Word를 Markdown으로 변환하는 방법: 2026년 실전 이관 가이드
DOCX 파일을 Git 친화적인 Markdown으로 깔끔하게 변환하는 방법을 소개합니다. 표, 목록, 이미지 처리 팁과 실제 200개 문서 이관 경험까지 담았습니다.

"이 Word 문서들 전부 팀 위키로 옮겨 줄 수 있어요?" — 보통 이런 식으로 요청이 들어옵니다. 간단해 보이죠.
그런데 공유 드라이브를 열어 보면 상황이 달라집니다. .docx 파일 300 개, 10 년치 사내 문서, 정책과 런북, 회의록과 스펙이 일관성 없는 이름으로 폴더 곳곳에 흩어져 있습니다. diff 가 제대로 찍히지 않고, 검색도 원활하지 않으며, 어느새 누군가가 분기 내에 전부 Git 으로 관리되는 Markdown 으로 바꾸자고 결정을 내린 뒤입니다.
저는 이런 이관을 두 번 해봤습니다. 한 번은 컴플라이언스 아카이브 (약 200 개 파일), 또 한 번은 엔지니어링 지식 베이스 (약 500 개 파일) 였고, 두 번 모두 얻은 교훈은 같았습니다. Word 에서 Markdown 으로 변환하는 작업은 버튼 한 번으로 끝나는 일이 아니라는 것입니다. 변환, 검수, 정리로 이어지는 파이프라인이고, 실제 시간은 정리 단계에서 전부 빠져나갑니다.
이 글에서는 실전에서 검증된 내용만 정리했습니다. 알아 둘 만한 변환 방법 세 가지, Word 기능 중에서 살아남는 것과 조용히 사라지는 것, 그리고 수작업 수정을 몇 시간 아껴 주는 변환 후 체크리스트입니다.
왜 Word 문서를 굳이 Markdown으로 옮기는가
방법을 이야기하기 전에 이유를 짧게 짚고 가겠습니다. 팀 내부에서 "왜 옮기는가"에 대한 답이 정리되어 있지 않으면 이관은 오래가지 못합니다.
- Diff 가 가능한 변경 이력. Word 의
.docx는 XML 파일을 zip 으로 묶은 형식입니다. Git 입장에서는 두 버전이 서로 다른 바이너리 덩어리로만 보입니다. 반면 Markdown 은 평문이라 모든 변경이 사람이 읽을 수 있는 diff 로 남습니다. - 검색과 grep.
rg "incident response" docs/한 줄이면 수천 개 Markdown 파일을 밀리초 단위로 훑을 수 있습니다. Word 문서 전체를 검색하려면 별도 유료 도구가 필요합니다. - 자동화. Markdown 은 정적 사이트 생성기, 문서 도구 (Docusaurus, MkDocs, Nextra), LLM 인제스트 파이프라인, CI 시스템, 린터 등이 모두 직접 읽을 수 있습니다. Word 는 사실상 Word 에서만 제대로 읽힙니다.
- 장기 보존. 평문 파일은 특정 벤더의 수명을 넘어 살아남습니다. DOCX 는 지금은 안정적이지만 구형 바이너리 포맷인
.doc의 호환성 지평은 이미 흐릿해지고 있습니다.
위 이유 중 하나도 해당되지 않는다면 굳이 이관할 필요가 없을지도 모릅니다. 한 가지라도 공감된다면 이 글이 도움이 될 겁니다.
