Как конвертировать PDF в Markdown в 2026 (бесплатно и под RAG)
Конвертируем PDF в Markdown правильно в 2026. Сравнение бесплатных онлайн-инструментов, Pandoc и ИИ-экстракторов — с workflow под RAG и решением проблем OCR.

Если вы когда-нибудь копировали абзац из PDF и наблюдали, как он рассыпается в кашу из переносов строк, разорванных дефисов и потерянного форматирования, — вы уже знаете, почему конвертация PDF в Markdown превратилась в 2026 году в серьёзную рабочую задачу.
PDF — универсальная валюта для обмена документами. И одновременно — отвратительный исходный формат. Как только вы захотите подать этот контент в RAG-пайплайн, добавить на сайт документации или просто сохранить в заметках, вам понадобится структурированный текст: заголовки как заголовки, таблицы как таблицы, код как код.
В этом руководстве — три честных способа конвертировать PDF в Markdown: онлайн-конвертер без установки, Pandoc в командной строке и новая волна ИИ-экстракторов вроде marker и Docling. Покажу, какой выбрать под какую задачу, как чинить то, что они ломают (таблицы, формулы, сканированные страницы), и как довести результат до LLM-пайплайна без двойной чистки.
Зачем конвертировать PDF в Markdown?
Одна и та же задача конвертации всплывает в трёх разных сообществах. У каждого свой повод, но целевой формат один.
Подача чистого текста в RAG и LLM-пайплайны
Пайплайны retrieval-augmented generation не любят сырой PDF-текст. Артефакты разрывов страниц, двухколоночная вёрстка, схлопнутая в одну колонку, повторяющиеся колонтитулы — всё это становится шумом в векторной базе и портит retrieval.
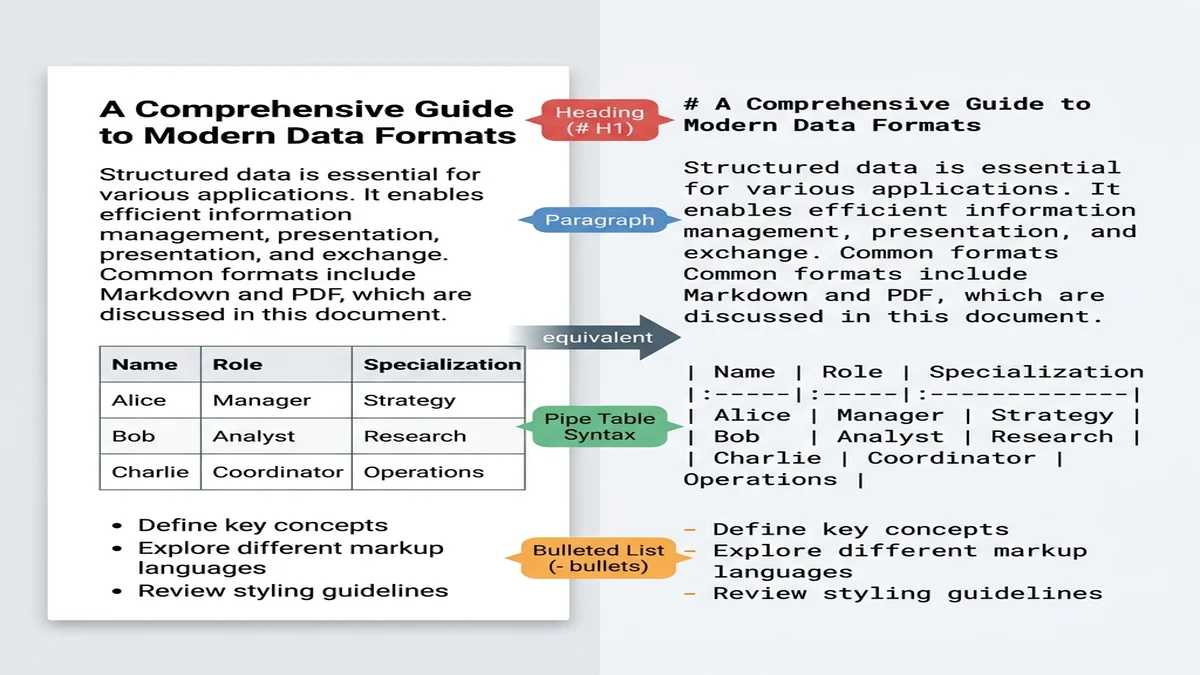
Markdown ближе всех практических форматов к «структурированному простому тексту». Крупные модели, обученные на веб-данных, видели миллиарды markdown-документов (README-файлы, ответы Stack Overflow, посты блогов), поэтому распознают # как границы секций и | как разделители таблиц без дополнительных подсказок.
