Cách chuyển PDF sang Markdown năm 2026 (Miễn phí + Sẵn sàng cho RAG)
Chuyển PDF sang Markdown đúng cách năm 2026. So sánh công cụ online miễn phí, Pandoc và bộ trích xuất AI — kèm quy trình sẵn sàng cho RAG và cách xử lý OCR.

Nếu bạn từng copy-paste một đoạn từ PDF rồi nhìn nó nổ tung thành mớ ngắt dòng lung tung, gạch nối bị vỡ và mất hết định dạng, bạn đã hiểu vì sao chuyển PDF sang Markdown trở thành một bài toán quy trình nghiêm túc trong năm 2026.
PDF là đồng tiền chung để chia sẻ tài liệu. Nhưng cũng là một định dạng nguồn tệ hại. Khoảnh khắc bạn muốn nạp nội dung đó vào một pipeline RAG, đẩy nó vào trang tài liệu, hay đơn giản là lưu trong app ghi chú, bạn cần văn bản có cấu trúc — tiêu đề ra tiêu đề, bảng ra bảng, code ra code.
Hướng dẫn này đi qua ba cách thẳng thắn để chuyển PDF sang Markdown: một trình chuyển online không cần cài đặt, Pandoc trên dòng lệnh, và làn sóng mới của các bộ trích xuất chạy AI như marker và Docling. Tôi sẽ chỉ bạn chọn loại nào cho việc nào, cách sửa những thứ chúng làm hỏng (bảng, công thức, trang scan), và cách đưa đầu ra vào pipeline LLM mà không phải dọn dẹp tới hai lần.
Vì sao phải chuyển PDF sang Markdown?
Cùng một bài toán chuyển đổi xuất hiện ở ba cộng đồng khác nhau. Mỗi nhóm có một lý do hơi khác nhau, nhưng định dạng đích thì giống nhau.
Cấp văn bản sạch cho pipeline RAG và LLM
Pipeline retrieval-augmented generation không thích văn bản PDF thô. Mảnh vụn từ ngắt trang, bố cục hai cột bị nén thành một cột, header và footer lặp lại trên mọi trang — tất cả trở thành nhiễu trong vector database và làm bẩn quá trình truy hồi.
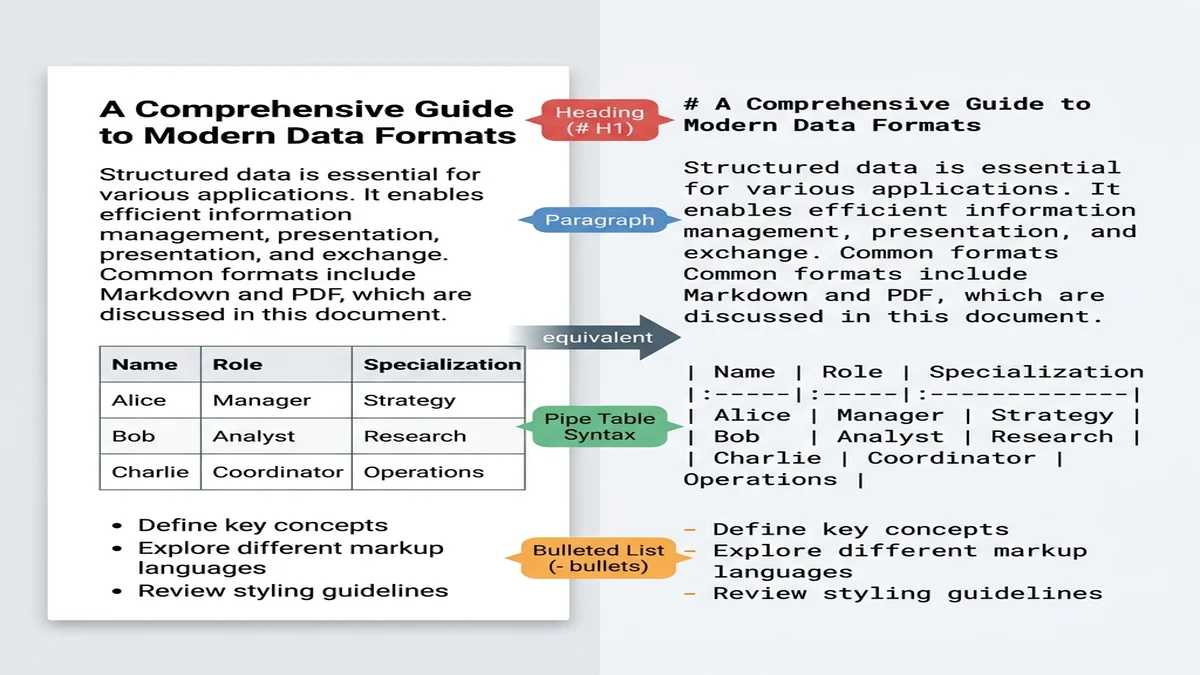
Markdown gần với "văn bản thuần có cấu trúc" hơn bất kỳ định dạng thực dụng nào khác. Các mô hình lớn được huấn luyện trên dữ liệu web đã thấy hàng tỉ tài liệu Markdown (file README, câu trả lời Stack Overflow, bài blog), nên chúng nhận ra tiêu đề # như ranh giới mục và pipe | như dấu phân cách bảng mà không cần gợi ý.
