Come convertire PDF in Markdown nel 2026 (gratis + pronto per RAG)
Converti PDF in Markdown nel modo giusto nel 2026. Confronto tra strumenti online gratuiti, Pandoc ed estrattori basati su IA, con flussi RAG-ready e correzioni OCR.

Se ti è mai capitato di copiare e incollare un paragrafo da un PDF e di vederlo esplodere in un guazzabuglio di a-capo, trattini spezzati e formattazione perduta, sai già perché convertire PDF in Markdown è diventato un problema serio di workflow nel 2026.
I PDF sono la valuta universale per condividere documenti. Sono anche un pessimo formato sorgente. Nell'istante in cui vuoi alimentare quel contenuto in una pipeline RAG, inserirlo in un sito di documentazione o semplicemente archiviarlo nella tua app di note, ti serve testo strutturato: titoli come titoli, tabelle come tabelle, codice come codice.
Questa guida percorre tre strade oneste per convertire PDF in Markdown: un convertitore online senza installazione, Pandoc da riga di comando e la nuova generazione di estrattori basati su IA come marker e Docling. Ti mostrerò quale scegliere per quale compito, come sistemare le cose che rompono (tabelle, formule, pagine scansionate) e come spedire l'output in una pipeline LLM senza doverlo ripulire due volte.
Perché convertire PDF in Markdown?
Lo stesso problema di conversione continua a presentarsi in tre comunità diverse. Ognuna ha una ragione leggermente diversa per cui gliene importa, ma il formato di destinazione è lo stesso.
Alimentare pipeline RAG e LLM con testo pulito
Le pipeline di retrieval-augmented generation non amano il testo grezzo dei PDF. Artefatti delle interruzioni di pagina, layout a due colonne collassati in una sola, intestazioni e piè di pagina che si ripetono su ogni pagina: tutto questo diventa rumore nel database vettoriale e inquina il recupero.
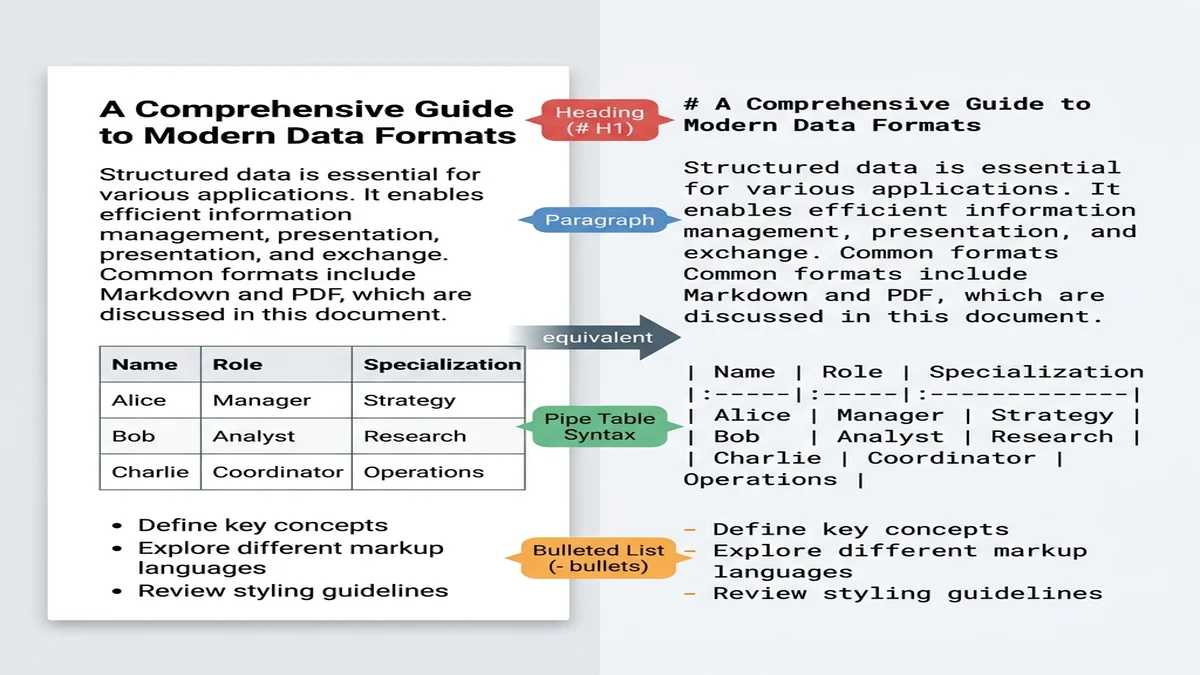
Markdown è il formato più vicino al "testo semplice strutturato" tra quelli pratici. I grandi modelli addestrati su dati web hanno visto miliardi di documenti markdown (file README, risposte di Stack Overflow, articoli di blog), quindi riconoscono i titoli # come confini di sezione e le pipe | come separatori di tabella senza bisogno di indicazioni.