Миграция старых PDF в современные системы документации
Docusaurus, MkDocs, Astro Starlight и Hugo — все ждут markdown. Если у команды 200 PDF со старой внутренней документацией, никакая армия копипастеров вам не нужна — нужен конвертер, сохраняющий иерархию заголовков, чтобы навигация собиралась сама.
Сборка поискового «второго мозга»
Obsidian, Logseq, Foam, Roam — все современные приложения для заметок говорят на markdown. Учёные, оцифровывающие бумажные архивы, knowledge-работники, складывающие отчёты со встреч, и исследователи, собирающие литературные библиотеки, — всем нужно одно и то же: чистый markdown-файл с целой структурой заголовков, чтобы потом grep работал по сотням документов.
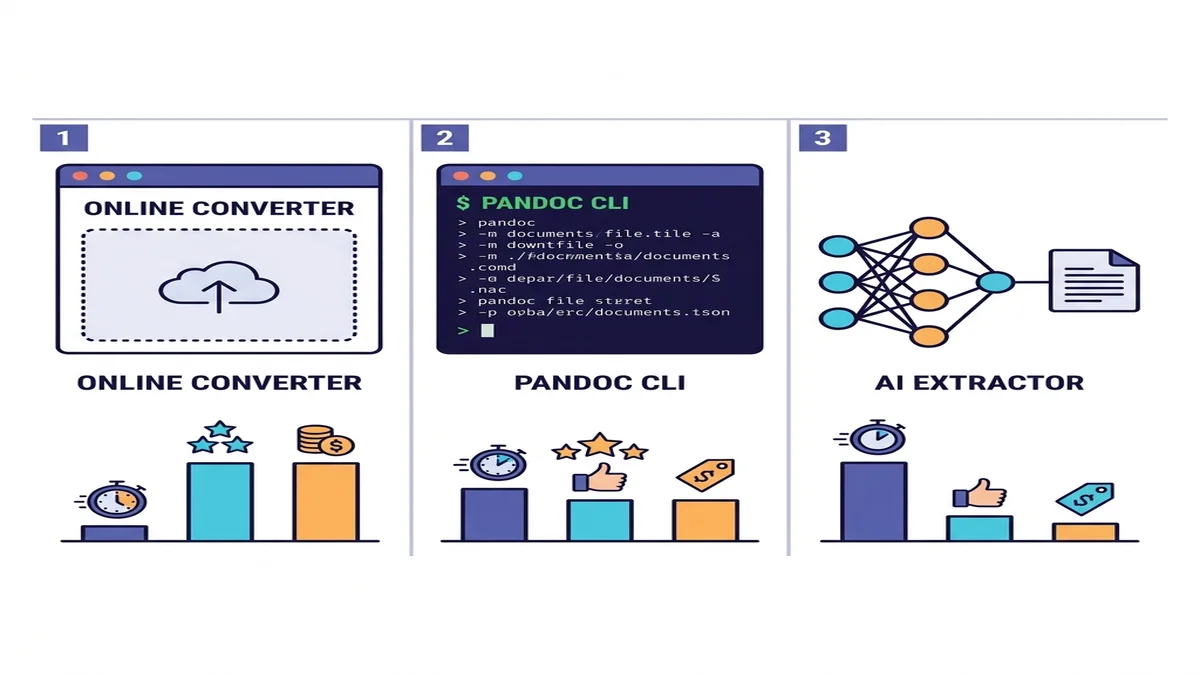
Три подхода (когда какой выбирать)
Инструментов десятки, но категорий по сути три. Выбирайте строку под свою ситуацию.
