Da Word a Markdown: Guida Completa alla Migrazione nel 2026
Converti i documenti Word in Markdown pulito per flussi Git e Obsidian. Metodi reali testati su file DOCX, con soluzioni per tabelle, elenchi e immagini embedded.

La richiesta di solito arriva in modo apparentemente innocuo: "Riesci a spostare questi documenti Word nella wiki del team?"
Apri il drive condiviso. Trecento file .docx. Dieci anni di documentazione interna — policy, runbook, verbali di riunione, specifiche — sparsi in cartelle con nomi inconsistenti. Niente produce diff leggibili. Niente è cercabile in modo decente. E qualcuno ha deciso che tutto quanto deve finire in Markdown tracciato su Git entro la fine del trimestre.
Ho fatto due migrazioni del genere. La prima per un archivio compliance (circa 200 file), la seconda per una knowledge base di engineering (circa 500 file). In entrambi i casi la lezione è stata la stessa: la conversione da Word a Markdown non è un'operazione da un clic. È una pipeline — conversione, ispezione, pulizia — e la fase di pulizia è dove se ne va davvero il tempo.
In questa guida ti racconto cosa funziona nella pratica: i tre metodi di conversione che vale la pena conoscere, quali funzionalità di Word sopravvivono al viaggio (e quali si perdono in silenzio), e la checklist post-conversione che ti risparmia ore di correzioni manuali.
Perché spostare i documenti Word in Markdown?
Prima del come, due parole sul perché. Perché se il tuo team non ha chiarito la motivazione, la migrazione non reggerà nel tempo.
- Storia diffabile. Il
.docxdi Word è un bundle XML compresso. Per Git, due versioni appaiono come due blob binari casuali. Il Markdown è testo puro — ogni modifica è un diff leggibile. - Ricerca e grep.
rg "gestione incidenti" docs/gira in millisecondi su migliaia di file Markdown. L'equivalente su documenti Word richiede uno strumento di ricerca proprietario. - Automazione. Il Markdown è consumabile da generatori di siti statici, strumenti di documentazione (Docusaurus, MkDocs, Nextra), pipeline di ingestion per LLM, sistemi di CI e linter. Word è consumabile principalmente da Word.
- Longevità. I file di testo puro sopravvivono ai vendor. Il DOCX oggi è un formato stabile, ma l'orizzonte di compatibilità per