Migrare PDF legacy in sistemi di documentazione moderni
Docusaurus, MkDocs, Astro Starlight e Hugo vogliono tutti markdown. Se il tuo team ha 200 PDF di documentazione interna legacy, non vuoi un'armata di copia-incolla: vuoi un convertitore che preservi la gerarchia dei titoli in modo che la navigazione si costruisca da sola.
Costruire un secondo cervello consultabile
Obsidian, Logseq, Foam, Roam: ogni app di note moderna parla markdown. Accademici che digitalizzano archivi cartacei, knowledge worker che archiviano resoconti di riunione e ricercatori che costruiscono librerie bibliografiche hanno tutti bisogno della stessa cosa: un file markdown pulito con i titoli intatti, così da poter fare grep su centinaia di documenti più avanti.
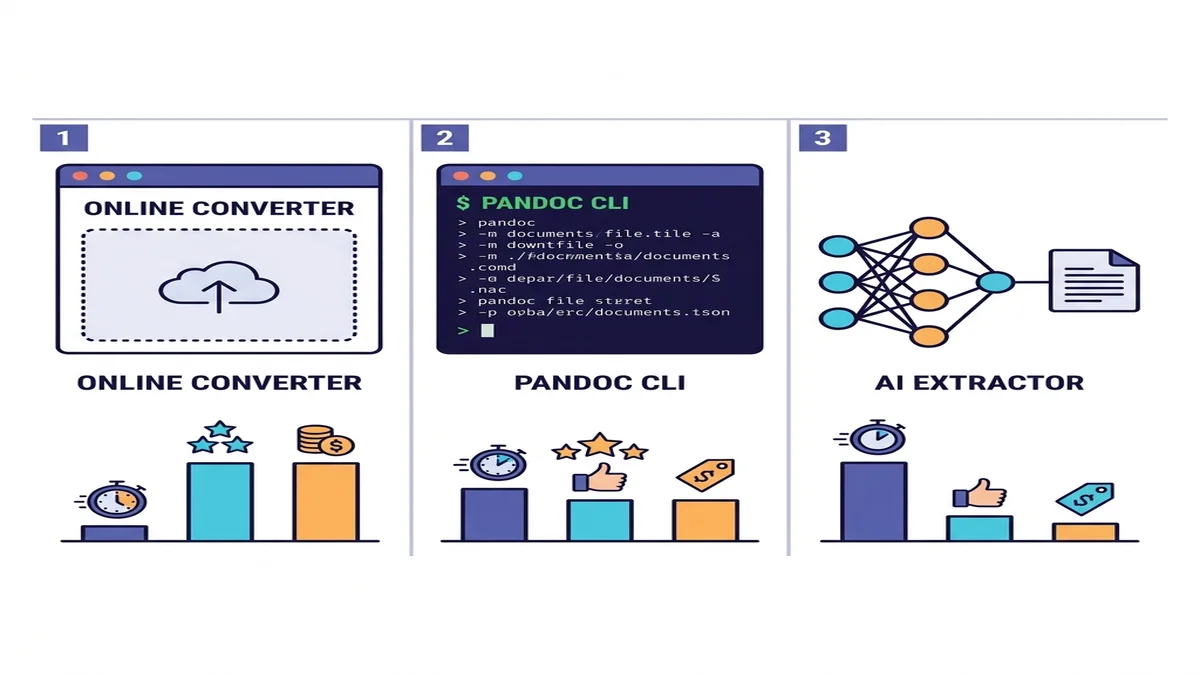
I tre approcci (quando usare ciascuno)
Esistono decine di strumenti, ma in realtà solo tre categorie. Scegli la riga che corrisponde alla tua situazione.
