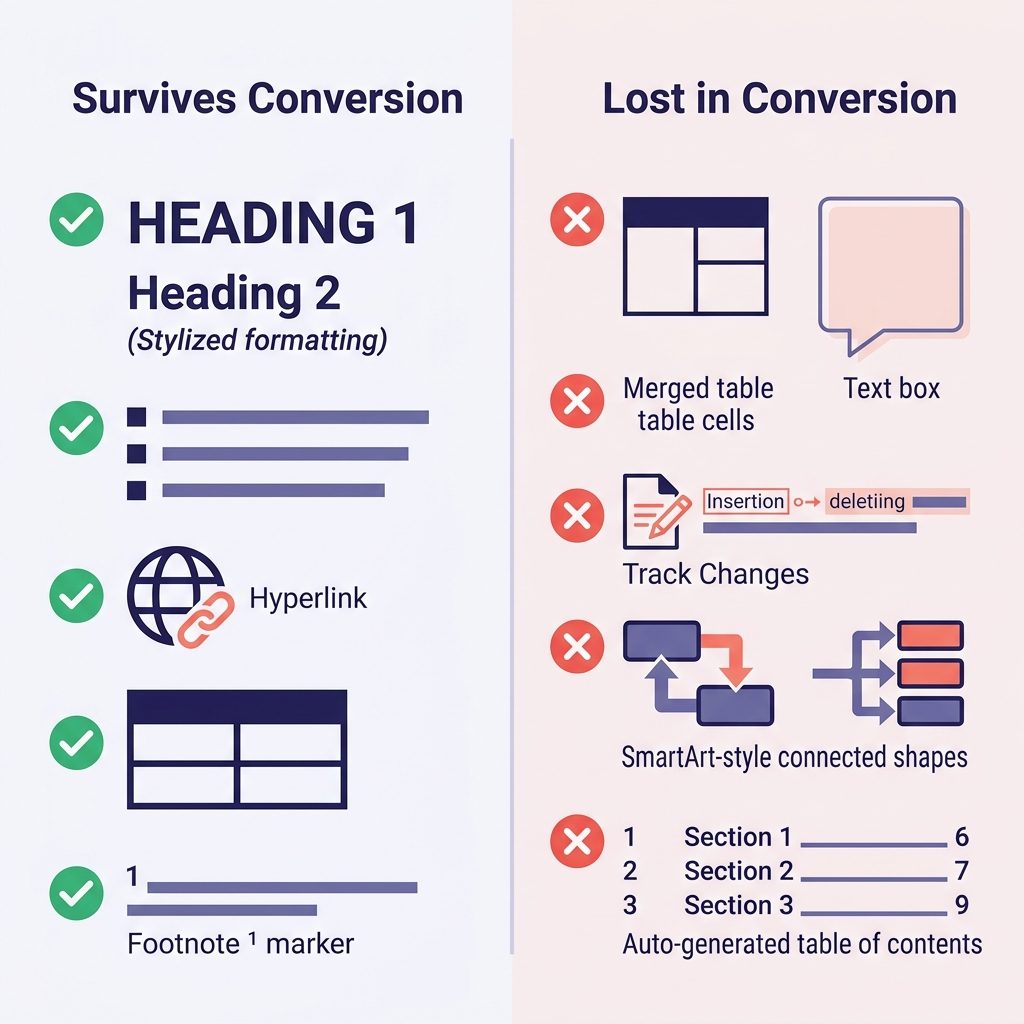
把预期提前对齐,能省下最多的时间。这是我自己做过几百次转换后观察到的规律:
| Word 特性 | 能保留吗 | 说明 |
|---|---|---|
| 标题(Heading 1–6 样式) | 能 | 直接映射到 # 到 ###### |
| 加粗、斜体、下划线(Bold、Italic、Underline) | 加粗和斜体可以 | 下划线 Markdown 没有对应语法,通常变成斜体或者 HTML <u> |
| 无序列表和有序列表(Bulleted and numbered lists) | 大多数情况可以 | 深层嵌套有时会被压平 |
| 超链接(Hyperlinks) | 能 | URL 和锚文本都会保留 |
| 表格(Tables) | 简单表格可以 | 合并单元格、单元格颜色、边框都会丢 |
| 内嵌图片(Inline images) | 能 | 会被抽到文件夹里,链接也会自动改写 |
| 脚注(Footnotes) | 能(GFM 支持) | 转换成 [^1] 语法 |
代码(如果用了 Code 段落样式) | 看情况 | 经常会被压平成纯文本,不带代码围栏 |
| 数学公式(Math equations) | 部分支持 | 有时能转成 LaTeX,有时会被压平 |
| 修订记录(Track Changes) | 不行 | 转换前先全部接受或拒绝 |
| 批注(Comments) | 不行 | 转换前先解决或单独导出 |
| 文本框、SmartArt、形状 | 不行 | 整个丢失——转换前先替换成图片或纯文本 |
| 自动生成的目录(Table of Contents) | 不行 | 到新文档系统里重新生成 |
| Word 域(日期、交叉引用) | 不行 | 导出前转成纯文本 |
迁移时最容易踩的两个坑:一是看起来像标题但其实是手工加粗加大号字体——这些会变成普通粗体,输出文档就完全没有层级结构;二是带合并单元格的表格,它们会以非常难看的方式塌缩,需要手动重建。
开始批量转换之前,随便抽十个源文档扫一遍,把这类问题标记出来。只要花三十分钟,能省下后面大量返工。
方法一:在线转换器
单文件和小批量(50 个以内)我推荐这个。从 .docx 到干净的 Markdown,零配置、最快。
- 打开我们的 Word 转 Markdown 转换器
- 把
.docx文件拖到上传区 - 预览转换后的 Markdown
- 下载
.md文件(如果有图片会单独打包)
输出格式用的是 GitHub Flavored Markdown(GFM),所以表格、任务列表、脚注都能保留。标题自动映射到对应的 # 级别,列表层级保持,超链接的锚文本也不会丢。
顺带提一句:标准文档的转换全部在浏览器里完成。对于特别大的文件或者涉及敏感内容的场景,文件不出外部服务器这件事是实打实的优势,不只是营销话术。
任何在线转换器(我们的也好,别家的也好)都有共同的短板:不适合批量,没法脚本化接到流水线里。这两种需求请直接跳到方法二。