변환 후 살아남는 것과 사라지는 것
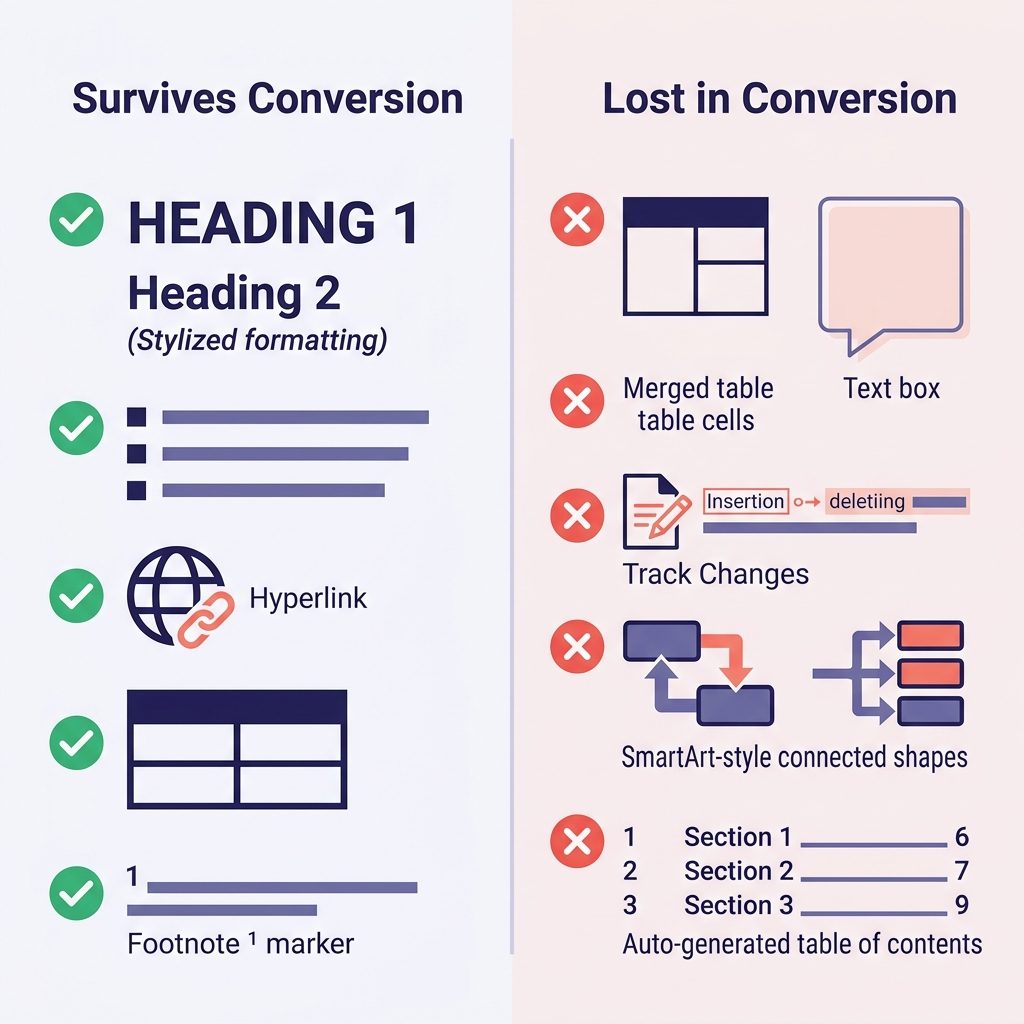
기대치를 미리 맞춰 두는 것이 가장 큰 시간 절약입니다. 수백 건의 변환을 겪으며 관찰한 내용을 정리하면 다음과 같습니다.
