Word zu Markdown: Vollständiger Migrations-Leitfaden 2026
Word-Dokumente in sauberes Markdown für Git-Workflows und Obsidian konvertieren. Praxiserprobte Methoden für DOCX-Dateien, inklusive Lösungen für Tabellen, Listen und eingebettete Bilder.

Die Anfrage klingt meistens harmlos: „Können Sie diese Word-Dokumente ins Team-Wiki übertragen?"
Sie öffnen das geteilte Laufwerk. Dreihundert .docx-Dateien. Ein Jahrzehnt interner Dokumentation — Richtlinien, Runbooks, Meeting-Notizen, Spezifikationen — verstreut in Ordnern mit uneinheitlicher Benennung. Nichts davon lässt sich sauber diffen. Nichts lässt sich gut durchsuchen. Und jemand hat entschieden, dass das Ganze bis Quartalsende in Git-verwaltetem Markdown liegen soll.
Ich habe zwei solcher Migrationen durchgeführt. Einmal für ein Compliance-Archiv (~200 Dateien), einmal für eine Engineering-Wissensdatenbank (~500 Dateien). Beide Male war die Lehre dieselbe: Die Konvertierung von Word zu Markdown ist keine Ein-Klick-Angelegenheit. Sie ist eine Pipeline — Konvertierung, Inspektion, Bereinigung — und der Bereinigungs-Schritt ist derjenige, der tatsächlich Zeit frisst.
Dieser Leitfaden zeigt, was in der Praxis funktioniert: die drei Konvertierungsmethoden, die Sie kennen sollten, welche Word-Funktionen die Reise überstehen (und welche stillschweigend auf der Strecke bleiben) sowie die Checkliste nach der Konvertierung, die Ihnen Stunden manueller Korrekturen erspart.
Warum Word-Dokumente überhaupt nach Markdown migrieren?
Bevor wir zum Wie kommen, kurz zum Warum. Denn wenn Ihr Team den Grund nicht klar formuliert hat, bleibt die Migration nicht bestehen.
- Diffbare Historie. Words
.docxist ein gezipptes XML-Bündel. Zwei Versionen sehen für Git aus wie zwei zufällige Binär-Blobs. Markdown ist reiner Text — jede Änderung wird zu einem lesbaren Diff. - Suchen und Greppen.
rg "incident response" docs/läuft in Millisekunden über Tausende Markdown-Dateien. Dasselbe über Word-Dokumente erfordert ein proprietäres Suchwerkzeug. - Automatisierung. Markdown lässt sich von Static-Site-Generatoren, Dokumentationstools (Docusaurus, MkDocs, Nextra), LLM-Ingestion-Pipelines, CI-Systemen und Lintern verarbeiten. Word lässt sich hauptsächlich von Word verarbeiten.
- Langlebigkeit. Reine Textdateien überdauern Softwarehersteller. DOCX ist heute ein stabiles Format, aber der Kompatibilitätshorizont für
.doc(das alte Binärformat) ist bereits unscharf.
Trifft nichts davon auf Ihr Team zu, brauchen Sie wahrscheinlich nicht zu migrieren. Trifft auch nur eines davon zu, sind Sie hier richtig.
