Chuyển Word sang Markdown: Hướng dẫn di chuyển tài liệu 2026
Chuyển tài liệu Word sang Markdown sạch cho Git và Obsidian. Phương pháp đã kiểm chứng trên file DOCX, kèm cách sửa bảng, danh sách và ảnh nhúng.

Yêu cầu thường đến nghe rất đơn giản: "Bạn chuyển giúp mấy file Word này vào wiki của team được không?"
Bạn mở ổ đĩa chia sẻ. Ba trăm file .docx. Cả một thập kỷ tài liệu nội bộ — chính sách, runbook, biên bản họp, spec — nằm rải rác trong các thư mục đặt tên không nhất quán. Không diff được. Không search được tử tế. Và ai đó vừa quyết định toàn bộ đống này phải chuyển sang Markdown quản lý bằng Git trước cuối quý.
Mình đã làm hai lần migration kiểu này. Một lần cho kho tài liệu compliance (khoảng 200 file), một lần cho knowledge base của team engineering (khoảng 500 file). Cả hai lần bài học đều giống nhau: chuyển Word sang Markdown không phải thao tác một cú click. Đó là một pipeline — chuyển đổi, kiểm tra, dọn dẹp — và bước dọn dẹp mới là nơi ngốn nhiều thời gian nhất.
Bài viết này nói về những gì thực sự hoạt động: ba phương pháp chuyển đổi đáng biết, tính năng nào của Word sống sót qua quá trình chuyển (và tính năng nào âm thầm biến mất), cùng checklist hậu chuyển đổi giúp bạn tiết kiệm hàng giờ sửa tay.
Tại sao cần chuyển tài liệu Word sang Markdown?
Trước khi bàn về cách làm, hãy nói một chút về lý do. Vì nếu team bạn chưa trả lời rõ câu hỏi này, việc migration sẽ không trụ được lâu.
- Lịch sử diff được. File
.docxcủa Word thực chất là một gói XML nén. Với Git, hai phiên bản trông như hai khối binary ngẫu nhiên. Markdown là văn bản thuần — mỗi thay đổi là một diff dễ đọc. - Search và grep. Lệnh
rg "incident response" docs/chạy trong vài mili giây qua hàng ngàn file Markdown. Làm điều tương tự với tài liệu Word thì cần công cụ tìm kiếm độc quyền. - Tự động hóa. Markdown có thể được tiêu thụ bởi static site generator, công cụ tài liệu (Docusaurus, MkDocs, Nextra), pipeline ingestion cho LLM, hệ thống CI và linter. Word thì gần như chỉ Word đọc được.
- Tuổi thọ. File text thuần sống lâu hơn các hãng phần mềm. DOCX hiện tại vẫn ổn định, nhưng khả năng tương thích với
.doc(định dạng binary cũ) đã bắt đầu lung lay.
Nếu team của bạn không dính vấn đề nào ở trên, có lẽ bạn chưa cần migrate. Nếu dính dù chỉ một cái, bạn đang ở đúng chỗ rồi.
