PDF를 Markdown으로 변환하는 법 2026 (무료 + RAG 대응)
2026년 기준으로 PDF를 Markdown으로 제대로 변환하는 법. 무료 온라인 도구, Pandoc, AI 기반 추출기를 비교하고 RAG 워크플로우와 OCR 처리법까지 정리합니다.

PDF에서 문단을 복사해 붙여 넣었더니 줄바꿈이 어지럽게 흩어지고 하이픈은 끊어지며 서식이 통째로 사라지는 광경을 한 번이라도 본 적이 있다면, 2026년에 PDF를 Markdown으로 변환하는 일이 왜 본격적인 워크플로우 문제로 떠올랐는지 이미 체감하셨을 것입니다.
PDF는 문서를 공유하는 만국 공통의 화폐입니다. 동시에 소스 포맷으로는 형편없는 형식이기도 합니다. 그 안의 내용을 RAG 파이프라인에 흘려보내거나, 문서 사이트에 얹거나, 그저 노트 앱에 보관하려는 순간부터 구조화된 텍스트가 필요해집니다 —— 제목은 제목으로, 표는 표로, 코드는 코드로 살아 있어야 합니다.
이 가이드에서는 PDF를 Markdown으로 변환하는 세 가지 정직한 길을 소개합니다: 설치가 필요 없는 온라인 변환기, 커맨드라인의 Pandoc, 그리고 marker와 Docling으로 대표되는 새로운 AI 기반 추출기입니다. 어떤 상황에 어떤 도구를 골라야 하는지, 깨지는 부분(표, 수식, 스캔 페이지)을 어떻게 고치는지, 그리고 결과물을 두 번 다듬지 않고 바로 LLM 파이프라인에 태우는 방법까지 짚어 드립니다.
왜 PDF를 Markdown으로 변환할까
같은 변환 문제가 세 갈래 커뮤니티에서 반복해서 등장합니다. 각자 그 문제에 신경 쓰는 이유는 조금씩 다르지만, 도착해야 하는 형식은 동일합니다.
RAG와 LLM 파이프라인에 깨끗한 텍스트 공급
검색 증강 생성(RAG) 파이프라인은 PDF의 날것 텍스트를 좋아하지 않습니다. 페이지 경계의 잔해, 두 단 레이아웃이 한 단으로 무너지면서 뒤섞인 본문, 모든 페이지마다 반복되는 머리말과 꼬리말 —— 이 모든 것이 벡터 데이터베이스에서는 노이즈가 되고 검색 품질을 떨어뜨립니다.
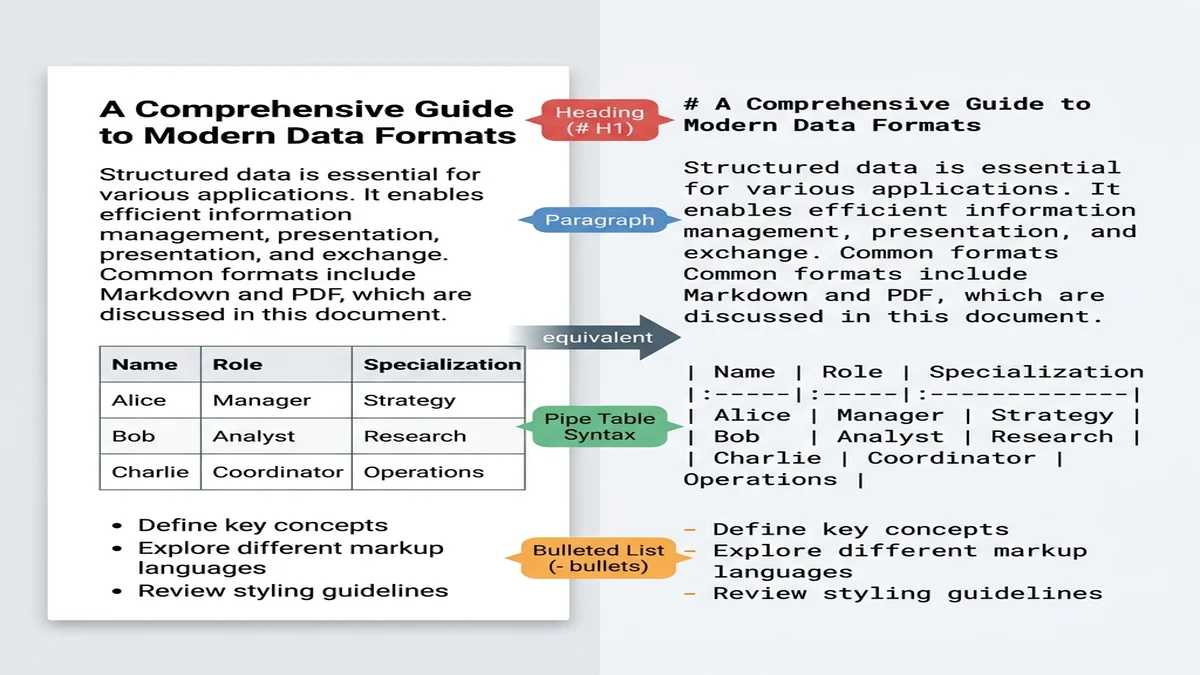
Markdown은 다른 어떤 실용 포맷보다 "구조화된 평문"에 가깝습니다. 웹 데이터로 학습한 대형 모델은 수십억 개의 markdown 문서(README 파일, Stack Overflow 답변, 블로그 글)를 이미 봐 왔기 때문에, 별다른 안내 없이도 # 제목을 섹션 경계로, | 파이프를 표 구분자로 인식합니다.