Was die Konvertierung überlebt — und was nicht
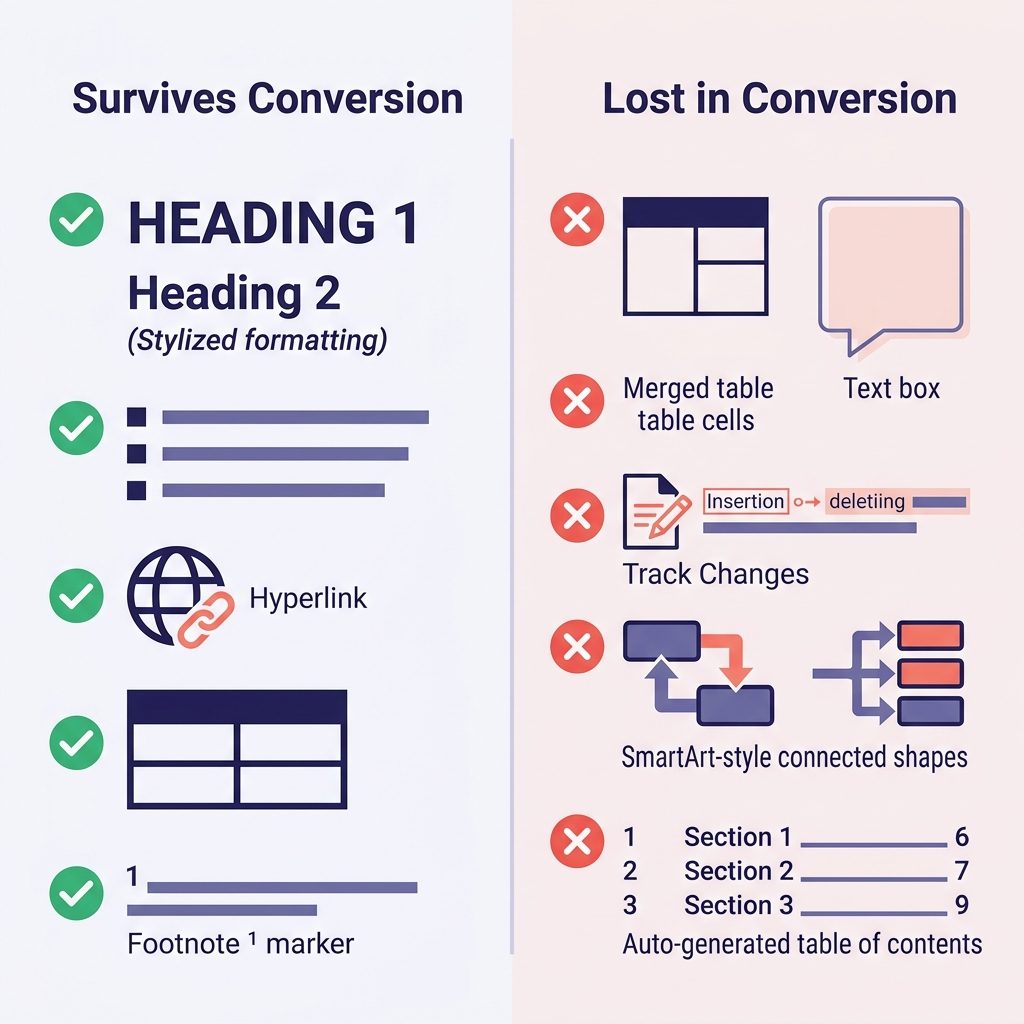
Realistische Erwartungen von Anfang an sparen am meisten Zeit. Das hier habe ich über Hunderte Konvertierungen hinweg beobachtet:
| Word-Funktion | Überlebt? | Anmerkungen |
|---|---|---|
| Überschriften (Heading 1–6) | Ja | Wird direkt auf # bis ###### abgebildet |
| Fett, kursiv, unterstrichen | Fett/kursiv ja | Unterstrichen hat kein Markdown-Äquivalent (wird kursiv oder HTML <u>) |
| Aufzählungs- und nummerierte Listen | Meistens ja | Tiefe Verschachtelungen verflachen manchmal |
| Hyperlinks | Ja | URL und Linktext bleiben erhalten |
| Tabellen | Einfache Tabellen ja | Verbundene Zellen, Zellfarben, Rahmen gehen verloren |
| Inline-Bilder | Ja | Werden in einen Ordner extrahiert, Links werden umgeschrieben |
| Fußnoten | Ja (GFM) | Wird zu [^1]-Syntax |
Code (als Code-Absatz formatiert) | Kommt darauf an | Verflacht oft zu reinem Text ohne Code-Fence |
| Mathematische Formeln | Teilweise | Kann zu LaTeX werden, manchmal verflacht |
| Änderungsnachverfolgung | Nein | Erst alle Änderungen annehmen oder ablehnen |
| Kommentare | Nein | Vor dem Konvertieren auflösen oder separat exportieren |
| Textfelder, SmartArt, Formen | Nein | Gehen vollständig verloren — vorher durch Bilder oder reinen Text ersetzen |
| Automatisch generiertes Inhaltsverzeichnis | Nein | Mit Ihrem Docs-Tool neu generieren |
| Word-Felder (Datum, Querverweise) | Nein | Vor dem Export in reinen Text umwandeln |
Die größten Überraschungen bei Migrationen sind üblicherweise (1) Formatierungen, die wie eine Überschrift aussehen, aber in Wahrheit manuell fett gesetzter Text mit größerer Schriftart waren — diese werden zu einfachem fettem Text und Ihre Ausgabe hat keine Struktur mehr — und (2) Tabellen mit verbundenen Zellen, die so kollabieren, dass das Ergebnis hässlich aussieht und manuell neu aufgebaut werden muss.