.doc(il vecchio formato binario) è già sfocato.
Se nulla di tutto questo si applica al tuo team, probabilmente non hai bisogno di migrare. Se anche solo uno di questi punti ti riguarda, sei nel posto giusto.
Cosa sopravvive alla conversione e cosa no
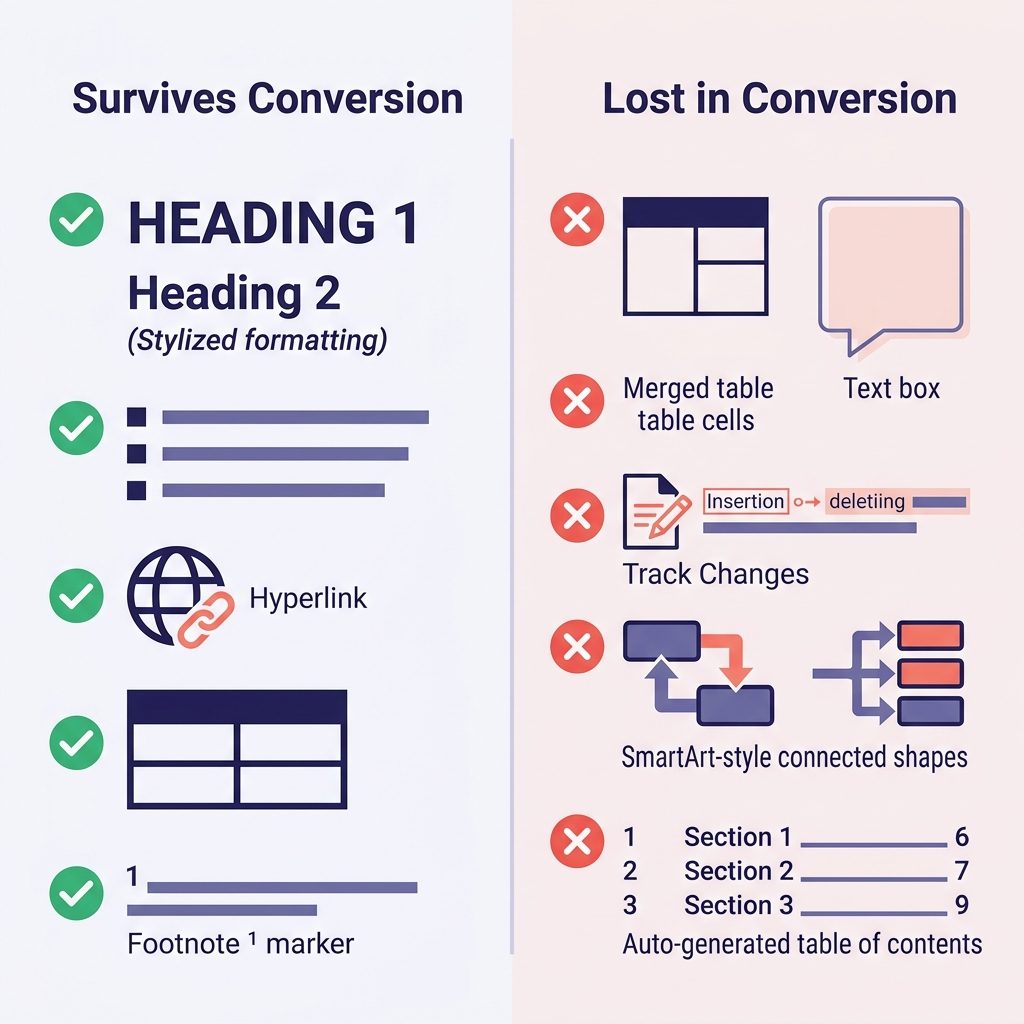
Definire le aspettative in anticipo è ciò che ti fa risparmiare più tempo. Ecco cosa ho osservato in centinaia di conversioni:
| Funzionalità Word | Sopravvive? | Note |
|---|---|---|
| Intestazioni (stili Heading 1–6) | Sì | Mappate direttamente su # fino a ###### |
| Grassetto, corsivo, sottolineato (bold, italic, underline) | Grassetto/corsivo sì | Il sottolineato non ha equivalente Markdown (diventa corsivo o HTML <u>) |
| Elenchi puntati e numerati | Di solito sì | I nidificati molto profondi a volte si appiattiscono |
| Collegamenti ipertestuali (hyperlinks) | Sì | URL e testo del link conservati |
| Tabelle (tables) | Sì, se semplici | Celle unite, colori e bordi si perdono |
| Immagini in linea (inline images) | Sì | Estratte in una cartella; i link vengono riscritti |
| Note a piè di pagina (footnotes) | Sì (GFM) | Convertite nella sintassi [^1] |
Codice (se formattato come paragrafo Code) | Dipende | Spesso si appiattisce in testo normale senza fence |
| Equazioni matematiche | Parziale | Può convertirsi in LaTeX; a volte si appiattisce |
| Revisioni (Track Changes) | No | Accetta o rifiuta tutte le modifiche prima |
| Commenti (Comments) | No | Risolvili o esportali separatamente prima della conversione |
| Caselle di testo, SmartArt, forme | No | Si perdono del tutto — sostituiscili con immagini o testo prima |
| Sommario generato automaticamente | No | Rigeneralo con il tuo strumento di documentazione |
| Campi Word (data, riferimenti incrociati) | No | Convertili in testo normale prima dell'esportazione |
Le sorprese più grosse in una migrazione sono di solito (1) formattazione che sembra un titolo ma in realtà era grassetto manuale con font più grande — diventano testo in grassetto senza struttura, e il tuo output rimane piatto — e (2) tabelle con celle unite, che collassano in modo antiestetico e richiedono ricostruzione manuale.