레거시 PDF를 현대적 문서 시스템으로 이관
Docusaurus, MkDocs, Astro Starlight, Hugo 모두 markdown을 원합니다. 팀에 레거시 사내 문서 PDF가 200개 쌓여 있다면 복사·붙여넣기 부대를 동원하고 싶진 않으실 테고, 제목 계층을 그대로 보존해 내비게이션이 스스로 만들어지는 변환기를 원하실 것입니다.
검색 가능한 제2의 두뇌 만들기
Obsidian, Logseq, Foam, Roam —— 현대적인 노트 앱은 모두 markdown을 모국어로 씁니다. 종이 자료를 디지털화하는 학자, 회의록을 보관하는 지식 노동자, 문헌 라이브러리를 구축하는 연구자 모두 같은 것을 원합니다: 제목이 살아 있는 깔끔한 markdown 파일 한 묶음. 그래야 나중에 수백 개 문서를 가로질러 grep을 돌릴 수 있습니다.
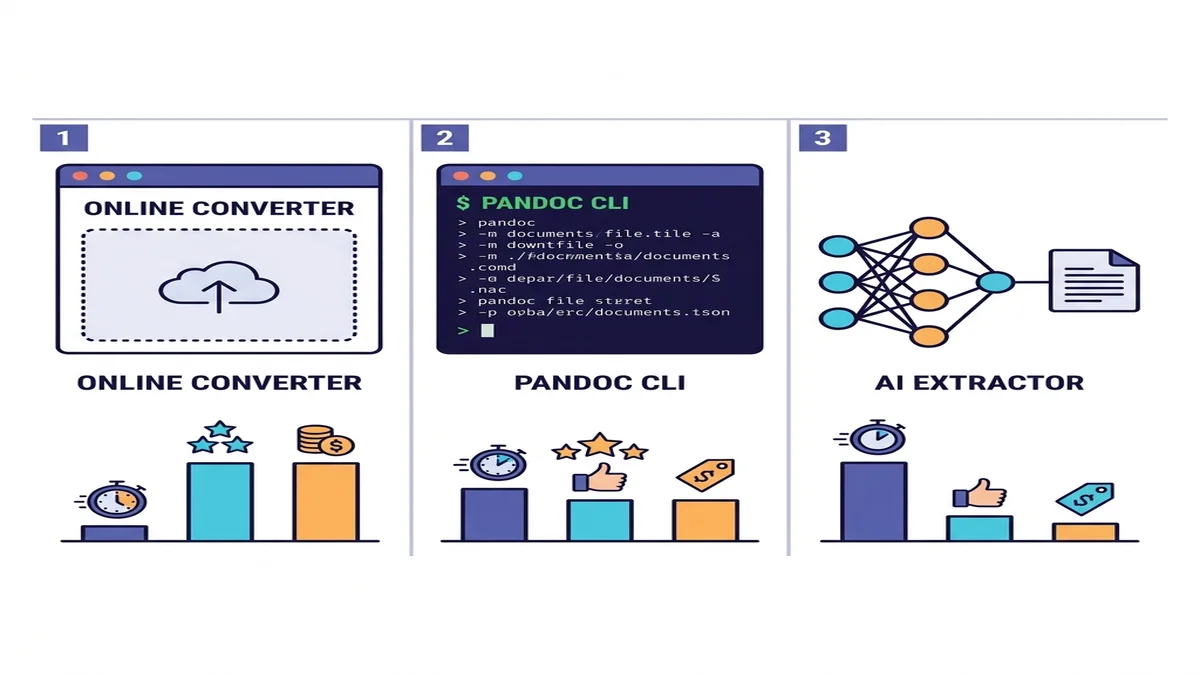
세 가지 접근법 (언제 무엇을 쓸까)
도구는 수십 개지만 실질적으로는 세 범주뿐입니다. 본인의 상황에 맞는 행을 고르시면 됩니다.