| Metodo | Velocità | PDF semplici | PDF complessi | OCR per scansioni | Setup |
|---|---|---|---|---|---|
| Convertitore online | Veloce | Eccellente | Buono | Integrato o automatico | Nessuno |
| Pandoc + pdftotext | Veloce | Buono | Mediocre sulle tabelle | No | Installazione CLI |
| Estrattore IA (marker / Docling) | Lento | Eccellente | Eccellente | Sì | Python + dipendenze ML |
Se non sei sicuro di quale scegliere, parti da un convertitore online. Ti costa un minuto provarlo e per la maggior parte dei lavori una tantum o piccoli batch la storia finisce lì. Per pipeline programmatiche o contenuti accademici densi, scendi di una riga. Mettiamo a confronto un panorama più ampio nella nostra rassegna sui convertitori Markdown gratuiti.
Metodo 1: Convertire PDF in Markdown online (gratis, senza installazione)
La strada più veloce è anche quella che la maggior parte delle persone salta perché sembra troppo semplice. Per una fetta enorme del lavoro quotidiano — note di riunione, articoli, report di un capitolo singolo — un convertitore browser-based è più che sufficiente.
Puoi trascinare direttamente il tuo file nel nostro convertitore gratuito PDF a Markdown e saltare il resto di questa sezione.
Workflow passo per passo
- Trascina il PDF nella zona di upload (oppure clicca per selezionare un file).
- Aspetta qualche secondo che il parser finisca. Qualunque cosa sotto le 20 pagine di solito si converte prima che tu finisca di leggere questa frase due volte.
- Visualizza l'anteprima del markdown renderizzato accanto al sorgente sulla destra.
- Copia il sorgente, oppure scarica un file
.md.
Tutto qui. Niente account, niente email obbligatoria, niente filigrane sull'output.
Quando funziona meglio
- Conversioni una tantum in cui non vuoi installare nulla.
- Controlli rapidi prima di decidere se investire in una pipeline programmatica.
- File sensibili dal punto di vista della privacy, dove preferiresti non spingere il documento dentro un'API di terze parti. Il nostro convertitore elabora i file in memoria e li elimina immediatamente: nessuna archiviazione persistente.
Limiti
I convertitori online in generale (non solo il nostro) hanno due modalità di fallimento da conoscere.
La prima sono i PDF molto grandi o insoliti. Una comunicazione legale scansionata di 600 pagine con font incorporati e campi modulo dinamici non è uno scenario "trascina e scarica" per nessuno strumento. Se ne hai uno così, salta alla sezione sull'estrattore IA.
La seconda sono i PDF scansionati senza un livello di testo. Non c'è testo da estrarre: la pagina è solo un'immagine. Serve prima l'OCR; vedi Gestire contenuti spinosi qui sotto.
Metodo 2: Pandoc da riga di comando
Pandoc è il coltellino svizzero della conversione di documenti. È lo strumento giusto quando ti serve una pipeline riproducibile, scriptabile, e non vuoi dipendere da un servizio web.
L'inghippo onesto: Pandoc da solo non ha un lettore PDF forte. Il workflow della community passa per pdftotext (dalle utility Poppler) e convoglia il risultato dentro Pandoc.
# Estrai il testo preservando il layout, poi converti in GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
Per un PDF semplice e ricco di testo — un memo, un articolo a colonna singola — questa combinazione funziona bene e gira in millisecondi.
Quando la fedeltà conta
Se il tuo PDF è per lo più prosa, questa pipeline ti restituisce un file markdown pulito con la struttura dei paragrafi intatta. Aggiungi i flag -V e --wrap=none per affinare l'output per strumenti a valle che non amano le righe spezzate forzatamente.
Dove Pandoc fatica
- Layout a più colonne (paper accademici, riviste):
pdftotextintreccia le colonne e ottieni un output illeggibile. - Tabelle: qualunque cosa oltre la griglia a due colonne più semplice di solito arriva come colonne separate da spazi invece che da pipe markdown.
- Formule e blocchi di codice: nessuna conservazione semantica; le equazioni LaTeX diventano testo, il monospazio del codice diventa paragrafi normali.
- PDF scansionati: supporto zero — Pandoc/pdftotext non sanno estrarre testo dalle immagini.
Per le tabelle in particolare, la nostra guida alla sintassi Markdown estesa copre il formato di tabella GFM con cui vorrai allineare l'output.