Cái gì giữ được sau khi chuyển, cái gì mất
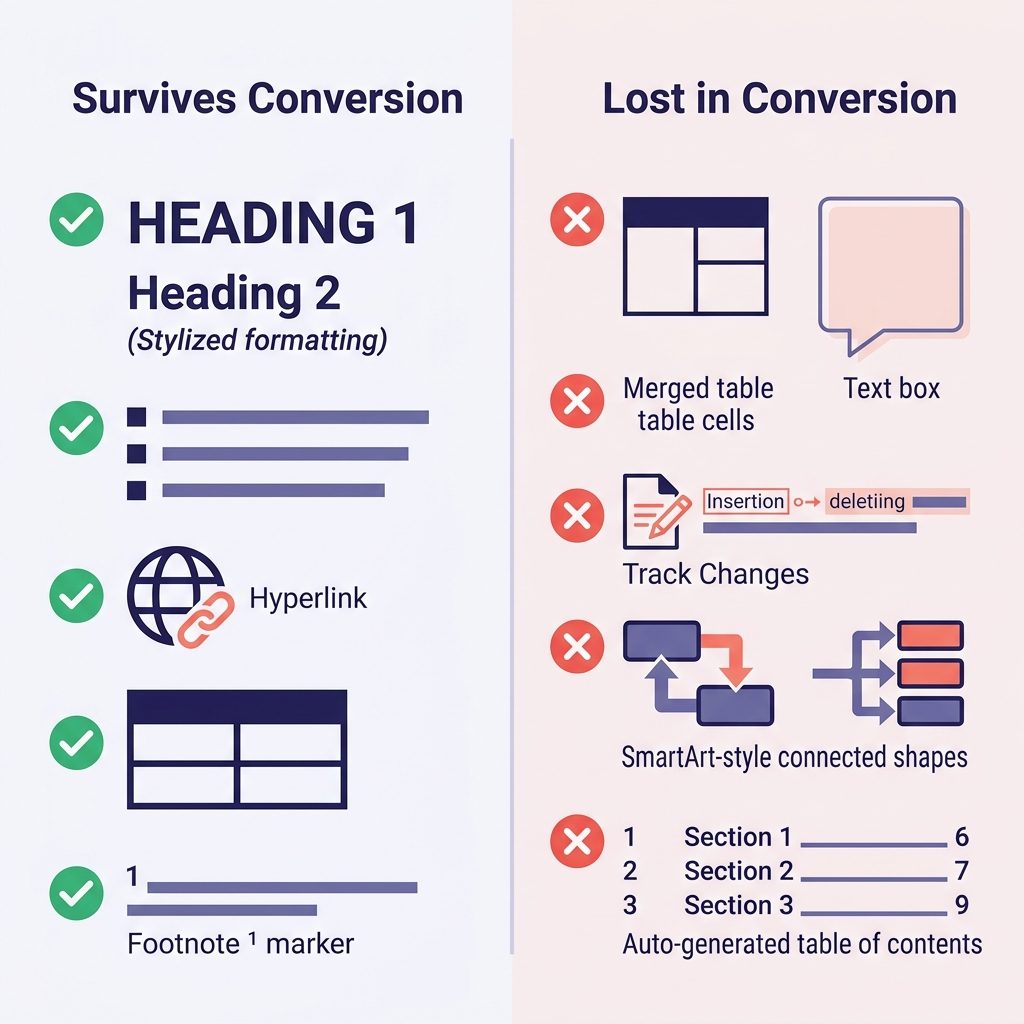
Đặt kỳ vọng đúng từ đầu là cách tiết kiệm thời gian nhất. Đây là những gì mình quan sát được qua hàng trăm lần chuyển đổi:
| Tính năng Word (Word Feature) | Có giữ được? | Ghi chú |
|---|---|---|
| Heading (Heading 1–6 style) | Có | Map trực tiếp sang # đến ###### |
| Bold, italic, underline | Bold/italic: có | Underline không có tương đương trong Markdown (bị đổi thành italic hoặc thẻ HTML <u>) |
| Danh sách bullet và numbered | Thường được | Các mức lồng sâu đôi khi bị san phẳng |
| Hyperlink | Có | Giữ cả URL lẫn anchor text |
| Bảng (Table) | Bảng đơn giản: có | Ô gộp (merged cells), màu ô, viền đều mất |
| Ảnh nhúng (Inline image) | Có | Được trích xuất ra thư mục; link ảnh được viết lại |
| Footnote | Có (GFM) | Chuyển sang cú pháp [^1] |
Code (nếu style paragraph là Code) | Tùy | Thường bị san phẳng thành text thường, mất fence |
| Công thức toán (Math equation) | Một phần | Có thể chuyển sang LaTeX; đôi khi bị san phẳng |
| Track Changes | Không | Phải accept hoặc reject hết trước |
| Comment | Không | Resolve hoặc export riêng trước khi chuyển |
| Text box, SmartArt, shape | Không | Mất sạch — thay bằng ảnh hoặc text thường trước |
| Table of Contents tự sinh | Không | Phải tạo lại bằng công cụ docs của bạn |
| Word field (ngày, cross-reference) | Không | Chuyển sang text thường trước khi export |
Hai bất ngờ lớn nhất trong migration thường là: (1) phần format trông giống heading nhưng thực ra chỉ là bold tay cộng với cỡ chữ to — chúng bị chuyển thành text in đậm bình thường và output của bạn không có cấu trúc; và (2) bảng có ô gộp bị sụp đổ theo những cách nhìn rất xấu và phải dựng lại tay.