| 방법 | 속도 | 단순 PDF | 복잡한 PDF | 스캔본 OCR | 설치 |
|---|---|---|---|---|---|
| 온라인 변환기 | 빠름 | 우수 | 양호 | 내장 또는 자동 | 불필요 |
| Pandoc + pdftotext | 빠름 | 양호 | 표 처리 평범 | 없음 | CLI 설치 |
| AI 추출기 (marker / Docling) | 느림 | 우수 | 우수 | 지원 | Python + ML 의존성 |
어느 쪽을 골라야 할지 모르겠다면 온라인 변환기로 시작하세요. 시험 삼아 1분이면 끝나고, 대부분의 일회성 또는 소량 작업은 거기서 이야기가 끝납니다. 프로그램화된 파이프라인이나 밀도 높은 학술 콘텐츠라면 한 줄 아래로 내려가시면 됩니다. 더 넓은 도구 풍경은 무료 Markdown 변환기 모음 글에서 비교해 두었습니다.
방법 1: 온라인에서 PDF를 Markdown으로 변환 (무료, 설치 불필요)
가장 빠른 길은 사람들이 너무 단순해 보인다는 이유로 자주 건너뛰는 길이기도 합니다. 일상 업무의 압도적 다수 —— 회의록, 기사, 한 장짜리 보고서 —— 에서는 브라우저 기반 변환기 하나로 충분하고도 남습니다.
파일을 곧장 무료 PDF to Markdown 변환기에 떨궈 두시면 이 섹션의 나머지는 건너뛰셔도 됩니다.
단계별 진행
- PDF를 업로드 영역에 끌어다 놓거나, 클릭해서 파일을 고릅니다.
- 파서가 작업을 마칠 때까지 몇 초 기다립니다. 20페이지 이하 문서는 보통 이 문장을 두 번 읽기 전에 변환이 끝납니다.
- 오른쪽에서 렌더링된 markdown을 원본과 나란히 미리 봅니다.
- 소스를 복사하거나
.md파일로 다운로드합니다.
이게 전부입니다. 계정도, 이메일 입력 강요도, 워터마크도 없습니다.
이런 상황에 가장 잘 맞습니다
- 아무것도 설치하지 않고 한 번에 끝내고 싶은 일회성 변환.
- 프로그램화된 파이프라인에 본격적으로 투자하기 전, 결과를 빠르게 점검하고 싶을 때.
- 문서를 제3자 API로 올리고 싶지 않은 민감한 파일. 저희 변환기는 메모리에서 처리하고 즉시 파기합니다 —— 영구 저장은 없습니다.
한계
일반적으로 온라인 변환기(저희 것에 국한되지 않습니다)에는 알아 두면 좋은 두 가지 실패 모드가 있습니다.
첫째는 매우 크거나 특이한 PDF입니다. 임베디드 글꼴과 동적 폼 필드가 들어 있는 600페이지짜리 스캔 법률 자료는 어떤 도구로도 "끌어다 놓고 다운로드"로 끝나는 시나리오가 아닙니다. 그런 문서를 갖고 계신다면 AI 추출기 섹션으로 바로 건너뛰세요.
둘째는 텍스트 레이어가 없는 스캔본 PDF입니다. 추출할 텍스트 자체가 없고, 페이지가 그저 이미지인 경우입니다. 먼저 OCR이 필요하며, 아래의 까다로운 콘텐츠 다루기를 참고하시면 됩니다.
방법 2: 커맨드라인의 Pandoc
Pandoc은 문서 변환계의 만능 칼입니다. 재현 가능하고 스크립트로 엮을 수 있는 파이프라인이 필요하고, 웹 서비스에 의존하고 싶지 않을 때 적합한 도구입니다.
