Convertir un PDF en Markdown en 2026 (gratuit + prêt pour RAG)
Convertissez un PDF en Markdown proprement en 2026. Comparez outils en ligne gratuits, Pandoc et extracteurs IA — avec workflows RAG et solutions OCR.

Si vous avez déjà copié-collé un paragraphe depuis un PDF et regardé le résultat exploser en sauts de ligne anarchiques, traits d'union cassés et mise en forme évaporée, vous savez déjà pourquoi convertir un PDF en Markdown est devenu un vrai problème de workflow en 2026.
Le PDF est la monnaie universelle du partage de documents. C'est aussi un format source désastreux. Dès que vous voulez injecter ce contenu dans un pipeline RAG, le poser dans un site de documentation ou simplement l'archiver dans votre app de notes, il vous faut du texte structuré — des titres qui sont des titres, des tableaux qui sont des tableaux, du code qui est du code.
Ce guide passe en revue trois manières honnêtes de convertir un PDF en Markdown : un convertisseur en ligne sans installation, Pandoc en ligne de commande, et la nouvelle vague d'extracteurs propulsés par IA comme marker et Docling. Vous verrez lequel choisir selon le scénario, comment réparer ce qu'ils cassent (tableaux, mathématiques, pages scannées), et comment livrer la sortie dans un pipeline LLM sans avoir à la nettoyer deux fois.
Pourquoi convertir un PDF en Markdown ?
Le même problème de conversion revient dans trois communautés différentes. Chacune a sa propre raison d'y tenir, mais le format de destination est identique.
Nourrir les pipelines RAG et LLM avec du texte propre
Les pipelines de génération augmentée par récupération n'aiment pas le texte PDF brut. Artefacts de saut de page, mises en page deux colonnes écrasées en une seule, en-têtes et pieds de page qui se répètent à chaque page — tout cela devient du bruit dans la base vectorielle et pollue la récupération.
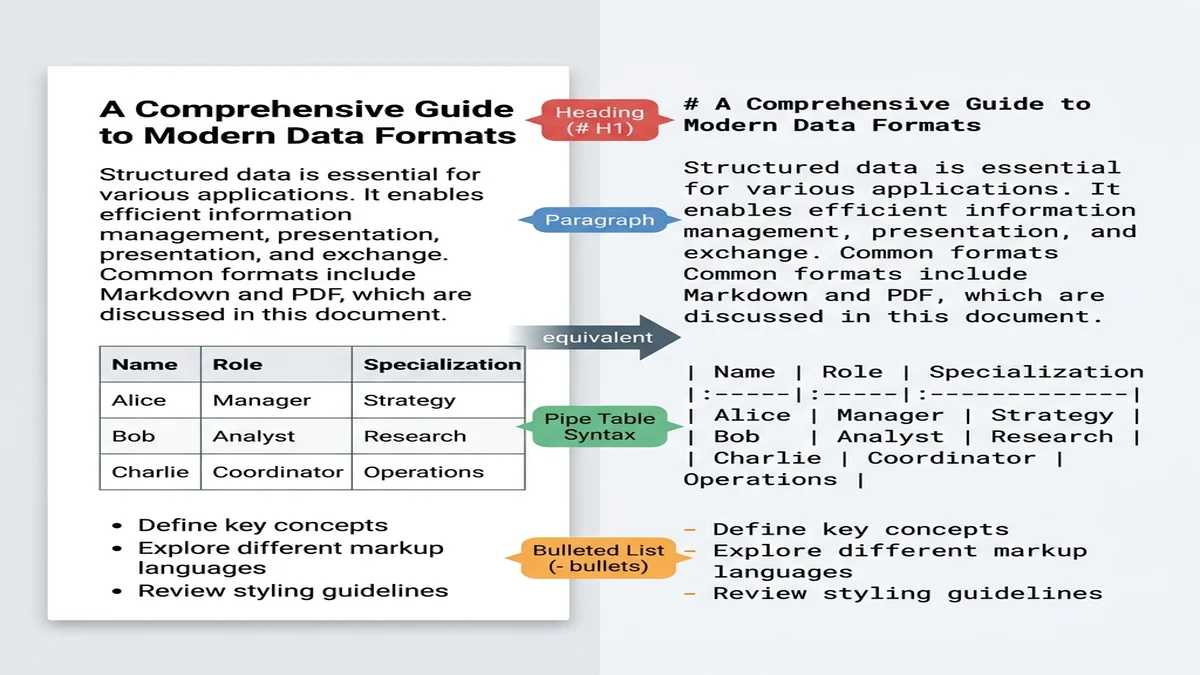
Markdown est plus proche du « texte brut structuré » que tout autre format pratique. Les grands modèles entraînés sur des données web ont vu des milliards de documents Markdown (fichiers README, réponses Stack Overflow, articles de blog), ils reconnaissent donc les titres # comme frontières de section et les pipes | comme séparateurs de tableau, sans que vous ayez à le préciser.