Di chuyển PDF cũ sang hệ tài liệu hiện đại
Docusaurus, MkDocs, Astro Starlight và Hugo đều muốn Markdown. Nếu đội của bạn có 200 PDF tài liệu nội bộ kế thừa, bạn không muốn một đội quân copy-paste — bạn muốn một trình chuyển đổi bảo toàn thứ bậc tiêu đề để điều hướng tự dựng được.
Xây dựng bộ não thứ hai có thể tìm kiếm
Obsidian, Logseq, Foam, Roam — mọi app ghi chú hiện đại đều nói Markdown. Nhà nghiên cứu số hoá kho giấy tờ, người làm tri thức lưu báo cáo họp, và người làm khoa học dựng thư viện tài liệu đều cần cùng một thứ: một file Markdown sạch với tiêu đề còn nguyên vẹn, để có thể grep qua hàng trăm tài liệu sau này.
Ba cách tiếp cận (Khi nào dùng cái nào)
Có hàng tá công cụ, nhưng thật ra chỉ có ba nhóm. Chọn hàng phù hợp với tình huống của bạn.
| Phương pháp | Tốc độ | PDF đơn giản | PDF phức tạp | OCR cho bản scan | Cài đặt |
|---|---|---|---|---|---|
| Trình chuyển online | Nhanh | Xuất sắc | Tốt | Tích hợp sẵn hoặc tự động | Không cần |
| Pandoc + pdftotext | Nhanh | Tốt | Trung bình với bảng | Không | Cài CLI |
| Bộ trích xuất AI (marker / Docling) | Chậm | Xuất sắc | Xuất sắc | Có | Python + dependency ML |
Nếu bạn chưa biết chọn cái nào, hãy bắt đầu với trình chuyển online. Mất một phút để thử, và với phần lớn công việc một lần hoặc lô nhỏ, câu chuyện kết thúc ở đó. Với pipeline lập trình hoặc nội dung học thuật dày đặc, lùi xuống một hàng. Chúng tôi so sánh bức tranh rộng hơn trong bài tổng hợp các trình chuyển Markdown miễn phí.
Cách 1: Chuyển PDF sang Markdown online (Miễn phí, không cần cài)
Con đường nhanh nhất cũng là con đường nhiều người bỏ qua vì nó có vẻ quá đơn giản. Với phần lớn công việc hằng ngày — biên bản họp, bài viết, báo cáo một chương — một trình chuyển chạy trên trình duyệt là quá đủ.
Bạn có thể thả thẳng file vào trình chuyển PDF sang Markdown miễn phí của chúng tôi và bỏ qua phần còn lại của mục này.
Quy trình từng bước
- Kéo thả PDF vào vùng upload (hoặc bấm để chọn file).
- Đợi vài giây cho parser hoàn tất. Bất kỳ tài liệu dưới 20 trang nào thường chuyển xong trước khi bạn đọc xong câu này hai lần.
- Xem trước Markdown đã render cạnh mã nguồn ở bên phải.
- Copy mã nguồn, hoặc tải file
.md.
Hết. Không cần tài khoản, không cần điền email, không có watermark trên đầu ra.
Khi nào dùng phương án này tốt nhất
- Chuyển một lần khi bạn không muốn cài bất cứ thứ gì.
- Kiểm tra nhanh trước khi quyết định đầu tư vào pipeline lập trình.
- File nhạy cảm về quyền riêng tư mà bạn không muốn đẩy lên API bên thứ ba. Trình chuyển của chúng tôi xử lý file trong bộ nhớ và xoá ngay — không lưu trữ lâu dài.