方法二:Pandoc(适合批量和脚本)
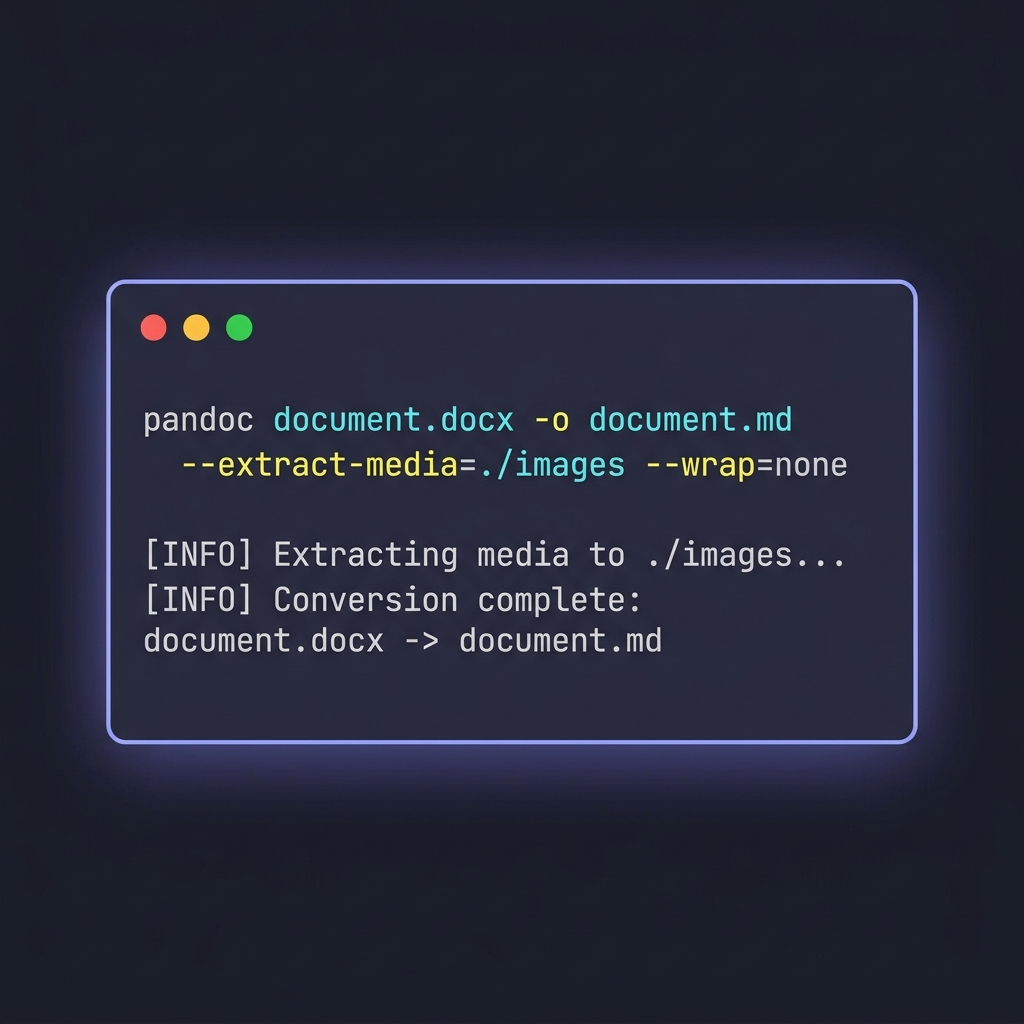
Pandoc 是万能的文档转换工具。一旦文件数量超过一把之数,或者我需要精细调整输出,就会用它。
基础命令
pandoc document.docx -o document.md
单文件转换就这么一行。速度很快,输出也挺干净,大部分常见 Word 特性开箱即用。但 Pandoc 的真正价值在于那些参数。
三个值得记住的参数
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images——把 DOCX 里内嵌的图片抽出来放到文件夹里,同时改写输出里的图片链接。不加这个参数,内嵌图片会被悄无声息地丢掉。--wrap=none——阻止 Pandoc 在大约 80 个字符处硬换行。这个很重要,硬换行会让以正文为主的文档 Git diff 非常难读。--markdown-headings=atx——强制使用# 标题语法,不用老式的 setext 风格(用====在标题下划线)。ATX 才是现代惯例。
批量转换整个文件夹
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
写成 shell 脚本丢进去跑,几百个文件几分钟就能处理完。档案更大的话,加个 trap 和日志,中途崩了也能续跑。
实际会碰到的小坑
- 列表符号不统一。 Pandoc 有时候用
-,有时候用*。如果你在乎一致性,拿sed -i 's/^\* /- /g'过一遍输出,或者让编辑器的 Markdown 格式化插件处理。 - 有序列表莫名其妙重新计数。 Word 里常有"继续编号"这种指令 Pandoc 读不懂。你会看到原本连续的列表在输出里变成
1, 2, 1, 2, 3。人工扫一遍能修掉。 - 长内容单元格表格排版崩坏。 Pandoc 尽力了,但 GFM 表格不像 Word 那样支持单元格内换行。特别复杂的表格可以考虑手动改成 HTML block。
Pandoc 没有图形界面,这既是缺点(非技术同事跑不动)也是优点(能无缝接入任何 CI/CD 流水线)。
方法三:用 Mammoth.js 做程序化转换
如果你要做的是一整条流水线——比如从 SharePoint 拉 DOCX、转换、提交到 Git 的迁移脚本——网页 UI 和 Pandoc 子进程调用可能都不合你的技术栈。Mammoth.js 是一个 JavaScript 库,直接在 Node.js 里把 DOCX 转成干净的 HTML 或 Markdown。
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // 转换后的 Markdown
console.log(result.messages); // 不支持特性的告警
});
Mammoth 有意思的地方在于它有自己的立场:完全无视 Word 的视觉样式,只关心语义结构(标题、列表、表格)。默认输出比 Pandoc 更干净,代价是可调整的空间更小。迁移结构统一的历史档案,我会选 Mammoth;对于格式花样百出的文档,还是 Pandoc 的灵活性更胜一筹。