솔직히 말하면 함정이 하나 있습니다: Pandoc 자체에는 강력한 PDF 리더가 없습니다. 커뮤니티에서 쓰는 워크플로우는 (Poppler 유틸리티에 포함된) pdftotext를 거친 결과를 Pandoc으로 파이프하는 방식입니다.
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
본문 위주의 단순한 PDF —— 메모, 단일 단 기사 —— 에서는 이 조합이 잘 동작하고 밀리초 단위로 끝납니다.
충실도가 중요한 경우
PDF가 대체로 산문이라면 이 파이프라인은 문단 구조가 살아 있는 깔끔한 markdown 파일을 만들어 줍니다. 하드 랩핑된 줄을 싫어하는 다운스트림 도구가 있다면 -V와 --wrap=none 플래그로 출력을 조정해 보세요.
Pandoc이 힘겨워하는 영역
- 다단 레이아웃(학술 논문, 잡지):
pdftotext가 단을 교차로 섞어 버려 읽을 수 없는 출력이 나옵니다. - 표: 가장 단순한 2열 격자를 넘어서면 markdown 파이프가 아니라 공백으로 정렬된 열로 떨어집니다.
- 수식과 코드 블록: 의미가 보존되지 않습니다. LaTeX 수식은 텍스트로, 코드의 고정폭 표현은 일반 문단으로 평탄해집니다.
- 스캔본 PDF: 지원 자체가 없습니다 —— Pandoc/pdftotext는 이미지에서 텍스트를 뽑아낼 수 없습니다.
특히 표에 대해서는 확장 Markdown 문법 가이드에서 출력이 따라야 할 GFM 표 형식을 다루고 있습니다.
방법 3: AI 기반 추출 (marker, Docling, pymupdf4llm)
2024-2025년 사이 등장한 레이아웃 인식 추출기 흐름이 가능한 것의 범위를 바꿨습니다. 이 도구들은 시각적 레이아웃 감지에 OCR과 구조화된 출력 생성을 결합해, 이 영역은 표이고 저 영역은 두 단으로 구성된 본문이다라는 식의 이해를 가집니다. 복잡한 PDF에서 출력이 극적으로 깔끔해집니다.
알아 둘 만한 세 가지 프로젝트가 있습니다.
- marker —— 레이아웃 모델인 surya에 휴리스틱을 결합합니다. 학술 논문, 수식, 코드 블록 처리에 강합니다. 라이선스는 Apache 2.0.
- Docling —— IBM Research에서 만든 프로젝트입니다. 표 재구성 품질이 뛰어나며 LlamaIndex와 LangChain에 네이티브로 연결됩니다. 라이선스는 MIT.
- pymupdf4llm —— PyMuPDF 위에 얹은 가벼운 래퍼입니다. 앞 두 도구보다 빠르고 ML 의존성이 적으며, 특히 LLM 입력용으로 설계되었습니다.
최소한의 Python 예시
가장 작은 단위의 쓸 만한 Docling 파이프라인입니다:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
또는 더 가벼운 경로로 pymupdf4llm을 쓰는 경우:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
트레이드오프
이 도구들은 Pandoc 파이프라인보다 느립니다. 일반적인 CPU 노트북에서 30페이지 논문이라면 밀리초가 아니라 수십 초가 걸린다고 보시면 됩니다. GPU가 있다면 marker 기준 몇 초 수준으로 떨어집니다. pymupdf4llm은 무거운 비전 모델을 거치지 않기 때문에 셋 중 가장 빠릅니다.
다른 트레이드오프는 의존성 무게입니다. pip install marker-pdf 하나로 PyTorch와 수백 메가바이트의 모델 가중치가 함께 따라옵니다. 컨테이너에 담아 배포한다면 그 부피를 미리 계산해 두시는 편이 좋습니다.
까다로운 콘텐츠 다루기
각 방법 사이의 차이는 깔끔한 2페이지 메모로 시험하기를 멈추고, 진짜 현실의 PDF를 흘려 넣기 시작할 때 비로소 분명해집니다.
살아남지 못하는 표
표는 대부분의 변환기가 무너지는 지점입니다. pdftotext + Pandoc 경로는 거의 언제나 markdown 렌더러가 제대로 파싱하지 못하는 공백 정렬 열 죽처럼 나옵니다. 온라인 변환기와 AI 추출기는 표 영역을 먼저 감지한 뒤 셀을 재구성하기 때문에 이 부분에서 훨씬 잘합니다.