| Word 기능 | 보존 여부 | 참고 사항 |
|---|---|---|
| 제목 스타일 (Heading 1–6) | 예 | # 부터 ###### 까지 직접 매핑됨 |
| 굵게, 기울임, 밑줄 | 굵게/기울임은 예 | 밑줄은 Markdown 표준이 없음 (기울임이나 HTML <u> 로 대체) |
| 글머리 기호와 번호 매기기 목록 | 대부분 예 | 깊게 중첩된 목록은 평탄화되는 경우가 있음 |
| 하이퍼링크 | 예 | URL 과 링크 텍스트 모두 유지 |
| 표 (Table) | 단순 표는 예 | 병합 셀, 셀 색상, 테두리는 손실됨 |
| 인라인 이미지 | 예 | 폴더로 추출되며 링크가 자동으로 재작성됨 |
| 각주 (Footnote) | GFM 에서 예 | [^1] 구문으로 변환 |
코드 (Code 단락 스타일) | 상황에 따라 다름 | 펜스 없이 일반 텍스트로 평탄화되는 경우가 많음 |
| 수식 (Math) | 부분 보존 | LaTeX 로 변환되기도 하지만 평탄화되기도 함 |
| 변경 내용 추적 (Track Changes) | 아니오 | 변환 전에 모든 변경을 수락 또는 거부해야 함 |
| 메모 (Comments) | 아니오 | 변환 전에 해결하거나 별도 내보내기 필요 |
| 텍스트 상자, SmartArt, 도형 | 아니오 | 완전히 손실됨 — 이미지 또는 평문으로 먼저 치환 |
| 자동 생성된 목차 | 아니오 | 문서 도구에서 다시 생성해야 함 |
| Word 필드 (날짜, 상호 참조) | 아니오 | 내보내기 전에 평문으로 변환 |
이관에서 가장 당황스러운 순간은 대체로 두 가지에서 나옵니다. 첫째, 제목처럼 보이지만 사실은 굵은 글씨 + 큰 폰트로 수동 스타일링한 경우입니다. 이런 문단은 평범한 굵은 텍스트로 떨어져서 결과물에 구조가 남지 않습니다. 둘째, 병합 셀이 있는 표입니다. 보기 흉하게 무너지고 수작업으로 다시 만들어야 하는 경우가 많습니다.
일괄 변환을 시작하기 전에 원본 문서 10 개 정도를 무작위로 훑어 이 문제들을 플래그해 두세요. 30 분 투자로 여러 시간의 재작업을 막을 수 있습니다.
방법 1: 온라인 변환기
단일 파일 또는 50 개 미만의 소규모 배치라면 가장 먼저 권장하는 방법입니다. 설치 없이 .docx 에서 깨끗한 Markdown 까지 가장 빠르게 도달할 수 있습니다.
- Word to Markdown 변환기를 엽니다
.docx파일을 업로드 영역으로 드래그합니다- 변환된 Markdown 을 미리보기로 확인합니다
.md파일을 다운로드합니다 (이미지가 있으면 별도로 번들링됩니다)
출력은 GitHub Flavored Markdown (GFM) 을 사용하기 때문에 표, 작업 목록, 각주가 모두 보존됩니다. 제목은 # 레벨로, 목록은 계층이 그대로, 하이퍼링크는 앵커 텍스트까지 유지됩니다.
한 가지 덧붙이자면, 표준 문서는 브라우저 내에서 변환이 끝납니다. 대용량이거나 민감한 자료를 다룰 때 파일을 외부 서버로 올리지 않는다는 점은 단순한 마케팅 포인트가 아니라 실질적인 기능입니다.
다만 어떤 온라인 변환기든 (저희 것을 포함해서) 한계는 같습니다. 배치 처리가 이상적이지 않고, 파이프라인의 일부로 스크립트화하기 어렵습니다. 이런 경우라면 방법 2 로 넘어가세요.
