PDF 转 Markdown 完全指南(2026 免费 + RAG 就绪)
2026 年正确地把 PDF 转成 Markdown。对比免费在线工具、Pandoc 和 AI 提取器,给出 RAG 就绪工作流和 OCR 修复方案。

如果你曾经从一个 PDF 里复制粘贴一段文字,眼睁睁看着它炸成一团乱码 —— 换行错乱、连字符破碎、格式全丢 —— 那你就明白为什么把 PDF 转成 Markdown在 2026 年变成了一个正经的工作流难题。
PDF 是分享文档的通用货币,但它是个糟糕的源格式。一旦你想把内容喂进 RAG 流水线、放进文档站,或者只是丢到笔记应用里,你就需要结构化的文本 —— 标题归标题、表格归表格、代码归代码。
本文老老实实讲三种把 PDF 转成 Markdown 的方法:免安装的在线转换器、命令行里的 Pandoc,以及 marker、Docling 这类新一代 AI 提取器。我会告诉你哪种活儿用哪个,怎么修它们容易出错的地方(表格、公式、扫描页),以及怎么把输出直接送进 LLM 流水线,不用再回头清洗一遍。
为什么要把 PDF 转成 Markdown?
同一个转换难题反复出现在三个不同的群体里。每群人在意它的理由略有不同,但目标格式是同一个。
给 RAG 和 LLM 流水线喂干净文本
RAG 流水线不喜欢生 PDF 文本。分页伪影、双栏排版被压成单栏、页眉页脚每页重复 —— 这些都会变成向量数据库里的噪音,污染检索结果。
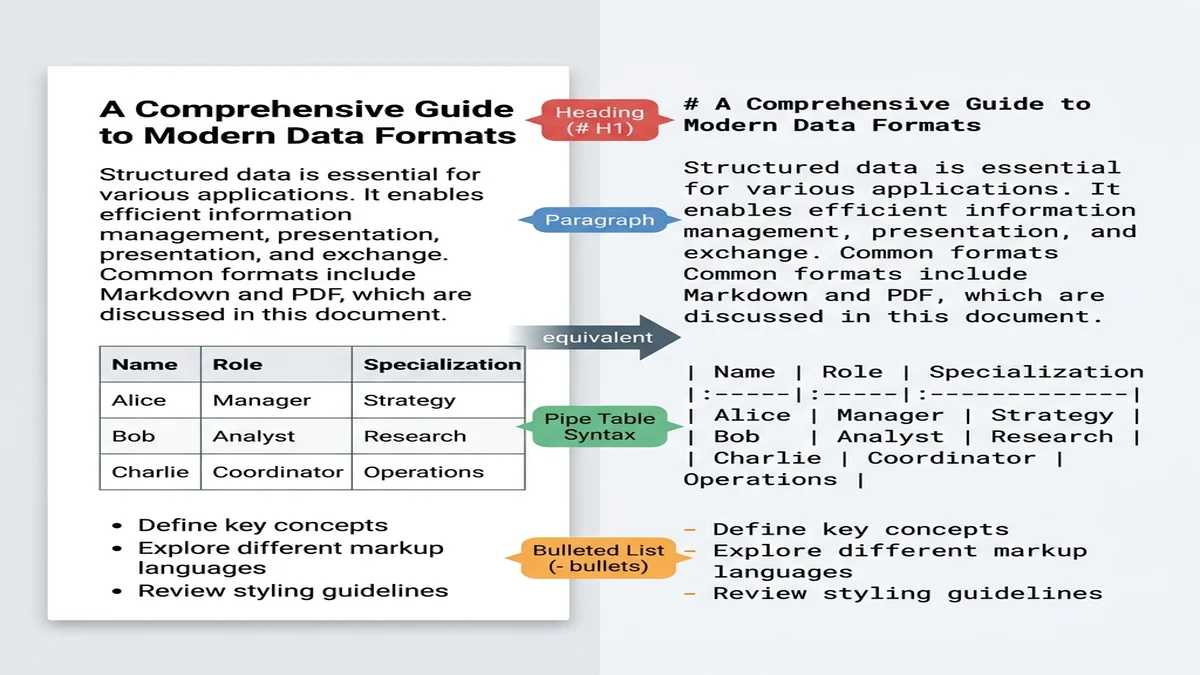
Markdown 比任何实用格式都更接近"结构化纯文本"。在 web 数据上训练出来的大模型见过几十亿份 markdown 文档(README 文件、Stack Overflow 回答、博客文章),不用提示也认得 # 是章节边界、| 是表格分隔。
把历史 PDF 迁到现代文档系统
Docusaurus、MkDocs、Astro Starlight、Hugo 都吃 markdown。如果你团队有 200 份内部 PDF 旧文档,你不会想搞复制粘贴大军 —— 你要的是一个能保留标题层级的转换器,让导航自己就能生成出来。
搭一个可搜索的第二大脑
Obsidian、Logseq、Foam、Roam —— 每个现代笔记应用都讲 markdown。把纸质档案数字化的学者、归档会议纪要的知识工作者、搭文献库的研究员,需要的都是同一件东西:一份标题完整的干净 markdown 文件,之后才能在几百份文档里用 grep 全文搜索。
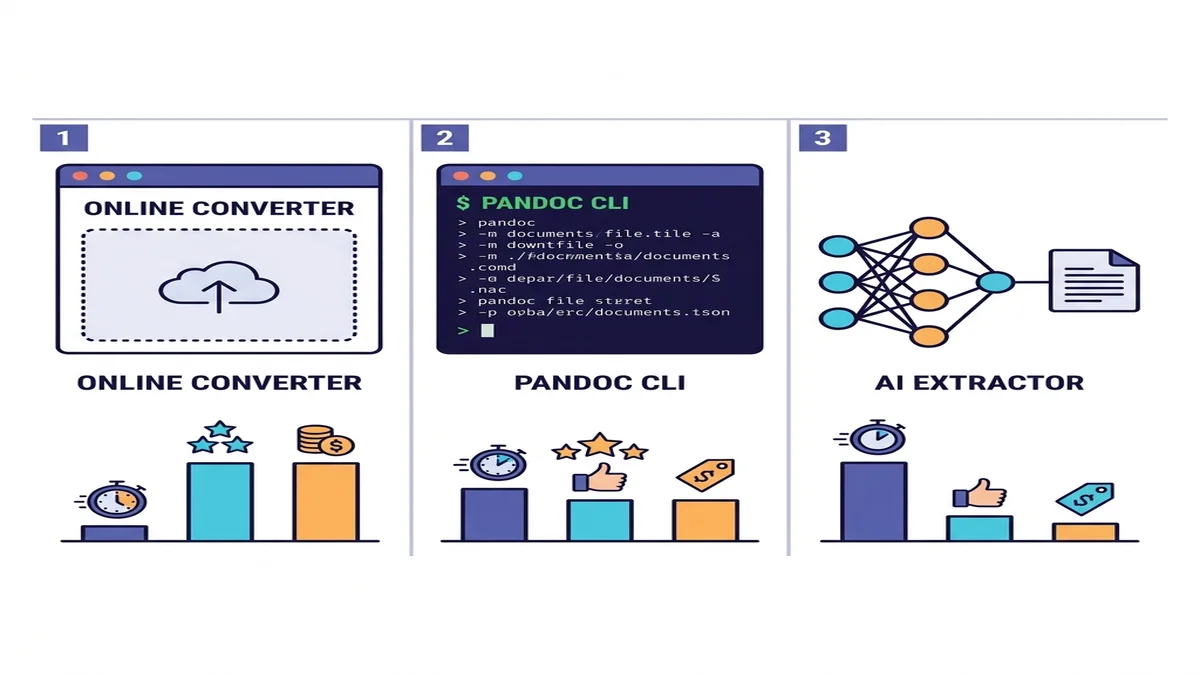
三种方法(什么时候用哪种)
工具有几十个,但真正只有三类。挑跟你情况匹配的那一行。
| 方法 | 速度 | 简单 PDF | 复杂 PDF | 扫描件 OCR | 安装成本 |
|---|---|---|---|---|---|
| 在线转换器 | 快 | 优秀 | 良好 | 内置或自动 | 无 |
| Pandoc + pdftotext | 快 | 良好 | 表格一般 | 不支持 | CLI 安装 |