Python 阵营里可以用 python-docx 配一个 Markdown writer 实现类似效果,不过这更像是 DIY 路线,不是开箱即用的工具。
没人提醒你的清理环节

转换能把你带到"有一个 .md 文件"。但到不了"有一个你愿意提交到仓库的 .md 文件"。
这是我标准的转换后清理清单。熟练之后每个文档大概花五分钟:
- 扫一遍漏掉的标题结构。 在输出里搜索那种单独一行的
**粗体文字**——这些本来是标题,但作者在 Word 里是手工加粗而不是用标题样式做的。把它们提升成真正的##标题。 - 检查第一个表格。 第一个表格看着正常,后面大概率也都正常。第一个崩了,基本全崩。
- 删掉列表项里的空行。 Pandoc 有时会插空行,把列表的连续性打断。
- 验证图片链接。 用 Markdown 预览打开文件(VS Code 自带的就行),确认图片能加载。
- 搜残留伪影。 常见的有:行尾的
\(Word 藏起来但 Markdown 会显示的硬换行)、{.underline}样式属性、漏网的<span>标签。 - 检查前后各 10 行。 Word 的页眉、页脚、页码经常会漏到输出里,表现为空内容或者奇怪的伪影。
大规模迁移可以把第 5、6 项做成清理脚本自动处理。其他几项还是需要人眼过——至少要做到对某一类文档的模式足够熟悉,能信任输出为止。
实战案例:200 文件合规档案迁移
下面是我做合规档案迁移时用的工作流。从头到尾两天做完,200 个文件。
第一天上午:源文档分类
写了个 Python 脚本,逐个打开 DOCX,统计标题数、图片数、表格数,标记出还带着修订记录或批注的文件。输出是一张按复杂度排序的 CSV。这一步不修任何东西——只是摸清楚接下来要面对什么。
第一天下午:批量转换简单文件
200 个里大约有 140 个文件属于简单型:没图、简单表格、标题结构干净。丢进 Pandoc 循环里跑,加上 --extract-media 和 --wrap=none。随机抽 20 个看结果,全部通过。
第二天上午:逐个处理复杂文件
剩下 60 个有各种问题——合并单元格、内嵌电子表格对象、或者一堆还没处理的修订记录需要有人先过一遍。这些我就一个一个用在线转换器处理,有时候换不同的 Pandoc 参数跑,有时候先清理源 DOCX 再转。
第二天下午:清理和提交
对全部 200 个转换好的文件跑了一遍清理脚本(去 {.underline} 伪影、统一列表符号、修掉 Pandoc 的换行输出)。看 diff、每 50 个文件一批提交 commit、推到迁移分支。
如果尝试纯手工做——挨个打开 Word 粘到 Markdown 编辑器里——少说得花两周。这种转换工具不是可选项,是让项目变得可行的前提。
常见问题与修复方案
Markdown 预览里表格看起来不对