방법 2: Pandoc (배치와 스크립트용)
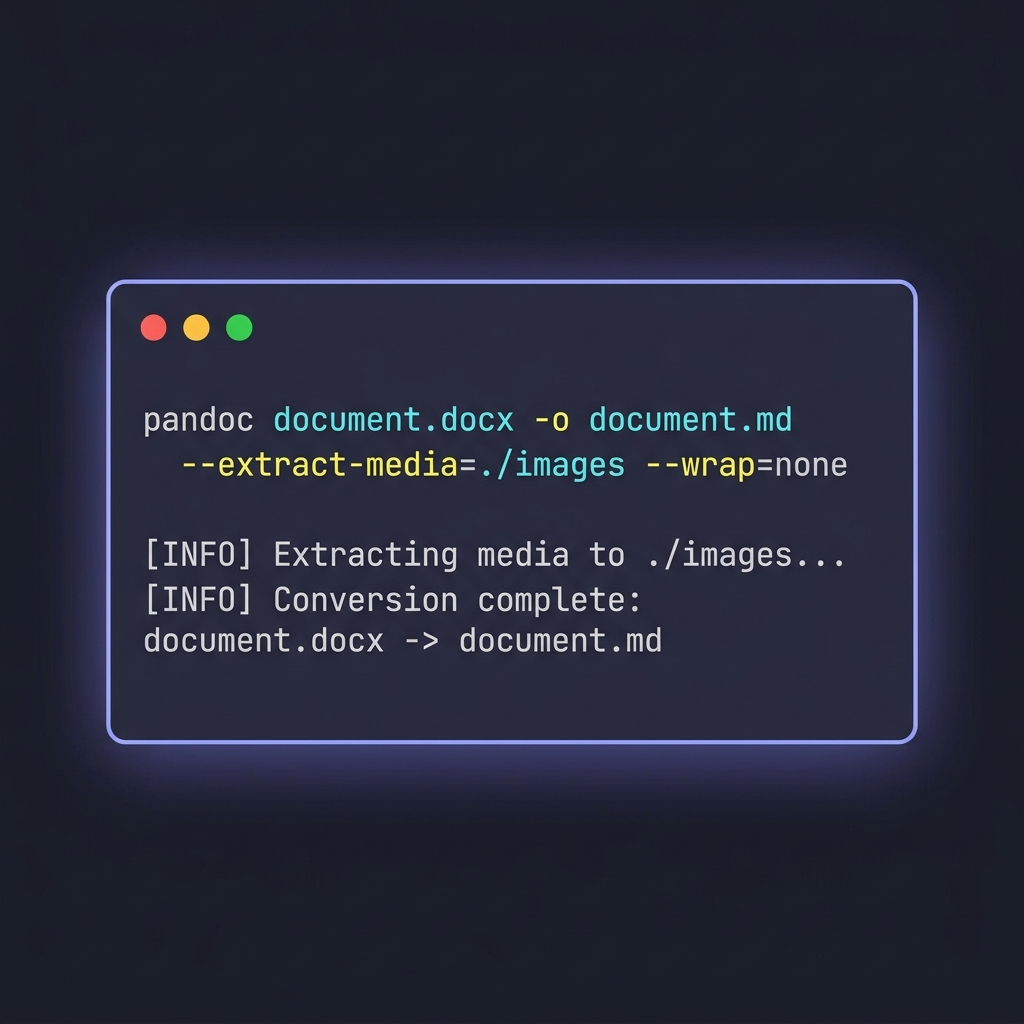
Pandoc 은 범용 문서 변환기입니다. 파일 수가 한 움큼을 넘어가거나 출력을 세밀하게 조정해야 할 때 저는 항상 이 도구를 꺼냅니다.
기본 명령어
pandoc document.docx -o document.md
단일 파일은 이 한 줄이면 끝납니다. 실행도 빠르고 결과도 읽기 좋으며 대부분의 Word 기능을 별도 설정 없이 처리해 줍니다. 다만 Pandoc 의 진가는 플래그를 함께 쓸 때 드러납니다.
알아 둘 만한 세 가지 플래그
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— DOCX 안에 들어 있는 이미지를 폴더로 추출하고 출력에서 이미지 링크를 자동으로 다시 써 줍니다. 이 플래그를 빼면 인라인 이미지가 조용히 사라집니다.--wrap=none— Pandoc 이 80 자 근처에서 줄바꿈을 강제로 넣지 않도록 합니다. 프로즈 중심 문서는 줄바꿈이 들어가면 Git diff 가독성이 크게 떨어지기 때문에 중요합니다.--markdown-headings=atx— 구형인 setext 스타일 (====로 밑줄) 대신 최신 규약인# 제목형식으로 강제합니다.