| AI 提取器(marker / Docling) | 慢 | 优秀 | 优秀 | 支持 | Python + ML 依赖 |
拿不准选哪个,先试在线转换器。试一下就一分钟,对大多数一次性或小批量活儿基本就到头了。要做程序化流水线或者处理密集的学术内容,再往下选一行。完整对比看免费 Markdown 转换器盘点。
方法一:在线转 PDF 到 Markdown(免费、免安装)
最快的路径,也是大多数人跳过的,因为感觉太简单。但日常工作中绝大多数场景 —— 会议笔记、文章、单章节报告 —— 浏览器转换器就足够用了。
直接把文件拖到我们的免费 PDF 转 Markdown 转换器,本节剩下的就可以跳过。
一步步走
- 把 PDF 拖到上传区(或者点一下选文件)。
- 等几秒解析完。20 页以下基本上你刚读完这句话它就好了。
- 在右侧预览渲染后的 markdown 和源码对照。
- 复制源码,或者下载
.md文件。
就这样。无需账号、不要邮箱、输出没水印。
什么时候用最合适
- 一次性转换,不想安装任何东西。
- 决定要不要投入程序化流水线之前先抽样验证一下。
- 隐私敏感的文件,不想把文档推到第三方 API。我们的转换器在内存里处理文件,转完立即清除 —— 不做持久化存储。
局限
在线转换器普遍(不只是我们的)有两个失效场景需要知道。
第一个是非常大或非常特殊的 PDF。一份 600 页的扫描法律披露文件,带嵌入字体和动态表单字段,对任何工具都不是"拖一下就下载"的场景。碰到这种,跳到 AI 提取器那一节。
第二个是没有文字层的扫描 PDF。没有文本可以提取 —— 整页就是一张图。你得先 OCR;看下面的处理棘手内容一节。
方法二:命令行里的 Pandoc
Pandoc 是文档转换的瑞士军刀。当你需要一条可复现、可脚本化的流水线,又不想依赖网络服务时,这就是对的工具。
老实说有个坑:Pandoc 本身没有强力的 PDF 读取能力。社区的标准做法是走 pdftotext(Poppler 工具集里的),再把结果管道送进 Pandoc。
# 保留排版提取文本,再转成 GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
对于以文字为主的简单 PDF —— 一份备忘录、一篇单栏文章 —— 这个组合效果不错,毫秒级跑完。
在保真度上能撑多久
如果你的 PDF 大部分是散文,这条流水线能给你一份段落结构完整的干净 markdown。加上 -V 和 --wrap=none 参数,可以为下游不喜欢硬换行的工具调一下输出格式。
Pandoc 卡在哪里
- 多栏排版(学术论文、杂志):
pdftotext会把列交错穿插,结果完全没法读。 - 表格:除了最简单的双列网格,基本上输出是空格分隔的列,不是 markdown 管道符。
- 公式和代码块:没有语义保留;LaTeX 方程变成纯文本,代码等宽字体变成普通段落。
- 扫描 PDF:完全不支持 —— Pandoc/pdftotext 没法从图像里提取文字。
表格细节看扩展 Markdown 语法指南,里面讲了你想要的 GFM 表格格式。