Metodo 3: Estrazione basata su IA (marker, Docling, pymupdf4llm)
L'ondata 2024-2025 di estrattori sensibili al layout ha cambiato ciò che è possibile. Questi strumenti combinano il rilevamento visivo del layout con l'OCR e la generazione di output strutturato, così capiscono che questa regione è una tabella e quella regione è un corpo di testo a due colonne. L'output è drasticamente più pulito sui PDF complessi.
Tre progetti che vale la pena conoscere:
- marker — usa surya (un modello di layout) più euristiche. Forte su paper accademici, formule e blocchi di codice. Apache 2.0.
- Docling — da IBM Research. Eccellente ricostruzione delle tabelle, si integra in modo nativo con LlamaIndex e LangChain. Licenza MIT.
- pymupdf4llm — wrapper leggero attorno a PyMuPDF. Più veloce degli altri due, meno dipendenze ML, progettato specificamente per l'ingestion da LLM.
Un esempio Python minimo
Ecco la pipeline Docling utile più piccola:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
Oppure con pymupdf4llm per la via più leggera:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
Compromessi
Questi strumenti sono più lenti della pipeline Pandoc. Su un tipico laptop con CPU, aspettati che un paper di 30 pagine richieda decine di secondi invece di millisecondi; con una GPU, scende di nuovo a pochi secondi per marker. pymupdf4llm è il più veloce dei tre perché salta i modelli di visione pesanti.
L'altro compromesso è il peso delle dipendenze. Un pip install marker-pdf tira dentro PyTorch e qualche centinaio di megabyte di pesi del modello. Se stai spedendo questo in un container, pianifica le dimensioni.
Gestire contenuti spinosi
Le differenze tra i metodi diventano evidenti quando smetti di testare su memo puliti di due pagine e cominci a far passare PDF del mondo reale.
Tabelle che non sopravvivono
Le tabelle sono il punto in cui la maggior parte dei convertitori fallisce. La via pdftotext + Pandoc produce quasi sempre una zuppa di colonne allineate con spazi che nessun renderer markdown analizzerà correttamente. I convertitori online e gli estrattori IA fanno molto meglio qui perché rilevano prima la regione della tabella e poi ricostruiscono le celle.
Il trucco: controlla a campione la prima tabella in uscita prima di fidarti del resto. Se la prima tabella è massacrata, lo saranno anche le altre 50.
Equazioni matematiche e blocchi LaTeX
Se il tuo PDF contiene equazioni, ti serve uno strumento che rilevi le regioni matematiche ed emetta blocchi LaTeX ($$...$$) nel markdown. marker lo fa; Pandoc no. Per la scrittura scientifica è il singolo motivo più importante per pagare il costo in velocità di un estrattore IA.
Blocchi di codice e codice inline
Molti PDF renderizzano il codice in un font monospazio ma perdono il tag semantico "questo è codice" nell'export. Gli estrattori IA rilevano di nuovo le regioni di codice in base allo stile visivo — il font monospazio e l'indentazione — e le riavvolgono in recinti a triplo backtick. Le pipeline basate su Pandoc di solito riducono il codice a paragrafi normali.
Note a piè di pagina e citazioni
I paper accademici usano note numerate con il corpo della nota in fondo alla pagina. La via pdftotext perde il collegamento tra il marker di riferimento e il corpo della nota. Docling e marker li preservano come sintassi propria di nota markdown (riferimento [^1] + definizione [^1]: corpo).
PDF scansionati (OCR richiesto)
Un PDF scansionato è un'immagine di una pagina, non testo. Non c'è nulla da estrarre finché non esegui prima l'OCR.

Tre strade affidabili:
-
ocrmypdf — aggiunge un livello di testo OCR invisibile a un PDF scansionato senza modificarne l'aspetto visivo. Una volta stratificato, qualunque convertitore a valle funziona:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
Estrattori IA con modalità OCR — marker e Docling sanno rilevare quando una pagina non ha un livello di testo e lanciare l'OCR in automatico. L'output è integrato, quindi ottieni un singolo file markdown invece di un PDF intermedio.
-
Convertitori online con OCR automatico — alcuni strumenti browser (incluso il nostro per PDF di sole immagini) eseguono l'OCR in modo trasparente. Comodo, ma fai attenzione al supporto linguistico se il tuo documento non è in inglese.