폴더 단위 일괄 변환
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
이 셸 스크립트 하나면 수백 개 파일을 몇 분 안에 처리할 수 있습니다. 아카이브 규모가 더 크다면 trap 과 로깅을 추가해서 중간에 실패해도 재개할 수 있게 해 두세요.
실전에서 마주치는 함정
- 글머리 마커가 일관적이지 않습니다. Pandoc 은 때로
-, 때로*을 씁니다. 일관성이 중요하다면 출력 전체에sed -i 's/^\* /- /g'를 돌리거나 에디터의 Markdown 포매터 설정을 맞춰 두세요. - 번호 매기기가 갑자기 리셋됩니다. Word 에는 Pandoc 이 해석하지 못하는 "번호 계속" 지시자가 있습니다. 원본에서는 연속처럼 보이던 목록이
1, 2, 1, 2, 3으로 카운트되는 경우가 있습니다. 빠른 리뷰로 수정 가능합니다. - 셀이 긴 표는 가독성이 무너집니다. Pandoc 이 최선을 다하지만 GFM 표는 Word 처럼 셀 내 줄바꿈을 지원하지 않습니다. 특히 복잡한 표는 HTML 블록으로 수동 변환하는 것도 고려하세요.
Pandoc 은 GUI 가 없습니다. 이는 단점이기도 하고 (비기술 팀원은 직접 돌릴 수 없음) 장점이기도 합니다 (어떤 CI/CD 파이프라인에도 쉽게 끼워 넣을 수 있음).
방법 3: Mammoth.js로 프로그래밍 방식 변환하기
SharePoint 에서 DOCX 파일을 가져와 변환하고 Git 에 커밋하는 식의 이관 스크립트를 짜야 한다면, 웹 UI 도 Pandoc 서브프로세스 호출도 스택에 맞지 않을 수 있습니다. Mammoth.js 는 Node.js 에서 DOCX 를 깔끔한 HTML 또는 Markdown 으로 직접 변환해 주는 JavaScript 라이브러리입니다.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // the Markdown output
console.log(result.messages); // warnings about unsupported features
});
Mammoth 가 유용한 이유는 그 철학에 있습니다. Word 의 시각적 스타일은 아예 무시하고 오직 의미 구조 (제목, 목록, 표) 에만 집중합니다. 기본 출력이 Pandoc 보다 깔끔한 대신 세밀한 제어는 덜합니다. 구조가 대체로 일관적인 레거시 아카이브를 옮길 때는 저는 Mammoth 를 먼저 선택합니다. 제각각인 서식이 잔뜩 들어간 문서라면 Pandoc 의 유연성이 이깁니다.
Python 사용자라면 python-docx 에 Markdown writer 를 결합하는 선택지가 있지만, 이건 기성 도구라기보다는 직접 만드는 접근에 가깝습니다.
아무도 알려주지 않는 정리 단계

변환만 하면 .md 파일이 만들어지긴 합니다. 하지만 그 파일이 곧바로 커밋할 수 있는 .md 파일이 되는 건 아닙니다.
제가 쓰는 표준 변환 후 체크리스트입니다. 손에 익으면 문서당 5 분 내외로 끝낼 수 있습니다.
- 누락된 구조적 제목을 찾으세요. 출력에서 한 줄짜리
**Bold Text**로 된 부분을 검색합니다. 누군가 Heading 스타일 대신 손으로 굵게 처리한 경우입니다. 이런 줄은 실제##제목으로 승격시키세요. - 첫 번째 표를 확인하세요. 여기에서 표가 제대로 보이면 나머지도 대부분 멀쩡합니다. 반대로 첫 번째가 깨져 있다면 전체가 깨져 있을 가능성이 높습니다.
- 목록 항목 내부의 빈 줄을 제거하세요. Pandoc 이 목록 연속성을 끊는 빈 줄을 종종 끼워 넣습니다.
- 이미지 링크를 점검하세요. VS Code 의 기본 Markdown 미리보기 같은 도구로 열어 이미지가 실제로 뜨는지 확인합니다.