Migrer d'anciens PDF vers des systèmes de documentation modernes
Docusaurus, MkDocs, Astro Starlight et Hugo veulent tous du Markdown. Si votre équipe a 200 PDF de documentation interne historique, vous ne voulez pas mobiliser une armée de copier-coller — vous voulez un convertisseur qui préserve la hiérarchie des titres pour que la navigation se construise toute seule.
Construire un second cerveau interrogeable
Obsidian, Logseq, Foam, Roam — toutes les apps de notes modernes parlent Markdown. Les universitaires qui numérisent des archives papier, les travailleurs du savoir qui archivent des comptes rendus de réunion et les chercheurs qui constituent une bibliothèque bibliographique ont besoin de la même chose : un fichier Markdown propre avec les titres intacts, pour pouvoir faire un grep sur des centaines de documents plus tard.
Les trois approches (et quand utiliser chacune)
Il existe des dizaines d'outils, mais en réalité seulement trois catégories. Choisissez la ligne qui correspond à votre situation.
| Méthode | Vitesse | PDF simples | PDF complexes | OCR pour scans | Installation |
|---|---|---|---|---|---|
| Convertisseur en ligne | Rapide | Excellent | Bon | Intégré ou auto | Aucune |
| Pandoc + pdftotext | Rapide | Bon | Moyen sur les tableaux | Non | Installation CLI |
| Extracteur IA (marker / Docling) | Lent | Excellent | Excellent | Oui | Python + dépendances ML |
Si vous ne savez pas quoi choisir, commencez par un convertisseur en ligne. Cela vous coûte une minute d'essai, et pour la plupart des conversions ponctuelles ou de petits lots, l'histoire s'arrête là. Pour des pipelines programmatiques ou du contenu académique dense, descendez d'un cran. Nous comparons un panorama plus large dans notre sélection de convertisseurs Markdown gratuits.
Méthode 1 : Convertir un PDF en Markdown en ligne (gratuit, sans installation)
Le chemin le plus rapide est aussi celui que la plupart des gens snobent parce qu'il paraît trop simple. Pour une part écrasante du travail quotidien — notes de réunion, articles, rapports d'un seul chapitre — un convertisseur navigateur suffit largement.
Vous pouvez déposer votre fichier directement dans notre convertisseur PDF vers Markdown gratuit et sauter le reste de cette section.
Workflow pas à pas
- Glissez-déposez le PDF sur la zone d'upload (ou cliquez pour choisir un fichier).
- Patientez quelques secondes le temps que le parseur termine. Tout document de moins de 20 pages se convertit généralement avant que vous n'ayez relu cette phrase deux fois.
- Prévisualisez le Markdown rendu à côté de la source à droite.
- Copiez la source, ou téléchargez un fichier
.md.
C'est tout. Pas de compte, pas d'email obligatoire, pas de filigrane sur la sortie.
Quand cette approche brille
- Conversions ponctuelles où vous ne voulez rien installer.
- Vérifications rapides avant de décider d'investir dans un pipeline programmatique.