Trước khi chạy batch convert, hãy lướt qua mười tài liệu nguồn ngẫu nhiên và đánh dấu các vấn đề này. Mất khoảng ba mươi phút và tránh được rất nhiều việc phải làm lại.
Cách 1: Công cụ chuyển đổi trực tuyến
Đây là cách mình khuyên dùng cho file đơn lẻ và batch nhỏ (dưới khoảng 50 tài liệu). Đây là đường ngắn nhất từ .docx sang Markdown sạch, không cần cài đặt gì.
- Mở công cụ chuyển Word sang Markdown của bọn mình
- Kéo file
.docxvào vùng upload - Xem trước Markdown đã chuyển
- Tải file
.mdvề máy (ảnh được đóng gói riêng khi có)
Output dùng GitHub Flavored Markdown (GFM), nên bảng, task list và footnote đều được giữ. Heading map sang các cấp #, danh sách giữ nguyên hierarchy, và hyperlink giữ lại anchor text.
Một điểm đáng lưu ý: với tài liệu thông thường, toàn bộ quá trình chuyển đổi diễn ra trong trình duyệt. Với file rất lớn hoặc khi bạn xử lý nội dung nhạy cảm, việc file không rời máy bạn là một tính năng thật sự có giá trị, không chỉ là câu quảng cáo.
Hạn chế của bất kỳ công cụ online nào (của bọn mình hay bên khác) đều giống nhau: xử lý hàng loạt không phải thế mạnh, và bạn không thể script nó vào một pipeline. Với những trường hợp đó, hãy sang Cách 2.
Cách 2: Pandoc (Cho xử lý hàng loạt và script)
Pandoc là trình chuyển đổi tài liệu đa năng. Đây là công cụ mình dùng khi xử lý nhiều hơn vài file, hoặc khi cần tinh chỉnh output.
Lệnh cơ bản
pandoc document.docx -o document.md
Với một file đơn lẻ thì chỉ cần thế. Lệnh chạy nhanh, output dễ đọc, xử lý được hầu hết các tính năng Word phổ biến. Nhưng Pandoc thể hiện giá trị thật khi bạn thêm các flag.
Ba flag đáng biết
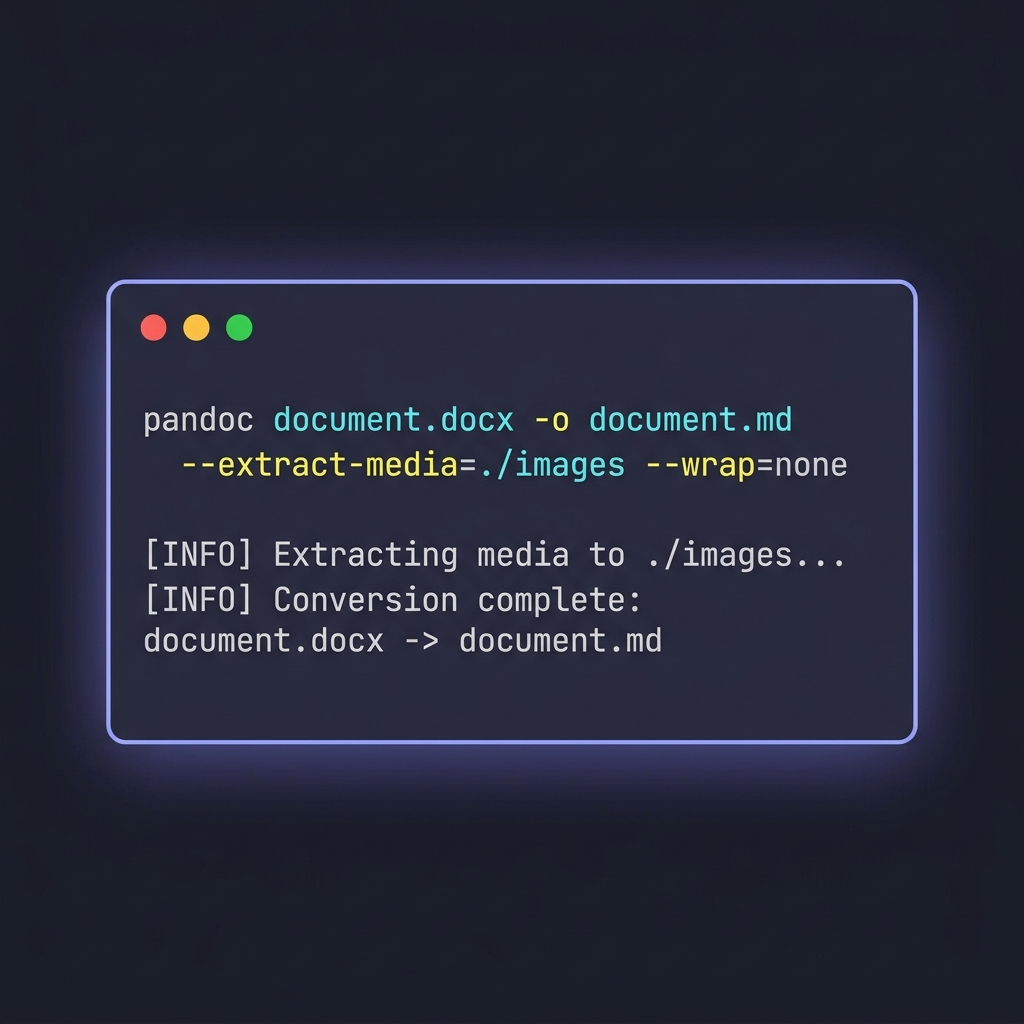
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— kéo ảnh nhúng trong DOCX ra một thư mục riêng, đồng thời viết lại link ảnh trong output. Không có flag này, ảnh inline sẽ âm thầm biến mất.--wrap=none— ngăn Pandoc wrap cứng dòng ở khoảng 80 ký tự. Điều này quan trọng vì hard wrap phá độ đọc của Git diff với tài liệu nhiều văn xuôi.--markdown-headings=atx— ép dùng cú pháp# Headingthay vì kiểu setext cũ (dòng gạch dưới bằng====). ATX mới là chuẩn hiện đại.
