Word в Markdown: полное руководство по миграции в 2026
Как конвертировать документы Word в чистый Markdown для Git и Obsidian. Проверенные методы для DOCX с решением проблем таблиц, списков и встроенных изображений.

Запрос обычно звучит обманчиво просто: «Можешь перенести вот эти Word-документы в нашу командную вики?»
Вы открываете общий диск. Триста .docx файлов. Десять лет внутренней документации — политики, инструкции, заметки со встреч, спецификации — разбросаны по папкам с непоследовательными именами. Ничего из этого нормально не сравнивается через diff. Ничего толком не ищется. И кто-то решил, что всё это к концу квартала должно жить в Markdown под управлением Git.
Я проходил через такую миграцию дважды. Один раз — для архива compliance-документации (~200 файлов), второй раз — для базы знаний инженерной команды (~500 файлов). Оба раза вывод был одинаковым: конвертация Word в Markdown — это не операция в один клик. Это конвейер — конвертация, проверка, очистка — и большую часть времени съедает именно этап очистки.
В этом руководстве — то, что реально работает на практике: три метода конвертации, которые стоит знать, какие возможности Word переживают перенос (а какие тихо отваливаются), и чек-лист постобработки, который экономит часы ручных правок.
Зачем вообще переводить Word-документы в Markdown
Прежде чем «как», коротко о «зачем». Потому что если команда не сформулировала причину, миграция не приживётся.
- История, пригодная для diff.
.docxв Word — это ZIP-архив с XML внутри. Для Git две версии выглядят как два случайных бинарных блоба. Markdown — это обычный текст, где каждое изменение превращается в читаемый diff. - Поиск и grep.
rg "incident response" docs/пробегает по тысячам Markdown-файлов за миллисекунды. Тот же поиск по Word-документам требует проприетарного инструмента. - Автоматизация. Markdown понимают генераторы статических сайтов, инструменты документации (Docusaurus, MkDocs, Nextra), пайплайны подачи данных в LLM, CI-системы и линтеры. Word понимает в основном только сам Word.
- Долговечность. Файлы с простым текстом переживают вендоров софта. DOCX сегодня — стабильный формат, но горизонт совместимости для старого бинарного
.docуже размывается.
Если ничего из этого вашей команде не близко — миграция, вероятно, и не нужна. Если хотя бы один пункт попадает в цель — вы читаете нужное руководство.
Что переживает конвертацию, а что нет
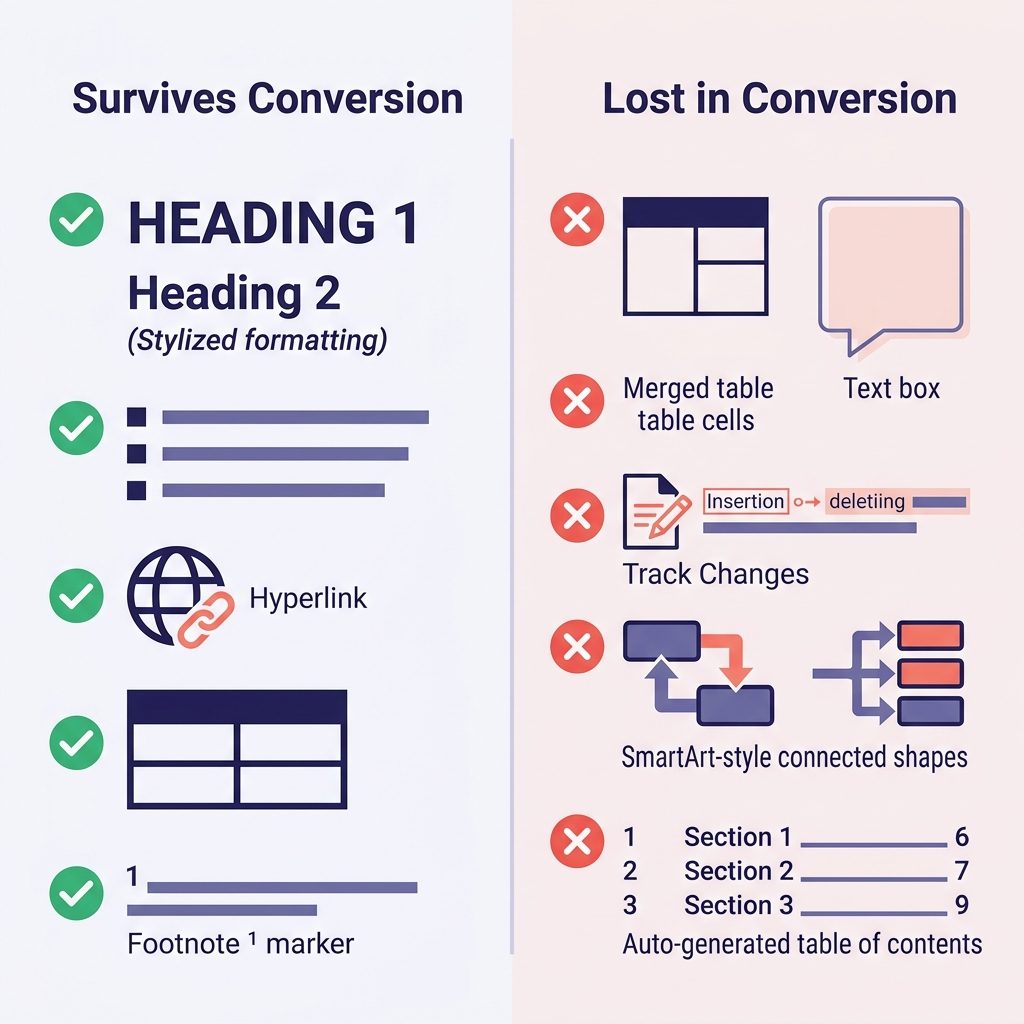
Правильно выставленные ожидания экономят больше всего времени. Вот что я наблюдал на сотнях конвертаций.
| Возможность Word (Word Feature) | Сохраняется? | Замечания |
|---|---|---|
| Заголовки (стили Heading 1–6) | Да | Прямо сопоставляются с # … ###### |