- Fichiers sensibles à la confidentialité, pour lesquels vous préférez ne pas envoyer le document dans une API tierce. Notre convertisseur traite les fichiers en mémoire et les purge immédiatement — aucun stockage persistant.
Limites
Les convertisseurs en ligne en général (pas seulement le nôtre) ont deux modes d'échec qu'il faut connaître.
Le premier, ce sont les PDF très volumineux ou atypiques. Une déclaration légale scannée de 600 pages avec polices embarquées et champs de formulaire dynamiques n'est un scénario « dépose et télécharge » pour aucun outil. Si vous en avez un sous la main, sautez à la section sur les extracteurs IA.
Le second, ce sont les PDF scannés sans couche de texte. Il n'y a rien à extraire — la page est juste une image. Il vous faut d'abord de l'OCR ; voir Gérer les contenus délicats plus bas.
Méthode 2 : Pandoc en ligne de commande
Pandoc est le couteau suisse de la conversion documentaire. C'est l'outil adapté quand il vous faut un pipeline reproductible, scriptable, et que vous ne voulez dépendre d'aucun service web.
L'attrape, honnêtement : Pandoc lui-même n'a pas de lecteur PDF solide. Le workflow communautaire passe par pdftotext (des utilitaires Poppler) et redirige le résultat vers Pandoc.
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
Pour un PDF simple, essentiellement textuel — une note, un article en une colonne — cette combinaison fonctionne bien et tourne en quelques millisecondes.
Quand la fidélité compte
Si votre PDF est surtout de la prose, ce pipeline produit un fichier Markdown propre avec une structure de paragraphes intacte. Ajoutez les options -V et --wrap=none pour ajuster la sortie aux outils en aval qui n'apprécient pas les lignes coupées en dur.
Là où Pandoc patauge
- Mises en page multi-colonnes (papiers académiques, magazines) :
pdftotextmélange les colonnes et la sortie devient illisible. - Tableaux : tout ce qui dépasse la grille deux colonnes la plus simple arrive en colonnes séparées par des espaces plutôt qu'en pipes Markdown.
- Mathématiques et blocs de code : aucune préservation sémantique ; les équations LaTeX deviennent du texte, et le code en monospace devient des paragraphes ordinaires.
- PDF scannés : zéro support — Pandoc/pdftotext ne peuvent pas extraire de texte depuis des images.
Pour les tableaux en particulier, notre guide de la syntaxe Markdown étendue couvre le format de tableau GFM auquel vous voudrez faire correspondre la sortie.
Méthode 3 : Extraction propulsée par IA (marker, Docling, pymupdf4llm)
La vague 2024-2025 des extracteurs sensibles à la mise en page a changé la donne. Ces outils combinent détection visuelle de mise en page, OCR et génération de sortie structurée, ce qui leur permet de comprendre que cette zone est un tableau et que cette autre zone est un corps de texte en deux colonnes. La sortie est radicalement plus propre sur les PDF complexes.
Trois projets à connaître :
- marker — utilise surya (un modèle de mise en page) couplé à des heuristiques. Solide sur les papiers académiques, les mathématiques et les blocs de code. Apache 2.0.
- Docling — issu d'IBM Research. Excellente reconstruction de tableaux, s'intègre nativement à LlamaIndex et LangChain. Sous licence MIT.
- pymupdf4llm — wrapper léger autour de PyMuPDF. Plus rapide que les deux autres, moins de dépendances ML, conçu spécifiquement pour l'ingestion LLM.
Un exemple Python minimal
Voici le plus petit pipeline Docling utile :
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
Ou avec pymupdf4llm pour la voie plus légère :
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
Compromis
Ces outils sont plus lents que le pipeline Pandoc. Sur un laptop CPU typique, attendez-vous à ce qu'un article de 30 pages prenne des dizaines de secondes plutôt que des millisecondes ; avec un GPU, on retombe à quelques secondes pour marker. pymupdf4llm est le plus rapide des trois parce qu'il fait l'impasse sur les gros modèles de vision.