Chuyển cả thư mục
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
Bỏ đoạn này vào shell script là bạn có thể xử lý hàng trăm file trong vài phút. Với kho lớn hơn, thêm trap và logging để có thể tiếp tục được nếu chạy giữa chừng bị crash.
Vài lỗi thực tế cần để ý
- Ký hiệu bullet không đồng nhất. Pandoc khi thì dùng
-, khi thì dùng*. Nếu bạn quan tâm đến tính nhất quán, chạysed -i 's/^\* /- /g'trên output, hoặc cấu hình formatter Markdown của editor. - Numbered list tự động restart. Word thường có directive "continue numbering" mà Pandoc không đọc được. Bạn sẽ thấy list đếm
1, 2, 1, 2, 3dù bản gốc trông liền mạch. Sửa bằng một pass review nhanh là được. - Bảng có ô dài bị vỡ layout. Pandoc đã cố hết sức, nhưng bảng GFM không hỗ trợ line break trong ô như Word. Với những bảng cực phức tạp, cân nhắc chuyển tay sang khối HTML.
Pandoc không có GUI, vừa là nhược điểm (đồng đội không rành kỹ thuật không chạy được) vừa là ưu điểm (script được vào bất kỳ pipeline CI/CD nào).
Cách 3: Chuyển đổi bằng lập trình với Mammoth.js
Nếu bạn đang dựng pipeline — ví dụ script migration kéo file DOCX từ SharePoint, chuyển đổi, rồi commit vào Git — thì web UI hay gọi subprocess đến Pandoc có khi không hợp stack của bạn. Mammoth.js là một thư viện JavaScript chuyển DOCX sang HTML hoặc Markdown sạch trực tiếp trong Node.js.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // the Markdown output
console.log(result.messages); // warnings about unsupported features
});
Điểm hữu ích của Mammoth nằm ở quan điểm rõ ràng của nó: bỏ qua hoàn toàn styling hình thức của Word và tập trung vào cấu trúc ngữ nghĩa (heading, list, table). Output sạch hơn Pandoc mặc định, đổi lại ít tùy chỉnh hơn. Để migrate một kho tài liệu cũ nơi đa số doc có cấu trúc đồng đều, mình sẽ dùng Mammoth. Với tài liệu đặc thù, format nặng, thì tính linh hoạt của Pandoc thắng.