Hạn chế
Trình chuyển online nói chung (không chỉ của chúng tôi) có hai kiểu thất bại đáng biết.
Thứ nhất là PDF rất lớn hoặc khác thường. Một file công bố pháp lý dày 600 trang đã scan, font nhúng, có trường form động không phải là kịch bản "thả và tải" cho bất kỳ công cụ nào. Nếu bạn có một file như vậy, hãy nhảy xuống phần bộ trích xuất AI.
Thứ hai là PDF scan không có lớp văn bản. Không có văn bản để trích xuất — trang chỉ là một ảnh. Bạn cần OCR trước; xem Xử lý nội dung khó nhằn ở dưới.
Cách 2: Pandoc trên dòng lệnh
Pandoc là con dao Thuỵ Sĩ của ngành chuyển đổi tài liệu. Đây là công cụ phù hợp khi bạn cần một pipeline lặp lại được, viết script được, và bạn không muốn phụ thuộc vào dịch vụ web.
Điều thẳng thắn cần biết: bản thân Pandoc không có một trình đọc PDF mạnh. Quy trình của cộng đồng đi qua pdftotext (từ bộ Poppler utilities) và đưa kết quả vào Pandoc.
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
Với một PDF đơn giản nhiều chữ — memo, bài viết một cột — combo này hoạt động tốt và chạy trong vài mili giây.
Khi độ trung thực quan trọng
Nếu PDF của bạn chủ yếu là văn xuôi, pipeline này cho bạn một file Markdown sạch với cấu trúc đoạn còn nguyên. Thêm cờ -V và --wrap=none để chỉnh đầu ra cho các công cụ phía sau không thích các dòng bị wrap cứng.
Pandoc gặp khó ở đâu
- Bố cục nhiều cột (bài báo khoa học, tạp chí):
pdftotextxen kẽ các cột và bạn nhận được đầu ra không đọc nổi. - Bảng: bất cứ thứ gì vượt quá lưới hai cột đơn giản nhất thường đến dưới dạng các cột cách nhau bằng khoảng trắng thay vì pipe Markdown.
- Công thức và khối code: không có bảo toàn ngữ nghĩa; phương trình LaTeX trở thành chữ thường, và code monospace trở thành đoạn văn bản thường.
- PDF scan: hỗ trợ bằng không — Pandoc/pdftotext không thể trích xuất văn bản từ ảnh.
Riêng về bảng, hướng dẫn cú pháp Markdown mở rộng của chúng tôi nói về định dạng bảng GFM mà bạn sẽ muốn đầu ra của mình khớp với.
Cách 3: Trích xuất bằng AI (marker, Docling, pymupdf4llm)
Làn sóng bộ trích xuất nhận biết bố cục năm 2024-2025 đã thay đổi giới hạn khả năng. Các công cụ này kết hợp phát hiện bố cục bằng thị giác với OCR và sinh đầu ra có cấu trúc, nên chúng hiểu rằng vùng này là một bảng và vùng kia là phần thân hai cột. Đầu ra trên PDF phức tạp sạch hơn rõ rệt.
Ba dự án đáng biết:
- marker — dùng surya (một mô hình bố cục) cộng với heuristic. Mạnh ở bài báo khoa học, công thức và khối code. Apache 2.0.
- Docling — từ IBM Research. Tái dựng bảng xuất sắc, cắm vào LlamaIndex và LangChain một cách tự nhiên. Cấp phép MIT.
- pymupdf4llm — wrapper gọn nhẹ quanh PyMuPDF. Nhanh hơn hai cái còn lại, ít phụ thuộc ML, thiết kế chuyên biệt cho việc nạp vào LLM.
Một ví dụ Python tối giản
Đây là pipeline Docling nhỏ nhất mà vẫn hữu ích:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
Hoặc với pymupdf4llm cho con đường nhẹ ký hơn:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
Đánh đổi
Các công cụ này chậm hơn pipeline Pandoc. Trên một laptop CPU thông thường, hãy chuẩn bị tinh thần một bài báo 30 trang mất hàng chục giây thay vì mili giây; với GPU, con số đó giảm về vài giây với marker. pymupdf4llm là nhanh nhất trong ba vì nó bỏ qua các mô hình thị giác nặng.