| Метод | Скорость | Простые PDF | Сложные PDF | OCR для сканов | Установка |
|---|---|---|---|---|---|
| Онлайн-конвертер | Быстро | Отлично | Хорошо | Встроено или автоматически | Не нужна |
| Pandoc + pdftotext | Быстро | Хорошо | Средне на таблицах | Нет | CLI-установка |
| ИИ-экстрактор (marker / Docling) | Медленно | Отлично | Отлично | Да | Python + ML-зависимости |
Если сомневаетесь — начните с онлайн-конвертера. Минута на попытку, и для большинства разовых или малых задач на этом история заканчивается. Для программных пайплайнов или плотного академического контента — спускайтесь строкой ниже. Более широкую картину рынка мы разбирали в нашем обзоре бесплатных конвертеров Markdown.
Метод 1. Онлайн-конвертация PDF в Markdown (бесплатно, без установки)
Самый быстрый путь — тот, который большинство пропускает, потому что он кажется слишком простым. Для подавляющей доли повседневных задач — заметки со встреч, статьи, отчёты в одну главу — браузерного конвертера более чем достаточно.
Можно сразу закинуть файл в наш бесплатный конвертер PDF в Markdown и пропустить остаток раздела.
Пошаговый workflow
- Перетащите PDF в зону загрузки (или кликните и выберите файл).
- Подождите несколько секунд, пока парсер закончит. Документ до 20 страниц обычно конвертируется быстрее, чем вы дочитываете эту фразу.
- Сравните отрендеренный markdown с исходником справа.
- Скопируйте исходник или скачайте
.md-файл.
И всё. Без аккаунтов, email-стен и водяных знаков.
Когда это лучший выбор
- Разовые конвертации, когда ничего ставить не хочется.
- Быстрая проверка перед тем, как вкладываться в программный пайплайн.
- Чувствительные к приватности файлы, которые не хочется отдавать в чужой API. Наш конвертер обрабатывает файлы в памяти и сразу же их удаляет — никакого постоянного хранения.
Ограничения
У онлайн-конвертеров вообще (не только у нашего) есть два известных режима отказа.
Первый — очень большие или нетипичные PDF. 600-страничное сканированное юридическое раскрытие со встроенными шрифтами и динамическими полями формы — не сценарий «перетащил и скачал» ни для одного инструмента. Если у вас такой случай — переходите к разделу про ИИ-экстракторы.
Второй — сканированные PDF без текстового слоя. Извлекать просто нечего — страница это картинка. Сначала нужен OCR; см. Сложный контент ниже.
Метод 2. Pandoc в командной строке
Pandoc — швейцарский нож конвертации документов. Это правильный выбор, когда нужен воспроизводимый скриптуемый пайплайн и нет желания зависеть от веб-сервиса.
Честная оговорка: у самого Pandoc нет сильного PDF-ридера. Сложившийся в сообществе workflow идёт через pdftotext (из утилит Poppler) и передаёт результат в Pandoc по пайпу.
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
Для простого текстового PDF — служебная записка, статья в одну колонку — связка работает хорошо и отрабатывает за миллисекунды.
Когда важна точность
Если PDF в основном прозаический, этот пайплайн даёт чистый markdown с сохранённой структурой абзацев. Добавьте флаги -V и --wrap=none, чтобы подстроить вывод под инструменты, не любящие жёсткий перенос строк.
Где Pandoc буксует
- Многоколоночная вёрстка (научные статьи, журналы):
pdftotextперемешивает колонки, и на выходе получается нечитаемая каша. - Таблицы: всё сложнее простейшей двухколоночной сетки обычно приходит как столбцы, разделённые пробелами, а не markdown-pipe.
- Формулы и кодовые блоки: семантика не сохраняется; LaTeX-уравнения превращаются в текст, моноширинный код — в обычные абзацы.
- Сканированные PDF: нулевая поддержка — Pandoc/pdftotext не умеют извлекать текст из изображений.
Конкретно по таблицам: наше руководство по расширенному синтаксису Markdown описывает GFM-формат таблиц, под который стоит подгонять вывод.