方法三:AI 驱动的提取(marker、Docling、pymupdf4llm)
2024–2025 年涌现的版面感知提取器改变了能力边界。这类工具结合视觉版面检测、OCR 和结构化输出生成,能识别出这块区域是表格、那块区域是双栏正文。在复杂 PDF 上的输出干净得多。
三个值得知道的项目:
- marker —— 用 surya(一个版面模型)加启发式规则。在学术论文、公式和代码块上表现强。Apache 2.0 协议。
- Docling —— IBM Research 出品。表格重建做得出色,原生接入 LlamaIndex 和 LangChain。MIT 协议。
- pymupdf4llm —— PyMuPDF 的轻量封装。比前两个快,ML 依赖少,专门为 LLM 输入设计。
一个最小的 Python 例子
下面是最小可用的 Docling 流水线:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
或者用更轻量的 pymupdf4llm 路径:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
取舍
这类工具比 Pandoc 流水线慢。在普通 CPU 笔记本上,30 页论文要几十秒,不是几毫秒;有 GPU 的话 marker 能回到几秒级。pymupdf4llm 是三个里最快的,因为跳过了重型视觉模型。
另一个取舍是依赖体积。pip install marker-pdf 会拉下 PyTorch 和几百 MB 的模型权重。要打容器,预算体积要算上。
处理棘手内容
各种方法的差异,会在你不再拿干净的两页备忘录测试、开始跑真实 PDF 的时候立刻显现。
表格活不下来
表格是大多数转换器翻车的地方。pdftotext + Pandoc 这条路几乎永远只能产出空格对齐的"列汤",没有 markdown 渲染器能正确解析。在线转换器和 AI 提取器在这里表现好得多,因为它们先识别出表格区域,再重建单元格。
诀窍:信任剩下的之前,先抽查你的第一张表格输出。第一张就糟,后面 50 张也是一样。
数学公式和 LaTeX 块
如果你的 PDF 里有公式,你需要一个能识别公式区域、并在 markdown 里输出 LaTeX($$...$$)块的工具。marker 做得到;Pandoc 做不到。对科技写作来说,这是值得付出 AI 提取器速度代价的最大单一理由。
代码块和行内代码
很多 PDF 用等宽字体渲染代码,但在导出时丢了"这是代码"的语义标签。AI 提取器靠视觉风格 —— 等宽字体加缩进 —— 重新检测出代码区域,再用三反引号包起来。基于 Pandoc 的流水线通常会把代码压平回普通段落。
脚注和引用
学术论文用带编号的脚注,注文放在页面底部。pdftotext 这条路会丢掉引用标记和脚注正文之间的链接。Docling 和 marker 会保留它们为标准 markdown 脚注语法([^1] 引用 + [^1]: body 定义)。
扫描 PDF(必须 OCR)