Đánh đổi còn lại là khối lượng dependency. Một lệnh pip install marker-pdf kéo theo PyTorch và vài trăm megabyte trọng số mô hình. Nếu bạn đóng gói trong container, hãy tính trước dung lượng.
Xử lý nội dung khó nhằn
Khác biệt giữa các phương pháp lộ ra rõ khi bạn ngưng thử nghiệm trên memo hai trang sạch sẽ và bắt đầu cho PDF đời thực chạy qua chúng.
Bảng không sống sót
Bảng là chỗ phần lớn trình chuyển thất bại. Con đường pdftotext + Pandoc gần như luôn cho ra một mớ cột canh bằng khoảng trắng mà không trình render Markdown nào parse đúng. Trình chuyển online và bộ trích xuất AI làm tốt hơn nhiều ở đây vì chúng phát hiện vùng bảng trước rồi mới tái dựng các ô.
Mẹo: kiểm thử thật kỹ bảng đầu tiên trước khi tin phần còn lại. Nếu bảng đầu tiên bị méo, 50 cái còn lại cũng vậy.
Phương trình toán và khối LaTeX
Nếu PDF của bạn có phương trình, bạn cần một công cụ phát hiện vùng công thức và xuất ra khối LaTeX ($$...$$) trong Markdown. marker làm được; Pandoc thì không. Với viết khoa học, đây là lý do lớn nhất để chấp nhận chi phí tốc độ của bộ trích xuất AI.
Khối code và inline code
Nhiều PDF render code bằng font monospace nhưng mất đi thẻ ngữ nghĩa đây là code khi xuất ra. Bộ trích xuất AI phát hiện lại vùng code theo phong cách thị giác — font monospace và thụt đầu dòng — và bọc lại bằng hàng rào ba backtick. Pipeline dựa trên Pandoc thường làm phẳng code trở lại thành đoạn văn bình thường.
Footnote và trích dẫn
Bài báo khoa học dùng footnote đánh số với phần nội dung ở cuối trang. Con đường pdftotext làm mất liên kết giữa số tham chiếu và nội dung footnote. Docling và marker bảo toàn chúng dưới dạng cú pháp footnote Markdown chuẩn (tham chiếu [^1] + định nghĩa [^1]: nội dung).
PDF scan (cần OCR)
Một PDF scan là ảnh của trang giấy, không phải văn bản. Không có gì để trích xuất cho đến khi bạn chạy OCR trước.

Ba con đường đáng tin cậy:
-
ocrmypdf — thêm một lớp văn bản OCR vô hình vào PDF scan mà không thay đổi vẻ ngoài. Khi đã có lớp văn bản, mọi trình chuyển sau đó đều hoạt động:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
Bộ trích xuất AI có chế độ OCR — marker và Docling phát hiện được khi một trang không có lớp văn bản và tự động chạy OCR. Đầu ra được tích hợp, nên bạn có một file Markdown duy nhất thay vì một PDF trung gian.
-
Trình chuyển online có OCR tự động — một số công cụ trình duyệt (bao gồm của chúng tôi với PDF chỉ có ảnh) chạy OCR ngầm. Tiện lợi, nhưng để ý hỗ trợ ngôn ngữ nếu tài liệu của bạn không phải tiếng Anh.
Một cạm bẫy tinh tế: PDF "born-digital" (sinh ra từ file Word, không phải scan) vẫn có thể không có lớp văn bản nếu được xuất dưới dạng ảnh đã làm phẳng. Luôn kiểm tra xem có chọn được văn bản bên trong trình xem PDF không. Nếu có, bỏ qua OCR. Nếu không, chạy nó.
Chuẩn bị Markdown cho việc nạp RAG / LLM
Nếu đích đến là một vector database, một vài lựa chọn nhỏ trong lúc chuyển đổi sẽ làm chất lượng truy hồi phía sau khá hơn rõ rệt.