Метод 3. ИИ-экстракция (marker, Docling, pymupdf4llm)
Волна layout-aware-экстракторов 2024–2025 годов изменила границы возможного. Эти инструменты сочетают визуальное распознавание макета с OCR и генерацией структурированного вывода — то есть понимают, что вот этот регион — таблица, а вот тот — двухколоночный основной текст. Результат на сложных PDF получается заметно чище.
Три проекта, о которых стоит знать:
- marker — использует surya (модель макета) плюс эвристики. Силён на научных статьях, формулах и кодовых блоках. Лицензия Apache 2.0.
- Docling — от IBM Research. Отличная реконструкция таблиц, нативная интеграция с LlamaIndex и LangChain. Лицензия MIT.
- pymupdf4llm — лёгкая обёртка над PyMuPDF. Быстрее остальных двух, меньше ML-зависимостей, изначально заточен под подачу в LLM.
Минимальный пример на Python
Вот самый короткий полезный пайплайн на Docling:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
Или вариант полегче — pymupdf4llm:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
Компромиссы
Эти инструменты медленнее, чем пайплайн на Pandoc. На обычном CPU-ноутбуке 30-страничная статья займёт десятки секунд, а не миллисекунды; на GPU marker возвращается к нескольким секундам. pymupdf4llm — самый быстрый из трёх, потому что обходит тяжёлые vision-модели.
Второй компромисс — вес зависимостей. pip install marker-pdf тянет PyTorch и несколько сотен мегабайт весов модели. Если упаковываете это в контейнер — заложите размер заранее.
Сложный контент
Различия между методами становятся очевидными, когда вы перестаёте гонять чистые двухстраничные служебки и начинаете прогонять реальные PDF.
Таблицы, которые не выживают
Таблицы — место, где большинство конвертеров спотыкается. Связка pdftotext + Pandoc почти всегда выдаёт пробельную «колонную кашу», которую ни один markdown-рендерер не разберёт корректно. Онлайн-конвертеры и ИИ-экстракторы тут справляются заметно лучше: они сперва находят регион таблицы и только потом восстанавливают ячейки.
Правило: проверьте первую таблицу до того, как доверять остальным. Если первая искорёжена — остальные 50 будут такими же.
Формулы и LaTeX-блоки
Если в PDF есть уравнения, нужен инструмент, который умеет находить регионы с формулами и выдавать LaTeX-блоки ($$...$$) в markdown. marker это делает; Pandoc — нет. Для научных текстов это, пожалуй, главная причина смириться со скоростью ИИ-экстрактора.
Кодовые блоки и inline-код
Многие PDF рендерят код моноширинным шрифтом, но при экспорте теряют семантический тег «это код». ИИ-экстракторы заново определяют кодовые регионы по визуальному стилю — моноширинному шрифту и отступам — и оборачивают их в тройные обратные кавычки. Pandoc-пайплайны обычно «сплющивают» код обратно в обычные абзацы.
Сноски и цитаты
Научные статьи используют пронумерованные сноски с телом сноски в нижней части страницы. Путь через pdftotext теряет связь между маркером ссылки и телом сноски. Docling и marker сохраняют их в виде корректного markdown-синтаксиса сносок (ссылка [^1] + определение [^1]: тело).
Сканированные PDF (нужен OCR)
Сканированный PDF — это изображение страницы, а не текст. Извлекать нечего, пока вы не прогнали OCR.

Три надёжных пути:
-
ocrmypdf — добавляет в сканированный PDF невидимый OCR-слой текста, не меняя визуальный вид. После этого работает любой конвертер дальше по цепочке:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
ИИ-экстракторы с режимом OCR — marker и Docling умеют замечать, что у страницы нет текстового слоя, и запускают OCR автоматически. Вывод единый, так что на выходе сразу один markdown-файл, без промежуточного PDF.
-
Онлайн-конвертеры с автоматическим OCR — некоторые браузерные инструменты (включая наш — для PDF без текста) прогоняют OCR прозрачно. Удобно, но следите за поддерживаемыми языками, если документ не на английском.
Неочевидная ловушка: «born-digital» PDF (созданный из Word-документа, не сканированный) всё равно может остаться без текстового слоя, если его экспортировали как «сплющенные» изображения. Сначала проверяйте, можно ли выделить текст в PDF-просмотрщике. Если можно — OCR не нужен. Если нет — запускайте.