| Полужирный, курсив, подчёркнутый | Частично | Подчёркивание не имеет эквивалента в Markdown (становится курсивом или HTML <u>) |
| Маркированные и нумерованные списки | Обычно да | Глубокая вложенность иногда «схлопывается» |
| Гиперссылки | Да | URL и якорный текст сохраняются |
| Таблицы | Частично | Простые — да; объединённые ячейки, цвета и границы теряются |
| Встроенные изображения | Да | Извлекаются в папку, ссылки переписываются |
| Сноски | Да (GFM) | Конвертируются в синтаксис [^1] |
| Код (если оформлен стилем Code) | Зависит | Часто становится просто текстом без код-блока |
| Математические формулы | Частично | Могут конвертироваться в LaTeX, иногда теряются |
| Исправления (Track Changes) | Нет | Сначала примите или отклоните все правки |
| Комментарии | Нет | Разрешите или выгрузите отдельно перед конвертацией |
| Текстовые блоки, SmartArt, фигуры | Нет | Теряются полностью — замените на изображения или текст заранее |
| Автособираемое оглавление | Нет | Сгенерируйте заново средствами вашей docs-системы |
| Поля Word (дата, перекрёстные ссылки) | Нет | Перед экспортом преобразуйте в обычный текст |
Самые частые сюрпризы при миграции — это (1) оформление, которое выглядит как заголовок, но на самом деле сделано вручную через полужирный и увеличенный кегль: на выходе получается обычный жирный текст, и у документа нет структуры, — и (2) таблицы с объединёнными ячейками, которые разваливаются в некрасивую форму и требуют ручной перестройки.
Перед пакетной конвертацией пролистайте десяток случайных исходников и пометьте эти проблемы. На это уйдёт полчаса, зато удастся избежать множества переделок.
Метод 1. Онлайн-конвертер
Это то, что я рекомендую для одиночных файлов и небольших партий (до ~50 документов). Самый быстрый путь от .docx к чистому Markdown без какой-либо настройки.
- Откройте наш конвертер Word в Markdown
- Перетащите
.docxфайл в область загрузки - Просмотрите полученный Markdown
- Скачайте
.mdфайл (изображения при наличии упаковываются отдельно)
На выходе — GitHub Flavored Markdown (GFM), поэтому таблицы, чек-листы и сноски сохраняются. Заголовки сопоставляются с уровнями #, списки сохраняют иерархию, гиперссылки — якорный текст.
Важный момент: для стандартных документов вся конвертация происходит в браузере. Для очень больших файлов или чувствительных материалов то, что файл не уходит на внешние серверы, — это реальная функция, а не маркетинговая обёртка.
Ограничения у любого онлайн-конвертера (нашего или чужого) одинаковые: пакетная обработка работает не идеально, и его нельзя встроить в скрипт как часть пайплайна. Для таких случаев переходите к методу 2.