요령 하나: 나머지를 신뢰하기 전에 첫 번째 표 결과를 점검하세요. 첫 표가 망가져 있다면 나머지 50개도 똑같이 망가져 있습니다.
수식과 LaTeX 블록
PDF에 수식이 있다면, 수식 영역을 감지해 markdown 안에 LaTeX($$...$$) 블록으로 내보내는 도구가 필요합니다. marker는 이를 처리하지만 Pandoc은 처리하지 못합니다. 과학 글쓰기에서는 이 한 가지만으로도 AI 추출기의 속도 비용을 감수할 가장 큰 이유가 됩니다.
코드 블록과 인라인 코드
많은 PDF가 코드를 고정폭 글꼴로 렌더링하지만, 내보내기 단계에서 "이 부분은 코드"라는 의미적 태그를 잃어버립니다. AI 추출기는 시각적 단서 —— 고정폭 글꼴과 들여쓰기 —— 를 보고 코드 영역을 다시 감지해 트리플 백틱 펜스로 다시 감쌉니다. Pandoc 기반 파이프라인은 보통 코드를 일반 문단으로 평탄하게 펴 버립니다.
각주와 인용
학술 논문은 번호 매겨진 각주를 쓰고, 그 본문은 페이지 하단에 둡니다. pdftotext 경로는 참조 마커와 각주 본문 사이의 연결을 잃어버립니다. Docling과 marker는 이를 제대로 된 markdown 각주 문법([^1] 참조 + [^1]: 본문 정의)으로 보존합니다.
스캔본 PDF (OCR 필요)
스캔본 PDF는 페이지의 이미지일 뿐 텍스트가 아닙니다. 먼저 OCR을 돌리지 않는 한 추출할 것이 없습니다.

믿을 만한 경로 세 가지가 있습니다.
-
ocrmypdf —— 시각적 외형을 바꾸지 않으면서 스캔본 PDF에 보이지 않는 OCR 텍스트 레이어를 덧붙입니다. 한 번 레이어가 깔리면 이후의 어떤 변환기든 동작합니다:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
OCR 모드가 있는 AI 추출기 —— marker와 Docling은 페이지에 텍스트 레이어가 없음을 감지하면 자동으로 OCR을 돌립니다. 출력이 통합되어 있어, 중간 PDF를 거치지 않고 markdown 파일 하나가 나옵니다.
-
자동 OCR이 붙은 온라인 변환기 —— 일부 브라우저 도구(이미지 전용 PDF에 한해 저희 것을 포함)는 OCR을 투명하게 실행합니다. 편하지만 문서가 영어가 아니라면 언어 지원 범위를 확인하셔야 합니다.
미묘한 함정 하나: "디지털 네이티브" PDF(스캔이 아니라 Word 문서에서 만들어진 PDF)도 평탄화된 이미지로 내보내져 있다면 텍스트 레이어가 없을 수 있습니다. PDF 뷰어 안에서 텍스트를 선택할 수 있는지 항상 먼저 확인하세요. 선택할 수 있다면 OCR을 건너뛰셔도 되고, 선택할 수 없다면 돌리시면 됩니다.
RAG / LLM 입력용으로 Markdown 준비하기
목적지가 벡터 데이터베이스라면, 변환 과정에서의 자잘한 선택 몇 가지가 다운스트림의 검색 품질을 눈에 띄게 끌어올립니다.