Подготовка Markdown к подаче в RAG / LLM
Если конечная точка — векторная база, несколько мелких решений в момент конвертации заметно поднимают качество retrieval дальше по пайплайну.
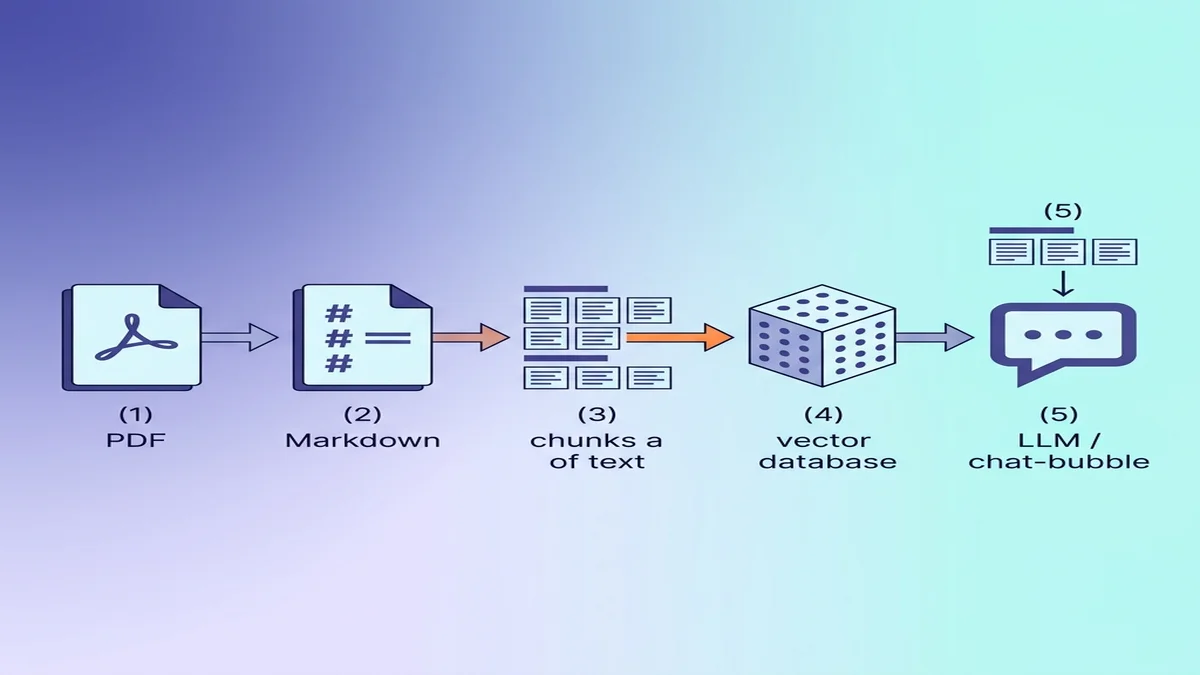
Почему Markdown лучше сырого текста для LLM
Markdown несёт структуру, которую обычный текст теряет. Модель, читающая ## Methods, понимает, что вошла в новый раздел; та же модель, читающая тот же текст без разметки, видит только абзацы одинакового веса. Если вы только знакомитесь с синтаксисом — наше базовое руководство по Markdown читается за 5 минут.
Чанкование по иерархии заголовков
Самая частая ошибка RAG — фиксированный размер чанка: документ режут на блоки по 500 токенов независимо от структуры. Markdown позволяет делить семантически — режьте по границам ## H2 и получите цельные секции вместо обрывков посреди абзаца.
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
Ещё лучше: пройтись по заголовкам как по дереву и прикрепить каждый H3 к родительскому H2 в метаданных чанка.
Сохранение метаданных во frontmatter
Добавьте YAML frontmatter в начало каждого конвертированного файла, чтобы вместе с чанком путешествовала информация об источнике:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
Когда LLM извлекает чанк, эти метаданные превращаются в подвал с цитированием. Это же — способ потом ответить на вопрос «откуда это утверждение?» без повторного retrieval. Если собираете такой пайплайн из экспортов чатов — та же идея применима к транскриптам ChatGPT/Claude.