Bevor Sie eine Stapelkonvertierung starten, überfliegen Sie zehn zufällig ausgewählte Quelldokumente und markieren Sie diese Probleme. Das dauert dreißig Minuten und erspart Ihnen eine Menge Nacharbeit.
Methode 1: Online-Konverter
Das ist, was ich für einzelne Dateien und kleine Stapel (unter ~50 Dokumente) empfehle. Es ist der schnellste Weg von .docx zu sauberem Markdown — ohne Einrichtung.
- Öffnen Sie unseren Word-zu-Markdown-Konverter
- Ziehen Sie die
.docx-Datei in den Upload-Bereich - Prüfen Sie die Vorschau des konvertierten Markdowns
- Laden Sie die
.md-Datei herunter (Bilder werden separat gebündelt, falls vorhanden)
Die Ausgabe verwendet GitHub Flavored Markdown (GFM), sodass Tabellen, Aufgabenlisten und Fußnoten erhalten bleiben. Überschriften werden auf #-Ebenen abgebildet, Listen behalten ihre Hierarchie und Hyperlinks behalten ihren Ankertext.
Bemerkenswert: Die Konvertierung läuft bei Standard-Dokumenten vollständig im Browser. Bei sehr großen Dateien oder sensiblen Inhalten ist es ein echter Vorteil — nicht nur Marketing-Gerede — dass die Datei gar nicht erst auf fremde Server gelangt.
Die Grenzen jedes Online-Konverters (unser oder fremder) sind dieselben: Für Stapelverarbeitung ist er nicht ideal, und er lässt sich nicht als Teil einer Pipeline skripten. Für diese Fälle überspringen Sie zu Methode 2.