Prima di lanciare una conversione in batch, sfoglia dieci documenti di origine a caso e segnala questi problemi. Sono trenta minuti che prevengono un sacco di rilavorazioni.
Metodo 1: convertitore online
È quello che consiglio per file singoli e piccoli batch (sotto i 50 documenti circa). È il percorso più rapido da .docx a Markdown pulito, senza alcuna installazione.
- Apri il nostro convertitore da Word a Markdown
- Trascina il file
.docxnell'area di upload - Visualizza l'anteprima del Markdown convertito
- Scarica il file
.md(le immagini, quando presenti, vengono raggruppate a parte)
L'output usa GitHub Flavored Markdown (GFM), quindi tabelle, task list e footnote vengono preservate. Le intestazioni mappano sui livelli #, gli elenchi mantengono la gerarchia e i link conservano il testo dell'ancora.
Un dettaglio non banale: per i documenti standard la conversione avviene interamente nel browser. Per file molto grandi o quando lavori con materiale sensibile, tenere il file fuori dai server esterni è un vantaggio reale, non solo una frase da brochure.
I limiti di qualsiasi convertitore online (il nostro come qualunque altro) sono gli stessi: il processing in batch non è il suo punto forte e non puoi scriptarlo dentro una pipeline. Per quei casi, passa al Metodo 2.
Metodo 2: Pandoc (per batch e script)
Pandoc è il convertitore universale di documenti. È lo strumento che uso ogni volta che devo gestire più di una manciata di file, o quando devo rifinire l'output.
Il comando di base
pandoc document.docx -o document.md
Per un singolo file è tutto. Gira in fretta, produce output leggibile e gestisce out-of-the-box la maggior parte delle funzionalità Word comuni. Ma il vero valore di Pandoc emerge quando aggiungi i flag.
Tre flag che vale la pena conoscere
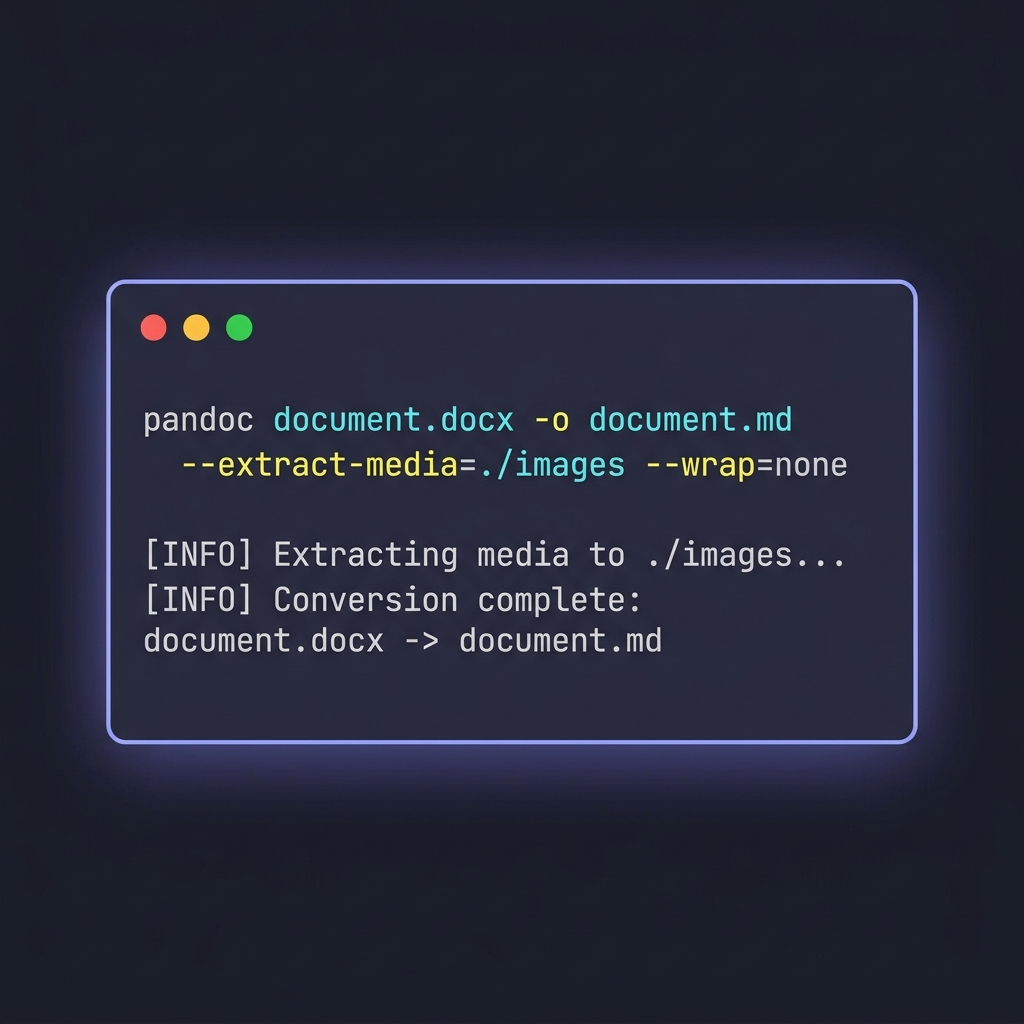
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— estrae dal DOCX le immagini embedded, le mette in una cartella e riscrive i link nell'output. Senza questo flag, le immagini in linea vengono eliminate in silenzio.--wrap=none— impedisce a Pandoc di andare a capo a circa 80 caratteri. Conta perché i wrap forzati rompono la leggibilità dei diff Git nei documenti con molto testo.--markdown-headings=atx— forza la sintassi# Titoloinvece del vecchio stile setext (righe sottolineate con====). ATX è la convenzione moderna.