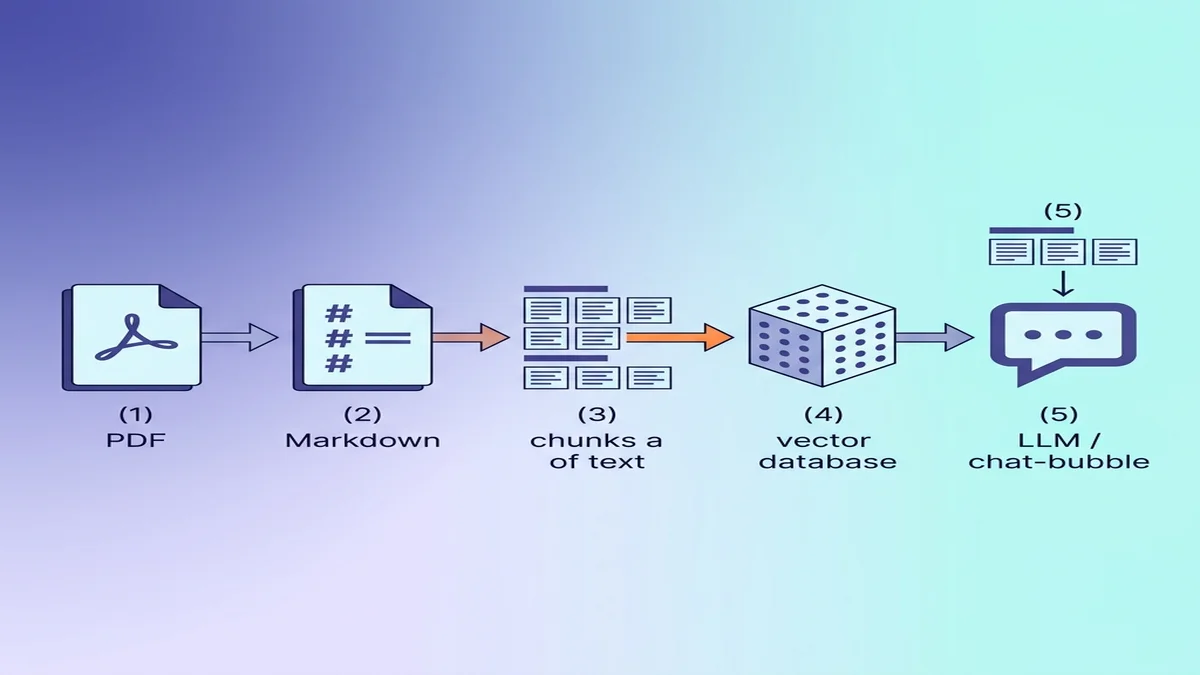
Vì sao Markdown thắng văn bản thô cho LLM
Markdown mang cấu trúc mà văn bản thuần đánh mất. Một mô hình đọc ## Methods biết nó đã bước vào một mục mới; cùng đoạn văn bản đó nhưng bị tước hết định dạng thì mô hình chỉ thấy các đoạn văn có sức nặng ngang nhau. Nếu bạn mới làm quen với cú pháp, hướng dẫn Markdown cơ bản đọc trong 5 phút là xong.
Chunk theo thứ bậc tiêu đề
Sai lầm RAG phổ biến nhất là chunk theo kích thước cố định — chia tài liệu thành các khối 500 token bất kể cấu trúc. Markdown cho phép bạn chunk theo ngữ nghĩa — chia theo ranh giới ## H2 và bạn có những mục mạch lạc thay vì các mảnh giữa đoạn.
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
Tốt hơn: đi qua các tiêu đề như một cây, gắn mỗi H3 vào H2 cha trong metadata của chunk.
Bảo toàn metadata trong frontmatter
Thêm YAML frontmatter ở đầu mỗi file đã chuyển để thông tin nguồn đi cùng từng chunk:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
Khi LLM truy hồi một chunk, metadata này trở thành footer trích dẫn. Đây cũng là cách bạn trả lời câu hỏi "tuyên bố này đến từ đâu?" về sau mà không cần chạy lại truy hồi. Nếu bạn dựng pipeline kiểu này từ các bản export chat, cùng ý tưởng áp dụng cho transcript ChatGPT/Claude.
Những cạm bẫy thường gặp và cách tránh
Một vài thứ hay cắn người làm việc này lần đầu.
- Bỏ qua chuẩn hoá encoding. PDF mê các trò Unicode: chữ ghép (
fi,fl), dấu nháy thông minh ("vs"), dấu em-dash trông như gạch nối. Hãy chạy đầu ra qua một bước chuẩn hoá Unicode (NFKC trong Python) trước khi đưa đi đâu khác. - Để lại header và footer của trang. Footer
Page 4 of 12của mỗi trang trở thành nhiễu trong truy hồi. Hãy bỏ các dòng lặp lại xuất hiện ở khoảng cách đều nhau. - Tin tưởng bảng đầu tiên bạn thấy. Kiểm thử kỹ ít nhất hai bảng đầu trước khi giả định phần còn lại ổn.