Methode 2: Pandoc (für Stapel und Skripte)
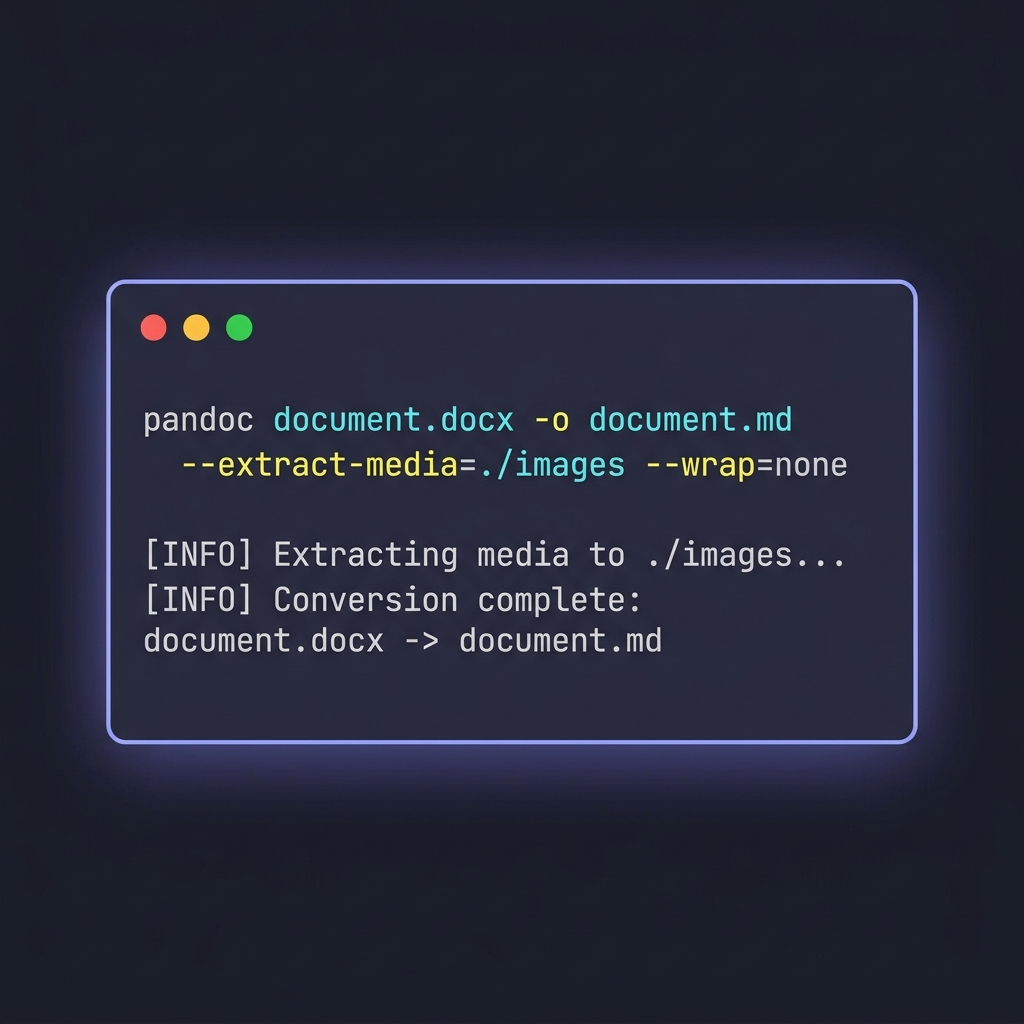
Pandoc ist der universelle Dokumentenkonverter. Das ist das Werkzeug, das ich für alles nutze, was mehr als eine Handvoll Dateien umfasst oder bei dem ich die Ausgabe feinjustieren muss.
Der Basis-Befehl
pandoc document.docx -o document.md
Mehr ist es für eine einzelne Datei nicht. Der Befehl läuft schnell, erzeugt lesbare Ausgabe und verarbeitet die meisten gängigen Word-Funktionen von Haus aus. Aber Pandocs eigentlicher Wert zeigt sich bei den Flags.
Drei Flags, die Sie kennen sollten
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— holt eingebettete Bilder aus der DOCX-Datei, legt sie in einem Ordner ab und schreibt die Bild-Links in der Ausgabe um. Ohne dieses Flag werden Inline-Bilder stillschweigend verworfen.--wrap=none— verhindert, dass Pandoc Zeilen bei ~80 Zeichen hart umbricht. Das ist wichtig, weil harte Umbrüche bei prosa-lastigen Dokumenten die Lesbarkeit von Git-Diffs zerstören.--markdown-headings=atx— erzwingt die# Heading-Syntax statt des älteren Setext-Stils (Zeilen mit====unterstrichen). ATX ist die moderne Konvention.
Einen Ordner im Stapel konvertieren
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
Legen Sie das in ein Shell-Skript und Sie verarbeiten Hunderte Dateien in Minuten. Für größere Archive fügen Sie trap und Logging hinzu, damit Sie fortsetzen können, falls etwas mittendrin abstürzt.