- 잔여 아티팩트를 검색하세요. 자주 남는 것들: 줄 끝의
\(Word 에서는 숨겨지지만 Markdown 에서는 보이는 강제 줄바꿈),{.underline}스타일 속성, 빠져나온<span>태그. - 처음과 마지막 10 줄을 확인하세요. Word 의 머리글, 바닥글, 페이지 번호가 빈 내용이나 이상한 아티팩트 형태로 새어 나오는 경우가 많습니다.
대규모 이관에서는 5 번과 6 번을 클린업 스크립트로 자동화하세요. 나머지는 사람 눈이 필요합니다 — 적어도 특정 문서군의 출력을 믿을 수 있을 만큼 패턴이 쌓이기 전까지는요.
실제 사례: 200개 파일 규모의 컴플라이언스 아카이브
제가 컴플라이언스 아카이브를 옮길 때 쓴 워크플로우입니다. 200 개 아카이브를 처음부터 끝까지 이틀 만에 마쳤습니다.
1 일차 오전: 원본 분류
각 DOCX 를 열어 제목, 이미지, 표의 개수를 세고 변경 내용 추적이나 메모가 남아 있으면 플래그하는 Python 스크립트를 작성했습니다. 결과물은 복잡도 순으로 정렬된 CSV 였습니다. 이 시점의 목표는 아직 아무것도 고치지 않고 — 내가 어떤 지형으로 들어가고 있는지만 파악하는 것이었습니다.
1 일차 오후: 단순한 파일 일괄 변환
200 개 중 약 140 개는 단순했습니다. 이미지 없음, 단순한 표, 깔끔한 제목 구조. --extract-media 와 --wrap=none 을 건 Pandoc 루프로 돌렸습니다. 무작위로 20 개 샘플을 점검했고 모두 양호했습니다.
2 일차 오전: 복잡한 파일 개별 처리
남은 60 개는 병합 셀, 임베드된 스프레드시트 객체, 먼저 누군가가 검토해야 할 상당량의 변경 이력 같은 문제가 있었습니다. 이 파일들은 온라인 변환기를 케이스별로 활용했고, 때로는 Pandoc 플래그를 다르게 줬으며, 때로는 원본 DOCX 를 먼저 정리하고 변환했습니다.
2 일차 오후: 정리와 커밋
변환된 200 개 파일 전체에 클린업 스크립트를 돌렸습니다 ({.underline} 아티팩트 제거, 글머리 마커 통일, Pandoc 의 줄바꿈 출력 정리). diff 를 검토하고 50 개 단위로 커밋한 뒤 이관 브랜치에 푸시했습니다.
이걸 전부 수작업으로 했다면 — Word 문서를 하나씩 열어 Markdown 에디터에 붙여 넣었다면 — 최소 2 주는 걸렸을 겁니다. 변환 도구는 선택이 아니라 이 프로젝트를 다루기 가능한 규모로 만들어 주는 핵심입니다.
자주 발생하는 문제와 해결법
Markdown 미리보기에서 표가 이상해 보일 때
90% 는 원본에 병합 셀이 있거나 셀 내용이 매우 긴 경우입니다. GFM 표는 이 두 가지를 매끄럽게 지원하지 않습니다. 선택지는 셋입니다. GFM 으로 표를 수동 재구성하기, Markdown 안에 HTML <table> 블록 사용하기 (대부분의 렌더러가 지원), 또는 표를 여러 개의 단순한 표로 쪼개기.
이미지가 보이지 않을 때
변환기가 이미지를 실제로 추출했는지부터 확인하세요. Pandoc 은 --extract-media 를 주지 않으면 추출하지 않습니다. 온라인 변환기는 보통 Markdown 파일과 images/ 폴더를 zip 으로 함께 다운로드해 줍니다. 둘 다 제자리에 있는지, Markdown 안의 이미지 경로와 실제 파일 경로가 맞는지 확인하세요.