- Cho rằng "born-digital" có nghĩa là "có lớp văn bản". Một số PDF được xuất dưới dạng ảnh đã làm phẳng dù chúng khởi đầu là file Word. Luôn thử chọn văn bản trước.
- Chunk quá nhỏ với tài liệu ngắn. Với một memo 3 trang, hãy nạp cả Markdown vào mô hình và bỏ luôn bước RAG. Truy hồi là quá tay khi cửa sổ ngữ cảnh > tài liệu.
Câu hỏi thường gặp
Trình chuyển PDF sang Markdown miễn phí nào tốt nhất?
Với phần lớn người dùng, một trình chuyển online là con đường nhanh nhất — kéo, thả, xong. Với công việc lô hoặc lập trình, pymupdf4llm (Python) và Pandoc (CLI) bao quát các trường hợp đơn giản. Với bài báo khoa học có bảng và công thức, marker và Docling cho đầu ra tốt hơn rõ rệt. Lựa chọn "tốt nhất" tuỳ thuộc bạn tối ưu cho thời gian cài đặt hay độ trung thực đầu ra.
ChatGPT hay Claude có chuyển được PDF sang Markdown không?
Có, kèm cảnh báo. Cả hai đều có thể đọc trực tiếp một PDF và xuất ra Markdown, nhưng với tài liệu dài bạn có thể chạm giới hạn ngữ cảnh, và độ chính xác trên bảng và công thức biến động giữa các lần chạy. Cho các tác vụ chuyển đổi lô có tính xác định, một trình chuyển chuyên dụng đáng tin hơn. Xem xuất ChatGPT sang Word/PDF/HTML để biết quy trình quay vòng liên quan.
Làm sao chuyển một PDF scan sang Markdown?
Chạy OCR trước. Con đường gọn nhất là ocrmypdf để thêm lớp văn bản, sau đó bất kỳ trình chuyển nào cũng dùng được trên PDF đã OCR. Thay vào đó, marker và Docling có sẵn OCR và tạo ra Markdown trực tiếp từ PDF chỉ có ảnh.
Chuyển PDF sang Markdown online có riêng tư không?
Với trình chuyển của chúng tôi, file được xử lý trong bộ nhớ và xoá sau khi chuyển xong — không cần tài khoản, không lưu trữ lâu dài. Các dịch vụ khác thì tuỳ; hãy kiểm tra chính sách bảo mật của bất kỳ công cụ nào bạn dùng, đặc biệt với tài liệu mật.
Làm sao giữ bảng nguyên vẹn khi chuyển PDF sang Markdown?
Bỏ qua pipeline pdftotext + Pandoc với PDF nhiều bảng — nó gần như luôn làm méo. Hãy dùng một trình chuyển online xuất bảng GFM, hoặc dùng một bộ trích xuất AI như marker hoặc Docling. Dù chọn cách nào, hãy kiểm thử kỹ vài bảng đầu.
Tôi nên giữ PDF gốc hay chỉ giữ Markdown?
Giữ cả hai. Markdown dùng để nạp, tìm kiếm và chỉnh sửa. PDF là nguồn sự thật cho trích dẫn và audit. Hãy ghi tên file PDF và dải số trang trong frontmatter của Markdown để bạn luôn truy ngược một tuyên bố về nguồn của nó.
Sẵn sàng chuyển PDF đầu tiên?
Nếu bạn chỉ cần kết quả, trình chuyển PDF sang Markdown miễn phí của chúng tôi xử lý các trường hợp hằng ngày mà không cần đăng ký. Cho bước tiếp theo — biến Markdown đó thành tài liệu Word chỉn chu hoặc PDF sẵn sàng chia sẻ — xem Hướng dẫn Markdown sang Word.
References
- Pandoc User's Guide — tài liệu tham khảo CLI chuẩn về chuyển đổi.
- GitHub Flavored Markdown Spec — phương ngữ mà hướng dẫn này nhắm tới cho đầu ra.
- Docling (IBM Research) — bộ trích xuất PDF mã nguồn mở nhận biết bố cục.
- marker — bộ chuyển PDF sang Markdown mã nguồn mở xử lý bài báo khoa học tốt.
- pymupdf4llm — wrapper trích xuất Markdown gọn nhẹ quanh PyMuPDF.
- OCRmyPDF — thêm lớp văn bản tìm kiếm được cho PDF scan.