L'autre compromis, c'est le poids des dépendances. Un pip install marker-pdf tire PyTorch et quelques centaines de mégaoctets de poids de modèle. Si vous embarquez ça dans un conteneur, anticipez la taille.
Gérer les contenus délicats
Les différences entre méthodes deviennent évidentes quand vous arrêtez de tester sur des notes propres de deux pages et que vous commencez à faire passer de vrais PDF du monde réel.
Les tableaux qui ne survivent pas
Les tableaux, c'est là que la plupart des convertisseurs craquent. La voie pdftotext + Pandoc produit presque toujours une soupe de colonnes alignées par espaces qu'aucun renderer Markdown ne saura parser correctement. Les convertisseurs en ligne et les extracteurs IA s'en sortent bien mieux parce qu'ils détectent d'abord la zone du tableau avant de reconstruire les cellules.
L'astuce : vérifiez à la main votre premier tableau avant de faire confiance au reste. Si le premier tableau est massacré, les 50 autres le seront aussi.
Équations mathématiques et blocs LaTeX
Si votre PDF contient des équations, il vous faut un outil qui détecte les zones mathématiques et émet des blocs LaTeX ($$...$$) dans le Markdown. marker le fait ; Pandoc non. Pour de l'écriture scientifique, c'est la première raison d'accepter le coût en vitesse d'un extracteur IA.
Blocs de code et code inline
Beaucoup de PDF rendent le code dans une police monospace mais perdent l'étiquette sémantique « ceci est du code » à l'export. Les extracteurs IA redétectent les zones de code par le style visuel — la police monospace et l'indentation — et les ré-enrobent dans des clôtures à triple backticks. Les pipelines basés Pandoc aplatissent généralement le code en paragraphes ordinaires.
Notes de bas de page et citations
Les papiers académiques utilisent des notes de bas de page numérotées avec le corps de la note en bas de page. La voie pdftotext perd le lien entre le marqueur de référence et le corps de la note. Docling et marker les préservent en syntaxe Markdown de note de bas de page correcte (référence [^1] + définition [^1]: corps).
PDF scannés (OCR obligatoire)
Un PDF scanné est l'image d'une page, pas du texte. Il n'y a rien à extraire tant que vous n'avez pas lancé un OCR au préalable.

Trois voies fiables :
-
ocrmypdf — ajoute une couche de texte OCR invisible à un PDF scanné sans changer son apparence visuelle. Une fois la couche posée, n'importe quel convertisseur en aval fonctionne :
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
Extracteurs IA avec mode OCR — marker et Docling peuvent détecter qu'une page n'a pas de couche de texte et lancer un OCR automatiquement. La sortie est intégrée : vous obtenez un seul fichier Markdown au lieu d'un PDF intermédiaire.
-
Convertisseurs en ligne avec OCR automatique — certains outils navigateur (le nôtre inclus pour les PDF purement image) exécutent l'OCR de manière transparente. Pratique, mais surveillez la prise en charge linguistique si votre document n'est pas en anglais.
Un piège subtil : les PDF « nés numériques » (créés depuis un Word, pas scannés) peuvent quand même ne pas avoir de couche de texte s'ils ont été exportés en images aplaties. Vérifiez toujours d'abord si vous pouvez sélectionner le texte dans le lecteur PDF. Si oui, passez l'OCR. Sinon, lancez-le.
Préparer le Markdown pour l'ingestion RAG / LLM
Si la destination est une base vectorielle, quelques petits choix au moment de la conversion améliorent nettement la qualité de récupération en aval.