Stolpersteine aus der Praxis
- Aufzählungszeichen variieren. Pandoc verwendet mal
-, mal*. Wenn Ihnen Einheitlichkeit wichtig ist, lassen Siesed -i 's/^\* /- /g'über die Ausgabe laufen oder konfigurieren Sie den Markdown-Formatter Ihres Editors. - Nummerierte Listen starten unerwartet neu. Word hat oft „Nummerierung fortsetzen"-Anweisungen, die Pandoc nicht interpretieren kann. Sie sehen dann Listen, die
1, 2, 1, 2, 3zählen, obwohl die Quelle durchgehend wirkte. Lässt sich mit einem schnellen Review-Durchgang beheben. - Tabellen mit langen Zellen geraten bei der Lesbarkeit ins Straucheln. Pandoc gibt sein Bestes, aber GFM-Tabellen unterstützen keine Zeilenumbrüche in Zellen so wie Word. Erwägen Sie, besonders komplexe Tabellen manuell in HTML-Blöcke zu überführen.
Pandoc hat keine grafische Oberfläche, was sowohl Nachteil (technisch weniger versierte Kolleginnen können es nicht ausführen) als auch Vorteil (es lässt sich in jede CI/CD-Pipeline skripten) ist.
Methode 3: Programmatische Konvertierung mit Mammoth.js
Wenn Sie eine Pipeline bauen — etwa ein Migrationsskript, das DOCX-Dateien aus SharePoint zieht, konvertiert und nach Git committet — passen weder ein Web-UI noch ein Subprocess-Aufruf zu Pandoc in Ihren Stack. Mammoth.js ist eine JavaScript-Bibliothek, die DOCX direkt in Node.js in sauberes HTML oder Markdown konvertiert.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // the Markdown output
console.log(result.messages); // warnings about unsupported features
});
Was Mammoth nützlich macht, ist seine meinungsstarke Herangehensweise: Es ignoriert Words visuelle Gestaltung vollständig und konzentriert sich auf semantische Struktur (Überschriften, Listen, Tabellen). Die Ausgabe ist standardmäßig sauberer als die von Pandoc — auf Kosten geringerer Kontrolle. Für die Migration eines Legacy-Archivs, in dem die meisten Dokumente eine einheitliche Struktur haben, würde ich zu Mammoth greifen. Bei eigenwilligen Dokumenten mit starker Formatierung gewinnt Pandocs Flexibilität.
Python-Nutzer haben mit python-docx in Kombination mit einem Markdown-Writer eine ähnliche Option, auch wenn das eher der Marke Eigenbau entspricht als einem fertigen Werkzeug.
Der Bereinigungs-Schritt, vor dem niemand warnt

Die Konvertierung bringt Sie zu einer .md-Datei. Sie bringt Sie nicht zu einer .md-Datei, die Sie committen möchten.
Hier ist meine Standard-Checkliste nach der Konvertierung. Wenn Sie eingeübt sind, dauert sie etwa fünf Minuten pro Dokument:
- Strukturelle Überschriften prüfen. Durchsuchen Sie die Ausgabe nach Zeilen, die wie Überschriften aussehen, aber in Wahrheit
**Fetter Text**in einer eigenen Zeile sind. Jemand hat sie in Word per Hand formatiert, statt die Überschriftenformate zu nutzen. Machen Sie daraus echte##-Überschriften. - Prüfen Sie die erste Tabelle. Sehen Tabellen hier richtig aus, werden sie wahrscheinlich überall richtig aussehen. Ist die erste kaputt, sind alle kaputt.
- Leerzeilen innerhalb von Listeneinträgen entfernen. Pandoc fügt manchmal Leerzeilen ein, die die Listenkontinuität unterbrechen.
- Bildlinks verifizieren. Öffnen Sie die Datei in einer Markdown-Vorschau (die in VS Code eingebaute genügt) und bestätigen Sie, dass Bilder geladen werden.