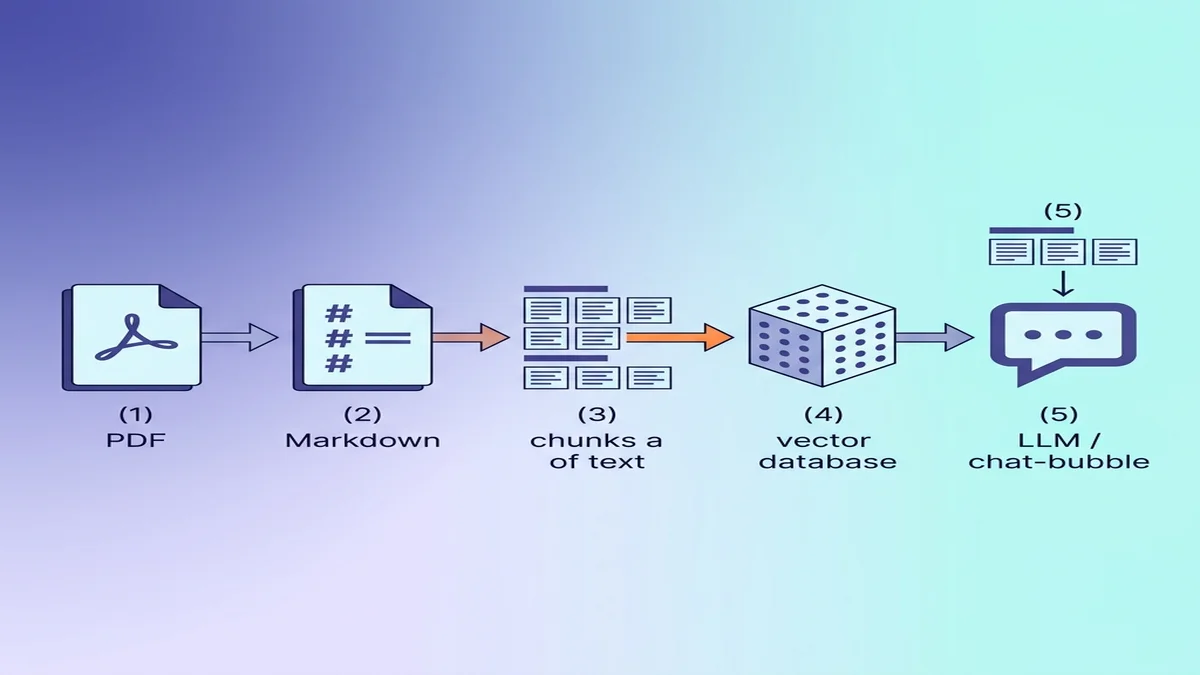
LLM에게 Markdown이 평문보다 유리한 이유
Markdown은 평문이 잃어버리는 구조를 함께 운반합니다. ## Methods를 읽는 모델은 새로운 섹션에 들어왔다는 사실을 압니다. 같은 텍스트에서 서식을 모두 벗겨낸 모습을 본 모델에게는 모두 같은 비중의 문단으로만 보입니다. 문법이 처음이시라면 기본 Markdown 가이드를 5분만 훑어보시면 됩니다.
제목 계층 기준 청크 분할
가장 흔한 RAG 실수는 고정 크기 청크 분할입니다 —— 구조와 무관하게 500토큰 단위로 잘라 넣는 방식입니다. Markdown은 의미 단위로 자를 수 있게 해 줍니다 —— ## H2 경계를 기준으로 자르면 문단 한가운데서 끊긴 조각이 아니라 일관된 섹션이 나옵니다.
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
더 나은 방법: 제목을 트리로 순회하면서 각 H3을 부모 H2와 함께 청크 메타데이터에 묶어 두는 것입니다.
frontmatter에 메타데이터 보존
변환한 파일마다 상단에 YAML frontmatter를 붙여, 청크와 함께 출처 정보가 따라가도록 만드세요:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
LLM이 청크를 검색해 올 때, 이 메타데이터가 인용 푸터가 됩니다. 또한 나중에 "이 주장은 어디서 왔는가?"라는 질문에 검색을 다시 돌리지 않고도 답할 수 있게 해 줍니다. 채팅 내보내기로 이런 파이프라인을 만들고 계시다면, 같은 아이디어가 ChatGPT/Claude 트랜스크립트에도 그대로 적용됩니다.
흔한 함정과 회피법
처음 이 작업을 해 보는 분들이 자주 발을 헛디디는 지점이 몇 가지 있습니다.
- 인코딩 정규화 건너뛰기. PDF는 Unicode 트릭을 사랑합니다: 합자(
fi,fl), 스마트 따옴표("대"), 하이픈처럼 보이는 em 대시. 어디로든 흘려 보내기 전에 Unicode 정규화(Python의 NFKC)를 한 번 거치게 하세요. - 페이지 머리말·꼬리말을 그대로 두기. 페이지마다 등장하는
Page 4 of 12꼬리말은 검색에서 노이즈가 됩니다. 일정한 간격으로 반복 등장하는 줄은 잘라 내세요. - 눈에 보이는 첫 표만 믿기. 적어도 첫 두 개의 표는 점검하고 나서야 나머지가 괜찮다고 가정하시면 됩니다.