줄 끝에 이상한 백슬래시가 남을 때
Word 의 강제 줄바꿈이 Markdown 의 줄바꿈으로 변환된 것입니다. 원본 Word 문서가 문단 구분 대신 줄바꿈으로 촘촘하게 간격을 준 경우, Pandoc 이 그걸 그대로 보존합니다. 줄 끝의 \\$ 를 찾아 바꾸기 (regex 검색) 로 일괄 정리할 수 있습니다.
변환 후 제목 레벨이 어긋날 때
Word 문서는 Heading 2 나 Heading 3 에서 시작하는 경우가 많습니다 (Heading 1 은 표지용으로 예약되어 있기 때문). Markdown 에서는 # (H1) 부터 시작하는 것이 관례입니다. 문서 시스템이 제목을 표시하는 방식에 따라 모든 레벨을 한 단계씩 올려야 할 수 있습니다. sed 로 간단히 처리할 수 있습니다: sed -i 's/^## /# /; s/^### /## /; ...' file.md.
변환된 Markdown이 원본 Word 문서와 전혀 달라 보일 때
정상입니다. Markdown 은 외형 이 아니라 구조 를 기술합니다. 스타일은 Markdown 을 렌더링하는 시스템 (GitHub, 문서 사이트, MkDocs 테마 등) 이 결정합니다. 시각적 충실도가 핵심이라면 PDF 가 더 적합한 타깃입니다 — 시각 디자인이 보존되는 워크플로우는 Markdown to PDF 가이드에서 다룹니다.
라운드 트립: Markdown을 다시 Word로
이관 후에 자연스럽게 생기는 질문이 있습니다. "Markdown 문서를 Word 만 열 수 있는 담당자에게 보내야 할 때는 어쩌나요?" 그때는 반대 방향 변환입니다 — 그리고 이쪽이 훨씬 깔끔한 작업입니다. Markdown 에는 원래 표현할 수 있는 요소가 적기 때문에 번역할 거리도 적거든요. 자세한 흐름은 Markdown to Word 가이드에서 다룹니다.
두 포맷을 자주 오가는 팀이라면 이런 워크플로우가 제일 잘 굴러갑니다: Git 에 있는 Markdown 을 단일 진실 원천으로 두고, 리뷰나 주석이 필요할 때만 온디맨드로 Word 로 내보냅니다. Word 에서 편집해서 다시 머지하는 일은 없어야 합니다 — 그래야 이관이 조금씩 무너지지 않습니다.
마치며
Word 를 Markdown 으로 바꾸는 건 버튼 한 번이 아니라 이관 프로젝트입니다. 도구들이 무거운 작업을 대신해 주지만 — 단발성 파일에는 온라인 변환기, 배치에는 Pandoc, 파이프라인에는 Mammoth.js — 진짜 일은 변환 전 조사와 변환 후 정리입니다.
가장 큰 시간을 아껴 주는 두 가지 패턴은 다음과 같습니다.
- 먼저 분류하세요. 변환을 시작하기 전에 원본 아카이브에 뭐가 들어 있는지 파악하세요. 15 분짜리 샘플링이 여러 시간의 사후 대응을 막아 줍니다.
- 정리 시간을 예산에 넣으세요. 문서당 5 분을 리뷰와 다듬기에 할당하세요. 이걸 피할 수 없는 단계로 받아들일 때 이관 일정이 솔직해집니다.
Markdown 을 이제 막 접하는 분이라면 결과물이 어떻게 보일지 감을 잡기 위해 Markdown이란 무엇인가와 기본 구문 가이드부터 시작하세요. 표, 각주, 작업 목록 같은 고급 기능은 GFM 기준으로 확장 구문 레퍼런스에서 확인할 수 있습니다.
이관의 출발점이 Word 가 아니라 Obsidian 이라면 Obsidian 내보내기 가이드가 그 흐름을 처음부터 끝까지 다룹니다.