Người dùng Python có lựa chọn tương tự với python-docx kết hợp một writer Markdown, tuy nhiên đó thiên về hướng tự dựng hơn là công cụ sẵn dùng.
Bước dọn dẹp mà không ai cảnh báo bạn

Việc chuyển đổi đưa bạn đến một file .md. Nó không đưa bạn đến một file .md mà bạn muốn commit.
Đây là checklist chuẩn của mình sau chuyển đổi. Khi đã quen, mỗi tài liệu chỉ mất khoảng năm phút:
- Quét các heading bị bỏ sót cấu trúc. Tìm trong output các dòng trông như heading nhưng thực ra là
**Bold Text**đứng riêng một dòng. Người viết đã tự tay bôi đậm trong Word thay vì dùng Heading style. Nâng chúng lên thành heading##thật sự. - Kiểm tra bảng đầu tiên. Nếu bảng đầu đúng, đa số bảng sau sẽ đúng. Nếu bảng đầu vỡ, cả đống đều vỡ.
- Xóa dòng trống trong list item. Pandoc đôi khi chèn dòng trống làm đứt mạch list.
- Verify link ảnh. Mở file bằng Markdown preview (VS Code tích hợp sẵn là đủ) và xác nhận ảnh load được.
- Search các artifact lạc. Hay gặp:
\cuối dòng (hard line break Word ẩn nhưng Markdown hiện), thuộc tính style{.underline}, thẻ<span>lọt qua. - Kiểm 10 dòng đầu và 10 dòng cuối. Header, footer, số trang của Word hay rò vào output dưới dạng nội dung trống hoặc artifact kỳ lạ.
Với migration quy mô lớn, tự động hóa mục 5 và 6 bằng script dọn dẹp. Phần còn lại vẫn cần mắt người — ít nhất cho đến khi bạn xây được đủ pattern recognition để tin output với một loại tài liệu cụ thể.
Một lần migration thật: Kho compliance 200 file
Đây là workflow mình đã dùng cho lần migration kho compliance. Tính từ đầu đến cuối là hai ngày làm việc cho 200 file.
Sáng Ngày 1: Triage nguồn
Viết một script Python mở từng DOCX, đếm heading, ảnh, bảng, và đánh dấu file nào còn bật Track Changes hoặc có comment. Output là một CSV sắp xếp file theo độ phức tạp. Mục tiêu không phải là sửa gì, chỉ để biết mình đang đâm đầu vào cái gì.
Chiều Ngày 1: Batch convert các file đơn giản
Khoảng 140 trong số 200 file là loại đơn giản: không ảnh, bảng đơn giản, cấu trúc heading sạch. Chạy Pandoc trong vòng lặp với --extract-media và --wrap=none. Spot-check 20 mẫu ngẫu nhiên. Đều ổn.
Sáng Ngày 2: Xử lý từng file phức tạp
60 file còn lại có vấn đề — ô bảng gộp, object spreadsheet nhúng, hoặc lịch sử Track Changes dày mà có người phải review trước. Với những file này, mình dùng công cụ trực tuyến theo từng trường hợp, đôi khi chạy Pandoc với flag khác nhau, đôi khi dọn file DOCX gốc trước.
Chiều Ngày 2: Dọn dẹp và commit
Chạy script dọn dẹp trên cả 200 file đã chuyển (xóa artifact {.underline}, chuẩn hóa ký hiệu bullet, sửa output line-wrap của Pandoc). Review diff, commit theo đợt 50 file, push lên nhánh migration.
Nếu thử làm tay — mở từng file Word và paste sang editor Markdown — thì chắc chắn mất ít nhất hai tuần. Công cụ chuyển đổi không phải tùy chọn; chúng là thứ biến dự án này thành khả thi.