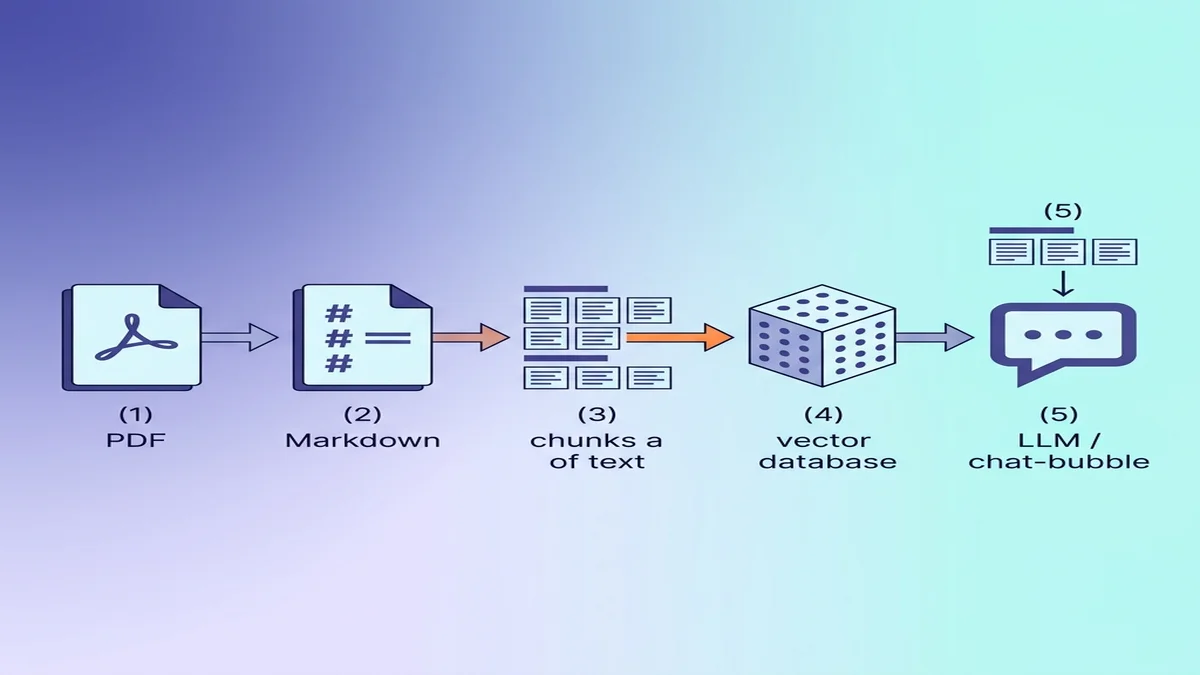
Pourquoi Markdown bat le texte brut pour les LLM
Markdown porte une structure que le texte brut perd. Un modèle qui lit ## Methods sait qu'il vient d'entrer dans une nouvelle section ; un modèle qui lit le même texte avec toute la mise en forme retirée ne voit que des paragraphes de poids égal. Si la syntaxe est nouvelle pour vous, notre guide Markdown de base se lit en 5 minutes.
Chunking par hiérarchie de titres
L'erreur RAG la plus fréquente, c'est le chunking de taille fixe — découper le document en blocs de 500 tokens sans tenir compte de la structure. Markdown vous permet de découper sémantiquement — découpez sur les frontières ## H2 et vous obtenez des sections cohérentes au lieu de fragments coupés au milieu d'un paragraphe.
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
Mieux : parcourez les titres comme un arbre, et attachez chaque H3 à son H2 parent dans les métadonnées du chunk.
Préserver les métadonnées en frontmatter
Ajoutez un frontmatter YAML en tête de chaque fichier converti pour que l'information de source voyage avec chaque chunk :
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
Quand le LLM récupère un chunk, ces métadonnées deviennent le pied de citation. C'est aussi ce qui vous permet, à terme, de répondre à la question « d'où vient cette affirmation ? » sans relancer la récupération. Si vous montez ce genre de pipeline à partir d'exports de chat, la même idée s'applique aux transcriptions ChatGPT/Claude.
Pièges courants et comment les éviter
Quelques détails piègent ceux qui s'y essaient pour la première fois.
- Sauter la normalisation d'encodage. Les PDF adorent les coquetteries Unicode : ligatures (
fi,fl), guillemets typographiques ("vs"), tirets cadratin qui ressemblent à des traits d'union. Passez la sortie par une normalisation Unicode (NFKC en Python) avant de l'envoyer où que ce soit. - Laisser les en-têtes et pieds de page. Le pied
Page 4 of 12de chaque page devient du bruit dans votre récupération. Supprimez les lignes répétées qui reviennent à intervalles réguliers. - Faire confiance au premier tableau venu. Inspectez au moins les deux premiers tableaux avant de supposer que les autres sont corrects.