Метод 2. Pandoc (для пакетов и скриптов)
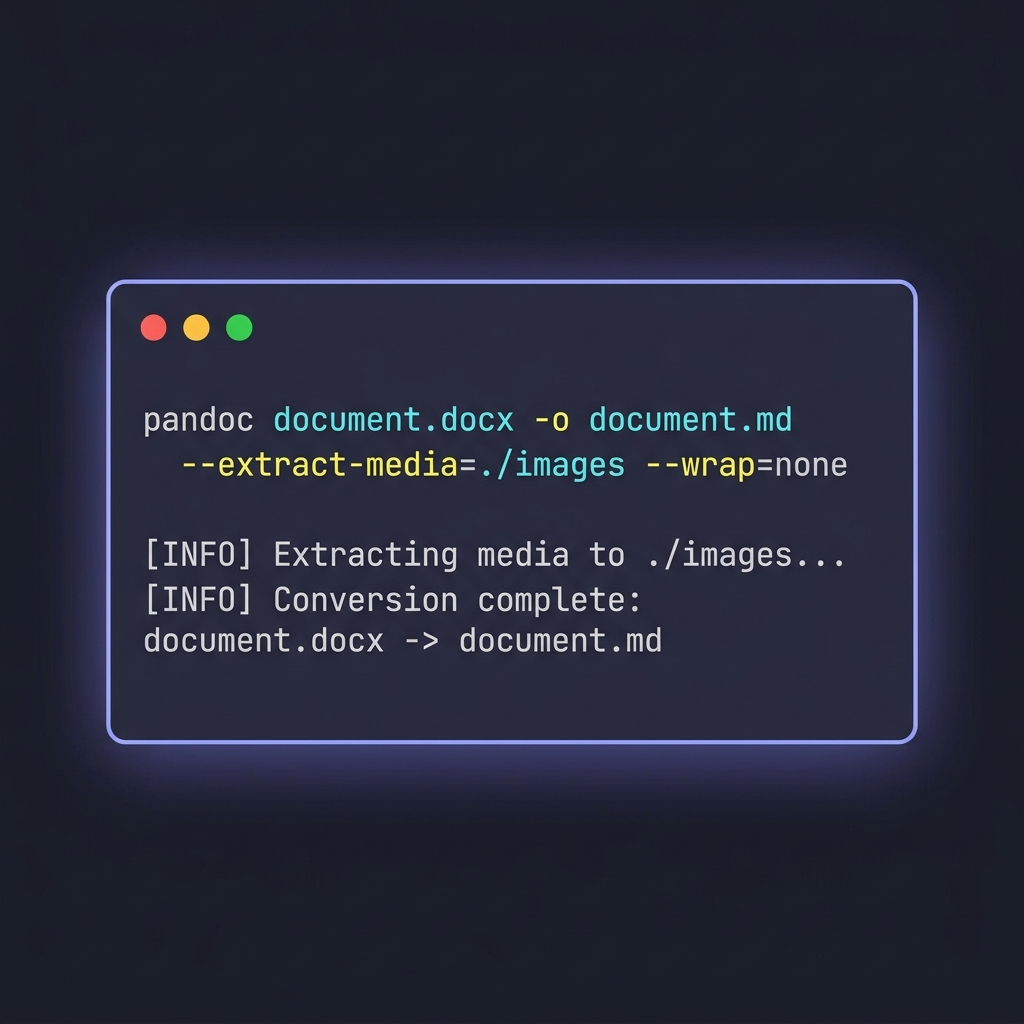
Pandoc — это универсальный конвертер документов. Именно им я пользуюсь во всём, что касается больше чем пары файлов или требует тонкой настройки вывода.
Базовая команда
pandoc document.docx -o document.md
Для одиночного файла этого достаточно. Работает быстро, даёт читаемый результат и «из коробки» обрабатывает большинство стандартных возможностей Word. Но настоящая ценность Pandoc раскрывается с флагами.
Три флага, которые стоит знать
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— извлекает встроенные изображения из DOCX в отдельную папку и переписывает ссылки в выводе. Без этого флага встроенные картинки тихо теряются.--wrap=none— запрещает Pandoc жёстко переносить строки примерно на 80-м символе. Это важно: жёсткие переносы ломают читаемость diff в Git для текстовых документов.--markdown-headings=atx— принудительно использует синтаксис# Headingвместо устаревшего setext-стиля (когда строка подчёркивается====). ATX — современная конвенция.
Пакетная конвертация папки
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
Закиньте это в shell-скрипт — и сотни файлов обрабатываются за минуты. Для больших архивов добавьте trap и логирование, чтобы можно было возобновить процесс, если что-то упало по дороге.