扫描 PDF 是一张页面图片,不是文本。先 OCR,才有可提取的东西。

三条可靠路径:
-
ocrmypdf —— 给扫描 PDF 加一层不可见的 OCR 文字层,视觉外观完全不变。加完之后任何下游转换器都能用:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
带 OCR 模式的 AI 提取器 —— marker 和 Docling 能识别页面没有文字层,自动跑 OCR。输出是一体的,你拿到一份 markdown,不用中间再过一层 PDF。
-
带自动 OCR 的在线转换器 —— 部分浏览器工具(包括我们的,针对纯图 PDF)会透明地跑 OCR。方便,但如果你的文档不是英文,注意检查语言支持。
一个不那么明显的坑:"数字原生" PDF(从 Word 导出,不是扫描的)如果导出时压平成图像,也可能没有文字层。先在 PDF 阅读器里检查能不能选中文字。能选,跳过 OCR;不能选,就跑一遍。
为 RAG / LLM 输入准备 Markdown
如果终点是向量数据库,转换过程中的几个小选择能让下游的检索质量明显好很多。
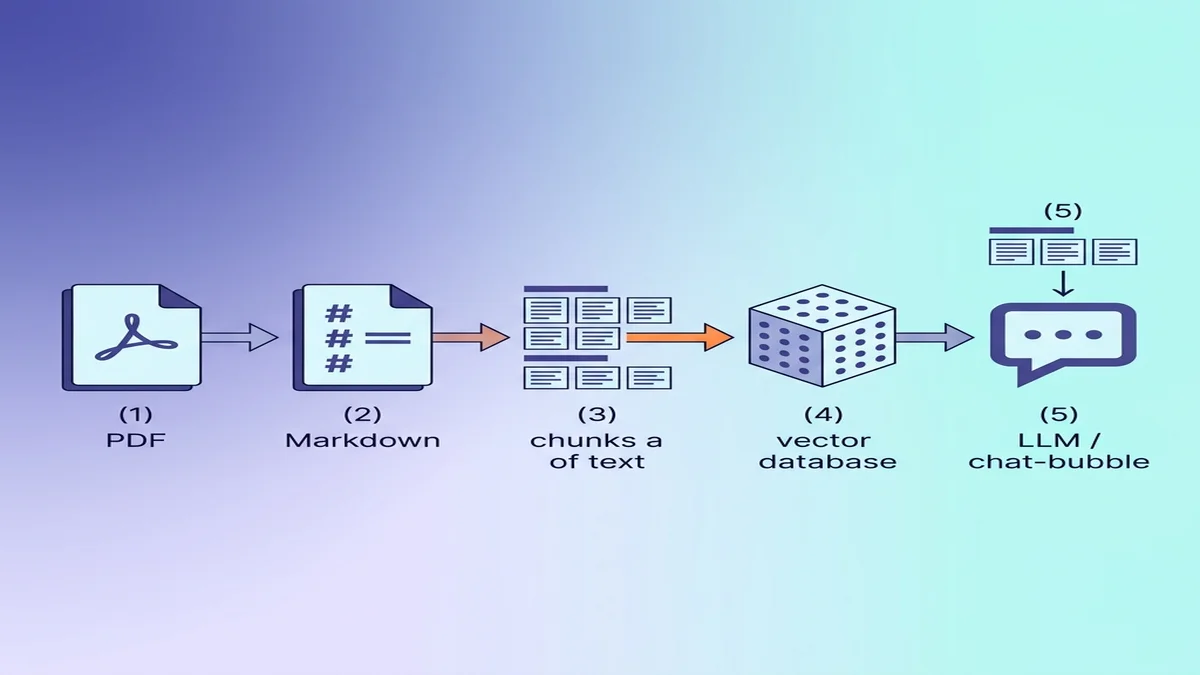
为什么 Markdown 对 LLM 比纯文本更好
Markdown 携带的结构是纯文本会丢失的。读到 ## Methods 的模型知道自己进入了新章节;读到同一段文字但格式全剥掉的模型,看到的只是权重相等的段落。如果你刚接触语法,基础 Markdown 指南 五分钟就能看完。
按标题层级切块
最常见的 RAG 错误是定长切块 —— 不管结构,把文档切成 500 token 的块。Markdown 让你能按语义切 —— 在 ## H2 边界切,得到的是连贯的章节,不是段落中间的碎片。
# 粗切:按 H2 切分
sections = markdown.split("\n## ")
# 现在每个 section 都从一个章节标题开始,包含它的子树
更好的做法:把标题作为一棵树来遍历,在每个 H3 的块元数据里挂上它的父 H2。
在 frontmatter 里保留元数据
在每份转换后的文件顶部加上 YAML frontmatter,让源信息跟着每个块走:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
LLM 检索到一个块时,这段元数据就成了引文落款。后面回答"这个说法是从哪儿来的?"也不用再跑一遍检索就有答案。如果你是从聊天记录搭这类流水线,同一个思路也适用于 ChatGPT/Claude 对话。
常见坑和怎么避开
第一次做这件事的人,有几个地方会被坑到。
- 跳过编码归一化。 PDF 喜欢 Unicode 小把戏:连字(
fi、fl)、智能引号("对")、长得像连字符的破折号。送进任何下游之前,先跑一遍 Unicode 归一化(Python 里的 NFKC)。 - 留着页眉页脚。 每页的
Page 4 of 12页脚都会变成检索里的噪音。把按规则出现的重复行剥掉。 - 相信看到的第一张表。 在认定其他都没问题之前,至少抽查前两张表。