- "디지털 네이티브"가 곧 "텍스트 레이어 있음"이라고 가정. 어떤 PDF는 Word 문서에서 출발했더라도 평탄화된 이미지로 내보내져 있습니다. 항상 텍스트 선택부터 시도해 보세요.
- 작은 문서를 과하게 청크로 자르기. 3페이지 메모라면 markdown 전체를 그대로 모델에 넣고 RAG 단계는 건너뛰는 편이 낫습니다. 컨텍스트 윈도우가 문서보다 크다면 검색은 과잉 설계입니다.
자주 묻는 질문
가장 좋은 무료 PDF to Markdown 변환기는 무엇인가요?
대부분의 사용자에게는 온라인 변환기가 가장 빠른 길입니다 —— 끌어다 놓고, 끝. 일괄 또는 프로그램화된 작업이라면 pymupdf4llm(Python)과 Pandoc(CLI)이 단순한 경우를 잘 다룹니다. 표와 수식이 들어간 학술 논문이라면 marker와 Docling이 눈에 띄게 좋은 결과를 내놓습니다. "가장 좋다"의 기준은 셋업 시간을 줄일지, 출력 충실도를 높일지에 따라 달라집니다.
ChatGPT나 Claude로 PDF를 Markdown으로 변환할 수 있나요?
가능하지만 단서가 붙습니다. 둘 다 PDF를 직접 읽고 markdown을 출력할 수 있지만, 긴 문서에서는 컨텍스트 한도에 부딪힐 수 있고 표와 수식 정확도가 실행마다 흔들립니다. 결정적인(deterministic) 일괄 변환에는 전용 변환기가 더 안정적입니다. 관련된 양방향 워크플로우는 ChatGPT를 Word/PDF/HTML로 내보내기를 참고하세요.
스캔본 PDF는 어떻게 Markdown으로 변환하나요?
먼저 OCR을 돌리세요. 가장 깔끔한 경로는 ocrmypdf로 텍스트 레이어를 덧붙인 다음, 그 OCR된 PDF에 아무 변환기나 적용하는 것입니다. 대안으로, marker와 Docling은 OCR이 내장되어 있어 이미지 전용 PDF에서도 곧장 markdown을 만들어 냅니다.
온라인 PDF-Markdown 변환은 안전한가요?
저희 변환기에서는 파일을 메모리에서 처리한 뒤 변환이 끝나면 곧바로 파기합니다 —— 계정도 필요 없고 영구 저장도 없습니다. 다른 서비스는 정책이 제각각이니, 특히 기밀 문서라면 사용하시려는 도구의 개인정보 처리방침을 확인해 보세요.
PDF를 Markdown으로 변환할 때 표를 온전히 유지하려면 어떻게 하나요?
표가 많은 PDF에는 pdftotext + Pandoc 파이프라인을 피하세요 —— 거의 언제나 표를 망가뜨립니다. GFM 표를 내보내는 온라인 변환기를 쓰시거나, marker, Docling 같은 AI 추출기를 사용하세요. 어느 쪽이든 처음 몇 개의 표는 직접 점검하시면 됩니다.
원본 PDF를 그대로 둘까요, Markdown만 남길까요?
둘 다 보관하세요. markdown은 입력, 검색, 편집용입니다. PDF는 인용과 감사(audit)를 위한 원본 진실입니다. markdown frontmatter에 PDF 파일명과 페이지 범위를 적어 두면, 어떤 주장이든 언제든 출처로 거슬러 갈 수 있습니다.
첫 PDF를 변환할 준비가 되셨나요?
결과만 빠르게 보고 싶으시다면 무료 PDF to Markdown 변환기가 가입 없이 일상적인 경우를 처리해 드립니다. 다음 단계 —— 그 markdown을 다듬어진 Word 문서나 공유 가능한 PDF로 만드는 일 —— 은 Markdown to Word 가이드에서 이어집니다.
참고 자료
- Pandoc User's Guide —— CLI 변환의 정식 레퍼런스.
- GitHub Flavored Markdown Spec —— 이 가이드가 출력 대상으로 삼는 방언.
- Docling (IBM Research) —— 오픈소스 레이아웃 인식 PDF 추출기.
- marker —— 학술 논문 처리에 강한 오픈소스 PDF-Markdown 변환기.
- pymupdf4llm —— PyMuPDF 위에 얹은 가벼운 markdown 추출 래퍼.
- OCRmyPDF —— 스캔본 PDF에 검색 가능한 텍스트 레이어를 덧붙입니다.