Реальные мелочи, за которыми стоит следить
- Маркеры списков разнятся. Pandoc иногда использует
-, иногда*. Если единообразие критично — прогоните черезsed -i 's/^\* /- /g'или настройте автоформатирование Markdown в редакторе. - Нумерованные списки неожиданно перезапускаются. В Word часто есть директивы «продолжить нумерацию», которые Pandoc не умеет интерпретировать. Увидите списки, считающие
1, 2, 1, 2, 3, хотя в исходнике всё выглядело непрерывным. Лечится коротким ревью-проходом. - Таблицы с длинными ячейками теряют читаемость. Pandoc старается как может, но GFM-таблицы не поддерживают переносы строк внутри ячеек так, как это делает Word. Особо сложные таблицы имеет смысл вручную переделывать в HTML-блоки.
У Pandoc нет GUI — это одновременно недостаток (нетехнические коллеги им не воспользуются) и достоинство (легко встраивается в любой CI/CD-пайплайн).
Метод 3. Программная конвертация через Mammoth.js
Если вы строите пайплайн — скажем, скрипт миграции, который забирает DOCX-файлы из SharePoint, конвертирует их и коммитит в Git, — ни веб-интерфейс, ни вызов Pandoc через subprocess могут не подойти под ваш стек. Mammoth.js — это JavaScript-библиотека, которая конвертирует DOCX в чистый HTML или Markdown прямо в Node.js.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // готовый Markdown
console.log(result.messages); // предупреждения о неподдерживаемых фичах
});
Mammoth ценен своей жёсткой позицией: он полностью игнорирует визуальное оформление Word и концентрируется на семантической структуре (заголовки, списки, таблицы). По умолчанию вывод чище, чем у Pandoc, — ценой меньшей гибкости. Для миграции архива с одинаковой структурой документов я взял бы именно Mammoth. Для разношёрстных документов с обилием ручного форматирования выигрывает гибкость Pandoc.
У питонистов есть аналог — python-docx в связке с каким-нибудь Markdown-рендерером, но это скорее DIY-путь, чем готовое решение.
Этап очистки, о котором никто не предупреждает

Конвертация приводит вас к .md файлу. Но не к тому .md файлу, который захочется закоммитить.
Вот мой стандартный чек-лист после конвертации. На каждый документ уходит около пяти минут, когда набьёте руку:
- Проверьте, не потерялись ли заголовки как структура. Поищите строки, которые выглядят как заголовок, но на деле оформлены как
**Жирный текст**отдельной строкой. Кто-то в Word сверстал их руками вместо стиля Heading. Повышайте их до реальных##заголовков. - Проверьте первую таблицу. Если здесь всё выглядит нормально — вероятно, и в других таблицах всё хорошо. Если первая сломана — сломаны все.
- Уберите пустые строки внутри пунктов списка. Pandoc иногда вставляет пустые строки, которые разрывают список.
- Проверьте ссылки на изображения. Откройте файл в Markdown-превью (встроенный в VS Code подходит) и убедитесь, что картинки грузятся.
- Найдите «мусор». Типичные остатки:
\в концах строк (жёсткие переносы, которые Word скрывает, а Markdown показывает), атрибуты вида{.underline}, проскочившие теги<span>. - Посмотрите первые и последние 10 строк. Колонтитулы и номера страниц из Word часто протекают в вывод — либо как пустые строки, либо как странные артефакты.
Для большой миграции пункты 5 и 6 имеет смысл автоматизировать скриптом очистки. Остальное выигрывает от живого взгляда — по крайней мере пока вы не наработали достаточно паттернов, чтобы доверять выводу для конкретного класса документов.
Реальная миграция: архив из 200 compliance-документов
Вот рабочий процесс, который я использовал для миграции compliance-архива. От начала до конца — два дня работы над 200 файлами.
День 1, утро: сортировка исходников
Написал Python-скрипт, который открывал каждый DOCX, считал заголовки, изображения и таблицы, и помечал всё, где оставались непринятые Track Changes или комментарии. На выходе — CSV-файл со списком документов, отсортированным по сложности. Задачи что-то чинить пока не стояло — я просто понимал, куда иду.
День 1, день: пакетная конвертация простых файлов
Около 140 из 200 документов были прямолинейными: без картинок, простые таблицы, чистая структура заголовков. Прогнал их через Pandoc в цикле с --extract-media и --wrap=none. Выборочно проверил 20 случайных файлов. Всё хорошо.