- Nach Rückständen suchen. Häufige Überbleibsel:
\am Zeilenende (harte Zeilenumbrüche, die Word verbirgt, Markdown aber zeigt),{.underline}-Style-Attribute, durchgerutschte<span>-Tags. - Erste und letzte 10 Zeilen prüfen. Kopf- und Fußzeilen sowie Seitenzahlen aus Word sickern oft als leerer Inhalt oder seltsame Artefakte in die Ausgabe.
Bei einer großen Migration automatisieren Sie Punkt 5 und 6 mit einem Bereinigungsskript. Alles Übrige profitiert vom menschlichen Auge — zumindest so lange, bis Sie genug Mustererkennung aufgebaut haben, um der Ausgabe für eine bestimmte Dokumentenklasse zu vertrauen.
Eine echte Migration: 200-Datei-Compliance-Archiv
So sah der Workflow aus, den ich für die Compliance-Archiv-Migration verwendet habe. Von Anfang bis Ende waren es zwei Arbeitstage für ein 200-Dateien-Archiv.
Tag 1 Vormittag: Quelle triagieren
Ich habe ein Python-Skript geschrieben, das jedes DOCX öffnete, Überschriften, Bilder und Tabellen zählte und alles markierte, bei dem die Änderungsnachverfolgung noch aktiv war oder Kommentare enthalten waren. Ergebnis war eine CSV der Dateien, sortiert nach Komplexität. Das Ziel war noch nicht, etwas zu reparieren — sondern zu wissen, worauf ich mich einlasse.
Tag 1 Nachmittag: Einfache Dateien im Stapel konvertieren
Etwa 140 der 200 Dateien waren unkompliziert: keine Bilder, einfache Tabellen, saubere Überschriftenstruktur. Ich habe sie in einer Schleife mit --extract-media und --wrap=none durch Pandoc geschickt. Dann habe ich stichprobenartig 20 zufällige Dateien kontrolliert. Alles in Ordnung.
Tag 2 Vormittag: Komplexe Dateien einzeln behandeln
Die verbleibenden 60 hatten Probleme — verbundene Tabellenzellen, eingebettete Tabellenobjekte oder erhebliche Änderungsnachverfolgungs-Historie, die vorher jemand prüfen musste. Für diese habe ich den Online-Konverter von Fall zu Fall eingesetzt, manchmal Pandoc mit anderen Flags ausgeführt, manchmal die Quell-DOCX vorher bereinigt.
Tag 2 Nachmittag: Bereinigung und Commit
Ein Bereinigungsskript über alle 200 konvertierten Dateien laufen lassen ({.underline}-Artefakte entfernt, Aufzählungszeichen vereinheitlicht, Pandocs Zeilenumbrüche korrigiert). Diffs geprüft, in 50er-Batches committet, auf den Migrationszweig gepusht.
Hätte ich das manuell versucht — jedes Word-Dokument zu öffnen und in einen Markdown-Editor einzufügen — wären es mindestens zwei Wochen Arbeit gewesen. Die Konvertierungswerkzeuge sind nicht optional; sie sind das, was das Projekt überhaupt machbar macht.
Häufige Probleme und Lösungen
Tabellen sehen in der Markdown-Vorschau falsch aus
In neunzig Prozent der Fälle hatte die Quelle verbundene Zellen oder sehr lange Zellinhalte. GFM-Tabellen unterstützen beides nicht elegant. Ihre Optionen: die Tabelle manuell in GFM neu aufbauen, einen HTML-<table>-Block innerhalb des Markdowns verwenden (wird von den meisten Renderern unterstützt) oder die Tabelle in mehrere einfachere Tabellen aufteilen.
Bilder werden nicht angezeigt
Prüfen Sie, ob der Konverter sie extrahiert hat. Pandoc tut das nur mit --extract-media. Online-Konverter liefern üblicherweise ein ZIP mit der Markdown-Datei plus einem images/-Ordner — stellen Sie sicher, dass beides am richtigen Ort gelandet ist und die Bildpfade im Markdown passen.