Convertire una cartella in batch
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
Metti questo in uno script di shell e processi centinaia di file in pochi minuti. Per archivi più grandi, aggiungi trap e logging così puoi riprendere se qualcosa va storto a metà strada.
Inciampi concreti a cui fare attenzione
- I marker degli elenchi puntati variano. Pandoc a volte usa
-, a volte*. Se la coerenza ti interessa, passa unsed -i 's/^\* /- /g'sull'output, oppure configura il formatter Markdown del tuo editor. - Gli elenchi numerati ripartono in modo inatteso. Word ha spesso direttive "continua numerazione" che Pandoc non riesce a interpretare. Ti ritroverai elenchi che contano
1, 2, 1, 2, 3dove la fonte sembrava continua. Si risolve con un giro rapido di revisione. - Le tabelle con celle lunghe diventano illeggibili. Pandoc fa del suo meglio, ma le tabelle GFM non supportano interruzioni di riga nelle celle come fa Word. Per le tabelle particolarmente complesse valuta la conversione manuale in blocchi HTML.
Pandoc non ha GUI, che è sia un difetto (i colleghi non tecnici non lo possono usare) sia un pregio (si integra in qualunque pipeline CI/CD).
Metodo 3: conversione programmatica con Mammoth.js
Se stai costruendo una pipeline — diciamo, uno script di migrazione che tira giù file DOCX da SharePoint, li converte e li committa su Git — né una web UI né una chiamata a subprocess verso Pandoc potrebbero calzare nel tuo stack. Mammoth.js è una libreria JavaScript che converte DOCX in HTML o Markdown pulito direttamente in Node.js.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // l'output Markdown
console.log(result.messages); // avvisi su funzionalità non supportate
});
Quello che rende Mammoth utile è il suo approccio di parte: ignora completamente la formattazione visiva di Word e si concentra sulla struttura semantica (intestazioni, elenchi, tabelle). L'output è di default più pulito di quello di Pandoc, al prezzo di meno controllo. Per migrare un archivio legacy dove la maggior parte dei documenti ha struttura coerente, sceglierei Mammoth. Per documenti idiosincratici con formattazione pesante, vince la flessibilità di Pandoc.