Lỗi thường gặp và cách khắc phục
Bảng hiển thị sai trong Markdown preview
Chín mươi phần trăm lỗi là do nguồn có ô gộp hoặc ô chứa nội dung rất dài. Bảng GFM không hỗ trợ tốt cả hai. Lựa chọn của bạn: dựng lại bảng thủ công theo GFM, dùng khối <table> HTML bên trong Markdown (đa số renderer hỗ trợ), hoặc tách bảng thành nhiều bảng đơn giản hơn.
Ảnh không hiện
Kiểm tra xem converter có trích xuất ảnh ra không. Pandoc sẽ không làm trừ khi bạn dùng --extract-media. Converter online thường tải về một file zip chứa Markdown kèm thư mục images/ — đảm bảo cả hai ở đúng chỗ và đường dẫn ảnh trong Markdown khớp.
Output có dấu backslash lạ ở cuối dòng
Đó là hard line break từ Word mà Markdown render thành ngắt dòng cưỡng bức. Nếu file Word gốc dùng dày đặc line break thay vì paragraph break để tạo khoảng cách, Pandoc sẽ giữ nguyên chúng. Một lần find-and-replace cho \\$ (cuối dòng) thường đủ sạch.
Cấp heading sai sau khi chuyển
Tài liệu Word thường bắt đầu từ Heading 2 hoặc Heading 3 (vì Heading 1 được giữ cho trang bìa). Quy ước Markdown là bắt đầu từ # (H1). Tùy hệ thống docs của bạn hiển thị heading thế nào, có thể cần nâng toàn bộ cấp lên một bậc. sed làm được: sed -i 's/^## /# /; s/^### /## /; ...' file.md.
Markdown nhìn chẳng giống tài liệu Word về hình thức
Điều này là bình thường. Markdown mô tả cấu trúc, không phải hình thức. Styling đến từ hệ thống render Markdown (GitHub, trang docs của bạn, theme MkDocs, v.v.). Nếu độ chính xác hình ảnh là yếu tố sống còn, PDF là đích đến tốt hơn — xem hướng dẫn chuyển Markdown sang PDF để tìm workflow giữ thiết kế hình ảnh.
Round-trip: Markdown quay lại Word
Một câu hỏi tự nhiên sau migration: "Nếu mình cần gửi file Markdown lại cho stakeholder chỉ mở được Word thì sao?" Đó là chiều ngược lại — và là thao tác sạch hơn nhiều, vì hạn chế vốn có của Markdown có nghĩa là ít thứ phải dịch chuyển hơn. Hướng dẫn Markdown sang Word cover luồng đó.
Với team nhảy qua lại giữa hai định dạng thường xuyên, workflow mình thấy chạy tốt là: Markdown là nguồn sự thật trong Git, bản Word được export khi có người cần review hoặc chú thích. Không bao giờ có chuyện edit trong Word rồi merge ngược lại — nhờ vậy, công migration không bị tháo tung dần theo thời gian.
Kết lại
Chuyển Word sang Markdown là một cuộc migration, không phải cú bấm nút. Công cụ lo phần nặng — công cụ trực tuyến của bọn mình cho file lẻ, Pandoc cho batch, Mammoth.js cho pipeline — nhưng công việc thật nằm ở khâu inspect trước và cleanup sau khi chuyển.
Hai pattern tiết kiệm nhiều thời gian nhất:
- Triage trước. Hiểu trong kho nguồn có gì trước khi bắt đầu chuyển. Mười lăm phút sampling giúp tránh hàng giờ phản ứng với bất ngờ.
- Lường trước việc dọn dẹp. Dự trù năm phút mỗi tài liệu cho pass review-and-polish. Xem đây là bước không thể tránh giúp bạn ước lượng thời gian migration trung thực hơn.
Nếu bạn mới làm quen với Markdown và muốn biết output sẽ trông như thế nào, bắt đầu với Markdown là gì và hướng dẫn cú pháp cơ bản. Với các tính năng nâng cao — bảng, footnote, task list — tài liệu cú pháp mở rộng cover những gì GFM hỗ trợ.
Và nếu migration của bạn xuất phát từ Obsidian thay vì Word, hướng dẫn xuất file Obsidian xử lý luồng đó trọn vẹn từ đầu đến cuối.