九成情况是源文档有合并单元格或者特别长的单元格内容。GFM 表格两样都不擅长处理。三个选择:手动用 GFM 重建表格、在 Markdown 里塞一个 HTML <table> 块(大多数渲染器都支持)、或者把一个大表拆成几个简单表格。
图片没显示出来
先看转换器有没有把图片抽出来。Pandoc 不加 --extract-media 就不会抽。在线转换器一般会下载一个 zip,里面有 Markdown 文件加一个 images/ 文件夹——确认两样东西都放到正确位置,Markdown 里的图片路径对得上。
输出里行尾有奇怪的反斜杠
那是 Word 里的硬换行,Markdown 把它渲染成强制换行。如果源 Word 文档喜欢用行距不够时用换行代替段落间距,Pandoc 会原样保留。查找替换 \\$(行尾的反斜杠)通常就能清掉。
转换后标题级别不对
Word 文档经常是从 Heading 2 或 Heading 3 开头的(因为 Heading 1 留给封面标题)。Markdown 的惯例是从 #(H1)起步。根据你的文档系统怎么展示标题层级,可能需要把所有级别上移一级。sed 能搞定:sed -i 's/^## /# /; s/^### /## /; ...' file.md。
Markdown 的视觉效果跟 Word 差别很大
这是正常现象。Markdown 描述的是结构,不是外观。样式由渲染 Markdown 的系统决定(GitHub、你的文档站、MkDocs 主题等)。如果视觉还原度是硬需求,PDF 才是正确目标——看我们的 Markdown 转 PDF 指南,里面讲了怎么保留视觉设计。
反向往返:Markdown 转回 Word
迁移完一个很自然的问题:"如果我要把 Markdown 文档发给一个只用 Word 的甲方怎么办?"那就是反向转换——操作反而更干净,因为 Markdown 限制少,需要翻译的东西也更少。Markdown 转 Word 指南讲了这条链路。
对于频繁在两种格式之间切换的团队,我见过跑得通的工作流是:Markdown 是 Git 里的唯一真相,Word 只在有人要审阅或批注时按需导出。永远不要在 Word 里编辑再合并回来——这是避免迁移成果被慢慢腐蚀的关键。
收尾
Word 转 Markdown 是一次迁移,不是按一下按钮的事。工具把重活都包了——在线转换器适合零散文件、Pandoc 适合批量、Mammoth.js 适合流水线——但真正的工作是转换前的摸底和转换后的清理。
最省时间的两条模式:
- 先分类。 开始转之前,先搞清楚你的源档案里都装了些什么。花十五分钟抽样,避免后面几小时被各种意外拖进坑里。
- 预留清理时间。 每个文档留五分钟做审阅和打磨。把清理当成无法回避的一步来看待,才能诚实估算迁移到底要花多久。
如果你对 Markdown 还比较陌生、想先了解输出大概长什么样,可以先看什么是 Markdown 和 Markdown 基础语法指南。进阶特性——表格、脚注、任务列表——看 Markdown 扩展语法参考,里面覆盖了 GFM 支持的全部内容。
如果你的迁移源头是 Obsidian 而不是 Word,Obsidian 导出指南从头到尾讲了那条链路。