День 2, утро: сложные файлы — поштучно
Оставшиеся 60 документов имели проблемы: объединённые ячейки, встроенные Excel-объекты или значительная история Track Changes, которую кто-то должен был пересмотреть. Для этих файлов я использовал онлайн-конвертер по одному, иногда запускал Pandoc с другими флагами, иногда сначала чистил исходный DOCX.
День 2, день: очистка и коммиты
Прогнал скрипт очистки по всем 200 конвертированным файлам (убирал {.underline}, приводил маркеры списков к одному виду, правил последствия переноса строк у Pandoc). Просмотрел diff-ы, закоммитил пачками по 50 файлов, запушил в ветку миграции.
Если бы я пробовал делать что-либо из этого вручную — открывая каждый Word-документ и вставляя в Markdown-редактор — ушло бы минимум две недели. Инструменты конвертации здесь не опция; они — то, что делает проект вообще выполнимым.
Типичные проблемы и их решения
Таблицы некорректно выглядят в превью Markdown
В 90% случаев в исходнике были объединённые ячейки или очень длинный текст в ячейках. GFM-таблицы не поддерживают ни то, ни другое «красиво». Варианты: вручную перестроить таблицу под GFM, вставить HTML-блок <table> внутрь Markdown (поддерживается большинством рендереров) или разбить одну таблицу на несколько более простых.
Изображения не отображаются
Проверьте, извлёк ли их конвертер. Pandoc не сделает этого без --extract-media. Онлайн-конвертеры обычно отдают ZIP с Markdown-файлом и папкой images/ — убедитесь, что оба оказались на своих местах и пути в Markdown сходятся с реальными путями к файлам.
В выводе странные обратные слэши в конце строк
Это жёсткие переносы строк из Word, которые Markdown отрисовывает как принудительные разрывы. Если исходный Word-документ был полон плотной вёрстки, где вместо переносов абзаца использовались разрывы строк, Pandoc их сохраняет. Обычно хватает быстрой замены по регулярке \\$ (конец строки).
После конвертации уровни заголовков «съехали»
Word-документы часто начинаются с Heading 2 или Heading 3 (потому что Heading 1 был зарезервирован под титульный лист). В Markdown принято начинать с # (H1). В зависимости от того, как ваша docs-система отображает заголовки, может потребоваться поднять все уровни на один. sed справится: sed -i 's/^## /# /; s/^### /## /; ...' file.md.
Итоговый Markdown визуально совсем не похож на Word-документ
Это нормально. Markdown описывает структуру, а не внешний вид. Оформление задаёт та система, что рендерит Markdown (GitHub, ваш docs-сайт, тема MkDocs и т.д.). Если критична визуальная точность — лучше целиться в PDF. См. наше руководство по конвертации Markdown в PDF — там рассматриваются рабочие процессы, сохраняющие внешний вид.
Обратный путь: Markdown снова в Word
Естественный вопрос после миграции: «А что, если нужно отправить Markdown-документ человеку, который открывает только Word?» Это обратная конвертация — и она гораздо чище, потому что ограничения Markdown означают, что переводить особо нечего. В руководстве по конвертации Markdown в Word этот процесс разобран подробно.
Для команд, которые регулярно ходят между обоими форматами, я видел работающий шаблон: Markdown — источник истины в Git, Word-экспорты делаются по требованию, когда кому-то нужно вычитать или прокомментировать документ. Никаких правок в Word, которые потом сливаются обратно — иначе миграция начнёт медленно разваливаться.
Итоги
Конвертация Word в Markdown — это миграция, а не нажатие кнопки. Инструменты делают тяжёлую работу — наш онлайн-конвертер для разовых файлов, Pandoc для пакетов, Mammoth.js для пайплайнов — но настоящая работа в том, что происходит до конвертации (инспекция) и после неё (очистка).
Два подхода, которые экономят больше всего времени:
- Сначала сортируйте. Поймите, что лежит в вашем исходном архиве, прежде чем начинать конвертацию. Пятнадцать минут выборочной оценки избавляют от часов реакций на сюрпризы.
- Закладывайте время на очистку. Планируйте по пять минут на документ на ревью и полировку. Если относиться к этому как к неизбежному этапу, честно считать сроки миграции будет проще.
Если Markdown для вас в новинку и хочется сначала понять, как вообще выглядит результат, начните со статьи что такое Markdown и руководства по базовому синтаксису. Для расширенных возможностей — таблицы, сноски, чек-листы — в справочнике по расширенному синтаксису разобрано всё, что поддерживает GFM.
А если ваша миграция идёт не из Word, а из Obsidian, руководство по экспорту из Obsidian закрывает этот сценарий от начала до конца.