- Croire que « né numérique » veut dire « avec une couche de texte ». Certains PDF sont exportés en images aplaties alors qu'ils sont partis d'un Word. Essayez toujours de sélectionner le texte d'abord.
- Sur-découper les petits documents. Pour une note de 3 pages, donnez tout le Markdown au modèle et oubliez carrément l'étape RAG. La récupération est superflue quand la fenêtre de contexte > document.
FAQ
Quel est le meilleur convertisseur PDF vers Markdown gratuit ?
Pour la plupart des utilisateurs, un convertisseur en ligne est la voie la plus rapide — glisser, déposer, terminé. Pour du traitement par lots ou programmatique, pymupdf4llm (Python) et Pandoc (CLI) couvrent les cas simples. Pour les papiers académiques avec tableaux et mathématiques, marker et Docling produisent une sortie nettement meilleure. Le « meilleur » choix dépend de ce que vous optimisez : temps d'installation ou fidélité de sortie.
ChatGPT ou Claude peuvent-ils convertir un PDF en Markdown ?
Oui, avec des réserves. Les deux peuvent lire un PDF directement et produire une sortie Markdown, mais sur des documents longs vous risquez d'atteindre les limites de contexte, et la précision sur les tableaux et les mathématiques varie d'une exécution à l'autre. Pour des conversions par lots déterministes, un convertisseur dédié est plus fiable. Voyez exporter ChatGPT vers Word/PDF/HTML pour le workflow aller-retour associé.
Comment convertir un PDF scanné en Markdown ?
Lancez d'abord un OCR. La voie la plus propre est ocrmypdf pour ajouter une couche de texte, puis n'importe quel convertisseur fonctionne sur le PDF OCRisé. Sinon, marker et Docling embarquent l'OCR et produisent du Markdown directement à partir de PDF purement image.
La conversion PDF vers Markdown en ligne est-elle confidentielle ?
Avec notre convertisseur, les fichiers sont traités en mémoire et purgés après conversion — aucun compte requis, aucun stockage persistant. Les autres services varient ; vérifiez la politique de confidentialité de tout outil que vous utilisez, surtout pour les documents confidentiels.
Comment garder les tableaux intacts en convertissant un PDF en Markdown ?
Évitez le pipeline pdftotext + Pandoc pour les PDF riches en tableaux — il les massacre presque toujours. Utilisez un convertisseur en ligne qui émet des tableaux GFM, ou un extracteur IA comme marker ou Docling. Dans tous les cas, vérifiez les premiers tableaux à la main.
Faut-il garder le PDF original ou seulement le Markdown ?
Gardez les deux. Le Markdown sert à l'ingestion, à la recherche et à l'édition. Le PDF reste votre source de vérité pour la citation et l'audit. Référencez le nom du fichier PDF et la plage de pages dans le frontmatter Markdown pour pouvoir toujours retracer une affirmation jusqu'à sa source.
Prêt à convertir votre premier PDF ?
Si vous voulez juste le résultat, notre convertisseur PDF vers Markdown gratuit couvre les cas du quotidien sans inscription. Pour l'étape suivante — transformer ce Markdown en document Word soigné ou en PDF prêt à partager — voyez notre guide Markdown vers Word.
Références
- Pandoc User's Guide — la référence canonique de la conversion en ligne de commande.
- GitHub Flavored Markdown Spec — le dialecte que ce guide cible en sortie.
- Docling (IBM Research) — extracteur PDF open source sensible à la mise en page.
- marker — outil open source PDF vers Markdown solide sur les papiers académiques.
- pymupdf4llm — wrapper léger d'extraction Markdown autour de PyMuPDF.
- OCRmyPDF — ajoute une couche de texte interrogeable aux PDF scannés.