Частые ловушки и как их избежать
Несколько вещей кусают тех, кто делает это в первый раз.
- Пропуск нормализации кодировки. PDF любит Unicode-фокусы: лигатуры (
fi,fl), типографские кавычки («vs"), длинные тире, похожие на дефисы. Прогоните вывод через нормализацию Unicode (NFKC в Python), прежде чем подавать дальше. - Оставленные колонтитулы. Подвал
Страница 4 из 12на каждой странице становится шумом в retrieval. Удаляйте повторяющиеся строки, появляющиеся с регулярным интервалом. - Доверие к первой таблице. Проверьте хотя бы первые две таблицы, прежде чем считать остальные нормальными.
- Допущение «born-digital значит есть текстовый слой». Некоторые PDF экспортируются как сплющенные изображения, даже если родились из Word-документа. Сначала пробуйте выделить текст.
- Излишнее чанкование маленьких документов. Для трёхстраничной служебки просто скормите весь markdown модели и пропустите RAG. Retrieval — избыточен, когда контекстное окно > документа.
FAQ
Какой бесплатный конвертер PDF в Markdown лучший?
Для большинства пользователей самый быстрый путь — онлайн-конвертер: перетащил, нажал, готово. Для пакетной или программной работы pymupdf4llm (Python) и Pandoc (CLI) покрывают простые случаи. Для научных статей с таблицами и формулами marker и Docling дают заметно более чистый вывод. «Лучший» выбор зависит от того, что вы оптимизируете: время на установку или точность результата.
Может ли ChatGPT или Claude конвертировать PDF в Markdown?
Могут, с оговорками. Оба умеют читать PDF напрямую и выдавать markdown, но на длинных документах вы упрётесь в лимит контекста, а точность по таблицам и формулам разнится от запроса к запросу. Для детерминированной пакетной конвертации специализированный конвертер надёжнее. См. экспорт ChatGPT в Word/PDF/HTML — там разобран связанный сценарий туда-обратно.
Как конвертировать сканированный PDF в Markdown?
Сначала запустите OCR. Самый чистый путь — ocrmypdf добавляет текстовый слой, и дальше работает любой конвертер. Альтернатива: у marker и Docling OCR встроен, и они выдают markdown сразу из PDF-картинок.
Конфиденциальна ли онлайн-конвертация PDF в Markdown?
В нашем конвертере файлы обрабатываются в памяти и удаляются сразу после конвертации — аккаунт не требуется, постоянного хранения нет. Другие сервисы различаются; проверяйте политику конфиденциальности любого инструмента, особенно для конфиденциальных документов.
Как сохранить таблицы при конвертации PDF в Markdown?
Пропустите связку pdftotext + Pandoc на PDF с большим количеством таблиц — она их почти всегда ломает. Используйте онлайн-конвертер, который выдаёт GFM-таблицы, или ИИ-экстрактор вроде marker или Docling. В любом случае проверяйте первые таблицы вручную.
Хранить ли оригинал PDF или только Markdown?
Храните оба. Markdown — для подачи, поиска и редактирования. PDF — источник истины для цитирования и аудита. Указывайте имя PDF-файла и диапазон страниц во frontmatter markdown, чтобы всегда можно было проследить утверждение до его источника.
Готовы конвертировать первый PDF?
Если нужен просто результат — наш бесплатный конвертер PDF в Markdown справляется с повседневными случаями без регистрации. Следующий шаг — превратить этот markdown в чистый Word или PDF под рассылку — описан в руководстве Markdown в Word.
References
- Pandoc User's Guide — канонический справочник по CLI-конвертации.
- GitHub Flavored Markdown Spec — диалект, на который ориентирован вывод этого руководства.
- Docling (IBM Research) — open-source layout-aware PDF-экстрактор.
- marker — open-source PDF-в-markdown с сильной обработкой научных статей.
- pymupdf4llm — лёгкая обёртка над PyMuPDF для извлечения markdown.
- OCRmyPDF — добавляет поисковый текстовый слой к сканированным PDF.