Die Ausgabe hat seltsame Backslashes am Zeilenende
Das sind harte Zeilenumbrüche aus Word, die Markdown als erzwungene Umbrüche rendert. War das Quell-Word-Dokument voll enger Absatzabstände, die mit Zeilenumbrüchen statt Absatzumbrüchen realisiert wurden, behält Pandoc sie bei. Ein schnelles Suchen-und-Ersetzen nach \\$ (Zeilenende) räumt das üblicherweise auf.
Überschriften-Ebenen stimmen nach der Konvertierung nicht
Word-Dokumente starten häufig mit Heading 2 oder Heading 3 (weil Heading 1 der Titelseite vorbehalten war). Die Markdown-Konvention ist, mit # (H1) zu beginnen. Je nachdem, wie Ihr Docs-System Überschriften anzeigt, müssen Sie möglicherweise alle Ebenen um eins nach oben verschieben. Mit sed geht das: sed -i 's/^## /# /; s/^### /## /; ...' file.md.
Das Markdown sieht optisch überhaupt nicht wie das Word-Dokument aus
Das ist zu erwarten. Markdown beschreibt Struktur, nicht Erscheinung. Die Gestaltung kommt aus dem System, das das Markdown rendert (GitHub, Ihre Docs-Seite, MkDocs-Theme usw.). Ist visuelle Treue entscheidend, ist PDF das bessere Ziel — unser Markdown-zu-PDF-Leitfaden beschreibt Workflows, die das visuelle Design erhalten.
Hin und zurück: Markdown wieder nach Word
Eine naheliegende Frage nach der Migration: „Was, wenn ich ein Markdown-Dokument an eine Stakeholderin schicken muss, die nur Word öffnet?" Das ist die umgekehrte Konvertierung — und sie ist deutlich sauberer, weil Markdowns Beschränkungen bedeuten, dass weniger zu übersetzen ist. Der Markdown-zu-Word-Leitfaden deckt diesen Ablauf ab.
Für Teams, die häufig zwischen beiden Formaten wechseln, hat sich dieser Workflow bewährt: Markdown ist die Source of Truth in Git, Word-Exporte erfolgen bei Bedarf, wenn jemand prüfen oder kommentieren möchte. Nichts wird je in Word bearbeitet und zurückgemergt — so entwirrt sich die Migration nicht langsam wieder.
Zusammenfassung
Die Konvertierung von Word zu Markdown ist eine Migration, kein Knopfdruck. Die Werkzeuge erledigen die Schwerarbeit — unser Online-Konverter für Einzeldateien, Pandoc für Stapel, Mammoth.js für Pipelines — aber die eigentliche Arbeit ist die Inspektion vor der Konvertierung und die Bereinigung danach.
Die zwei Muster, die am meisten Zeit sparen:
- Erst triagieren. Verstehen Sie, was in Ihrem Quellarchiv steckt, bevor Sie mit der Konvertierung beginnen. Fünfzehn Minuten Stichproben ersparen Ihnen Stunden, in denen Sie auf Überraschungen reagieren.
- Rechnen Sie mit der Bereinigung. Planen Sie fünf Minuten pro Dokument für den Review- und Politur-Durchgang ein. Sie als unvermeidlichen Schritt zu behandeln, hält Sie ehrlich dabei, wie lange die Migration tatsächlich dauern wird.
Falls Sie neu bei Markdown sind und wissen möchten, wie die Ausgabe aussehen wird, starten Sie mit Was ist Markdown und dem Leitfaden zur Basis-Syntax. Für die fortgeschrittenen Funktionen — Tabellen, Fußnoten, Aufgabenlisten — deckt die Referenz zur erweiterten Syntax ab, was GFM unterstützt.
Und falls Ihre Migration aus Obsidian statt aus Word kommt, behandelt der Obsidian-Export-Leitfaden diesen Ablauf von Anfang bis Ende.