Per chi lavora in Python esiste un'opzione simile con python-docx combinato con un writer Markdown, anche se è più una strada fai-da-te che uno strumento pronto all'uso.
La fase di pulizia di cui nessuno ti avverte

La conversione ti porta a un file .md. Non ti porta a un file .md che vuoi davvero committare.
Ecco la mia checklist standard post-conversione. Una volta che ci prendi la mano, ti porta via circa cinque minuti a documento:
- Cerca le intestazioni perse strutturalmente. Cerca nell'output righe che sembrano titoli ma sono in realtà
**Testo in Grassetto**da sole su una riga. Qualcuno le ha formattate a mano in Word invece di usare gli stili Heading. Promuovile a veri##. - Controlla la prima tabella. Se qui le tabelle sembrano a posto, probabilmente lo sono ovunque. Se la prima è rotta, lo sono tutte.
- Rimuovi le righe vuote dentro gli elementi dell'elenco. Pandoc a volte inserisce righe vuote che spezzano la continuità degli elenchi.
- Verifica i link alle immagini. Apri il file in un preview Markdown (quello integrato di VS Code va benissimo) e conferma che le immagini si carichino.
- Cerca artefatti residui. Resti tipici:
\a fine riga (interruzioni di riga forzate che Word nasconde ma Markdown mostra), attributi di stile{.underline}, tag<span>che si sono intrufolati. - Controlla le prime e le ultime 10 righe. Intestazioni, piè di pagina e numeri di pagina di Word spesso sgocciolano nell'output come contenuto vuoto o artefatti strani.
Per una migrazione grande, automatizza i punti 5 e 6 con uno script di pulizia. Tutto il resto beneficia di occhi umani — almeno finché non hai sviluppato abbastanza pattern recognition da fidarti dell'output per una specifica classe di documenti.
Una migrazione reale: archivio compliance da 200 file
Ecco il workflow che ho usato per la migrazione dell'archivio compliance. Dall'inizio alla fine, sono stati due giorni di lavoro su 200 file.
Giorno 1 mattina: triage della fonte
Ho scritto uno script Python che apriva ogni DOCX, contava intestazioni, immagini e tabelle, e segnalava ogni file con Track Changes ancora attivo o con commenti presenti. L'output era un CSV con i file ordinati per complessità. L'obiettivo non era sistemare nulla ancora — solo sapere cosa mi aspettava.
Giorno 1 pomeriggio: conversione batch dei file semplici
Circa 140 file su 200 erano lineari: niente immagini, tabelle semplici, struttura dei titoli pulita. Li ho fatti girare in Pandoc in un loop con --extract-media e --wrap=none. Ho controllato a campione 20 file casuali. Tutto a posto.
Giorno 2 mattina: gestire individualmente i file complessi
I restanti 60 avevano problemi — celle di tabella unite, oggetti Excel embedded, o una storia di Track Changes consistente che qualcuno doveva revisionare prima. Per questi ho usato il convertitore online caso per caso, a volte rilanciando Pandoc con flag diversi, a volte ripulendo prima il DOCX di origine.
Giorno 2 pomeriggio: pulizia e commit
Ho passato uno script di pulizia su tutti i 200 file convertiti (rimozione degli artefatti {.underline}, uniformazione dei marker degli elenchi, correzione del wrap di Pandoc). Ho revisionato i diff, committato in batch da 50, pushato sul branch di migrazione.
Se avessi provato a farlo a mano — aprire ogni documento Word e incollare in un editor Markdown — sarebbero state almeno due settimane. Gli strumenti di conversione non sono opzionali; sono ciò che rende il progetto fattibile.