- 以为"数字原生"就等于"有文字层"。 有些 PDF 哪怕起点是 Word 文档,导出时也会压平成图像。先尝试选中文字。
- 小文档过度切块。 一份 3 页的备忘录,直接把整篇 markdown 喂给模型就行,跳过 RAG。当上下文窗口 > 文档长度时,检索是多余的。
常见问题
最好的免费 PDF 转 Markdown 工具是哪个?
对大多数用户,在线转换器是最快的路径 —— 拖、放、完事。要做批量或程序化工作,pymupdf4llm(Python)和 Pandoc(CLI)能覆盖简单场景。学术论文里有表格和公式,marker 和 Docling 输出明显更好。"最好"取决于你优化的是上手时间还是输出保真度。
ChatGPT 或 Claude 能把 PDF 转成 Markdown 吗?
能,但有前提。两者都能直接读 PDF 并输出 markdown,但长文档容易撞上下文上限,表格和公式的准确率每次跑出来还会有差异。要确定性的批量转换,专用转换器更可靠。关联场景看ChatGPT 导出到 Word/PDF/HTML。
扫描 PDF 怎么转 Markdown?
先 OCR。最干净的路径是 ocrmypdf 加一层文字层,再用任何转换器跑 OCR 后的 PDF。或者,marker 和 Docling 内置了 OCR,能直接把纯图 PDF 输出成 markdown。
在线 PDF 转 Markdown 隐私安全吗?
用我们的转换器,文件在内存里处理,转完清除 —— 不要账号、不做持久化存储。其他服务做法各异;用任何工具之前都检查一下它的隐私政策,机密文档尤其如此。
转换时怎么让表格不散架?
表格密集的 PDF 跳过 pdftotext + Pandoc 流水线 —— 它几乎永远把表格搞砸。用一个能输出 GFM 表格的在线转换器,或者用 marker、Docling 这类 AI 提取器。不管走哪条路,前几张表都要抽查。
是只留 Markdown 还是同时留原 PDF?
两个都留。Markdown 是给输入、搜索和编辑用的。PDF 是引用和审计的"事实之源"。在 markdown 的 frontmatter 里写上 PDF 文件名和页码范围,这样任何说法都能反查回源。
准备转你的第一份 PDF 了吗?
如果你只想拿到结果,我们的免费 PDF 转 Markdown 转换器免注册搞定日常场景。下一步 —— 把 markdown 变成精致的 Word 文档或可分享 PDF —— 看我们的 Markdown 转 Word 指南。
参考资料
- Pandoc 用户指南 —— 命令行转换的权威参考。
- GitHub Flavored Markdown 规范 —— 本指南输出目标的方言。
- Docling(IBM Research) —— 开源的版面感知 PDF 提取器。
- marker —— 开源 PDF 转 markdown,学术论文处理强。
- pymupdf4llm —— PyMuPDF 的轻量 markdown 提取封装。
- OCRmyPDF —— 给扫描 PDF 加可搜索文字层。