Problemi frequenti e rimedi
Le tabelle sembrano sbagliate nell'anteprima Markdown
Il novanta per cento delle volte, la fonte aveva celle unite o contenuti di cella molto lunghi. Le tabelle GFM non supportano né l'una né l'altra cosa in modo elegante. Le tue opzioni: ricostruire la tabella manualmente in GFM, usare un blocco HTML <table> dentro il Markdown (supportato dalla maggior parte dei renderer), o spezzare la tabella in più tabelle più semplici.
Le immagini non vengono mostrate
Controlla se il convertitore le ha estratte. Pandoc non lo fa se non usi --extract-media. I convertitori online di solito ti fanno scaricare uno zip con il file Markdown più una cartella images/ — assicurati che entrambi siano finiti al posto giusto e che i percorsi nel Markdown combacino.
L'output ha strani backslash a fine riga
Sono interruzioni di riga forzate di Word che il Markdown interpreta come break forzati. Se il documento Word di partenza era pieno di spaziature strette fatte con line break invece che con paragrafi, Pandoc le conserva. Un find-and-replace veloce su \\$ (fine riga) di solito risolve.
I livelli delle intestazioni sono sbagliati dopo la conversione
I documenti Word iniziano spesso con Heading 2 o Heading 3 (perché Heading 1 era riservato al frontespizio). La convenzione Markdown è partire da # (H1). A seconda di come il tuo sistema di documentazione rende i titoli, potresti dover alzare tutti i livelli di uno. sed va bene: sed -i 's/^## /# /; s/^### /## /; ...' file.md.
Il Markdown non somiglia per niente visivamente al documento Word
È previsto. Il Markdown descrive la struttura, non l'aspetto. Lo stile arriva dal sistema che renderizza il Markdown (GitHub, il tuo sito di docs, il tema MkDocs, ecc.). Se la fedeltà visiva è critica, il PDF è un target migliore — dai un'occhiata alla nostra guida da Markdown a PDF per flussi che preservano il design visivo.
Round-trip: dal Markdown di nuovo a Word
Una domanda naturale dopo aver migrato: "E se devo mandare un documento Markdown a uno stakeholder che apre solo Word?" È la conversione inversa — ed è un'operazione molto più pulita, perché i limiti del Markdown fanno sì che ci sia meno roba da tradurre. La guida da Markdown a Word copre quel flusso.
Per i team che fanno avanti e indietro tra i due formati con frequenza, il workflow che ho visto funzionare è: il Markdown è la source of truth in Git, gli export Word si fanno on demand quando qualcuno deve revisionare o annotare. Niente viene mai modificato in Word e rimergiato — in questo modo la migrazione non si sfilaccia lentamente.
In chiusura
La conversione da Word a Markdown è una migrazione, non una pressione di un pulsante. Gli strumenti fanno il lavoro pesante — il nostro convertitore online per i file singoli, Pandoc per i batch, Mammoth.js per le pipeline — ma il lavoro vero è l'ispezione prima della conversione e la pulizia dopo.
I due pattern che fanno risparmiare più tempo:
- Prima il triage. Capisci cosa c'è nel tuo archivio di origine prima di iniziare a convertire. Quindici minuti di campionamento prevengono ore passate a reagire alle sorprese.
- Metti in conto la pulizia. Prevedi cinque minuti a documento per la revisione e la rifinitura. Trattarla come una fase inevitabile ti tiene onesto su quanto durerà davvero la migrazione.
Se sei nuovo al Markdown e ti stai chiedendo che aspetto avrà l'output, parti da cos'è il Markdown e dalla guida alla sintassi di base. Per le funzionalità avanzate — tabelle, footnote, task list — il riferimento alla sintassi estesa copre quello che GFM supporta.
E se la tua migrazione arriva da Obsidian invece che da Word, la guida all'esportazione da Obsidian gestisce quel flusso end-to-end.