Una trappola sottile: i PDF "born-digital" (creati da un documento Word, non scansionati) possono comunque non avere un livello di testo se sono stati esportati come immagini appiattite. Controlla sempre prima se riesci a selezionare il testo dentro il viewer PDF. Se ci riesci, salta l'OCR. Se non ci riesci, eseguilo.
Preparare il Markdown per l'ingestion RAG / LLM
Se la destinazione è un database vettoriale, alcune piccole scelte durante la conversione rendono la qualità del recupero molto migliore a valle.
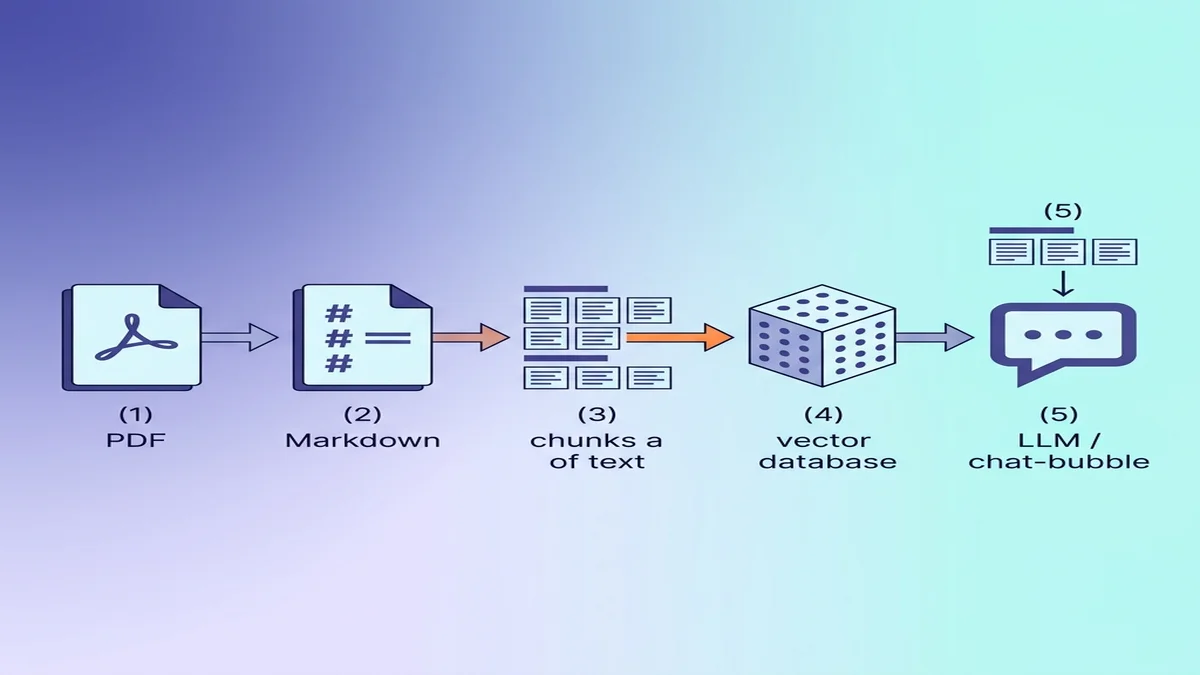
Perché Markdown batte il testo grezzo per gli LLM
Markdown porta con sé una struttura che il testo semplice perde. Un modello che legge ## Metodi sa di essere entrato in una nuova sezione; un modello che legge lo stesso testo senza formattazione vede solo paragrafi di peso equivalente. Se sei nuovo alla sintassi, la nostra guida Markdown di base si legge in 5 minuti.
Chunking per gerarchia dei titoli
L'errore RAG più comune è il chunking a dimensione fissa — spezzare il documento in blocchi da 500 token a prescindere dalla struttura. Markdown ti permette di fare chunking semantico — spezza sui confini ## H2 e ottieni sezioni coerenti invece di frammenti a metà paragrafo.
# Chunk grossolano: spezza su H2
sections = markdown.split("\n## ")
# Ogni sezione ora inizia con un titolo di sezione e contiene il suo sotto-albero
Meglio: percorri i titoli come un albero, attaccando ogni H3 al suo H2 padre nei metadati del chunk.
Preservare i metadati nel frontmatter
Aggiungi un frontmatter YAML in cima a ogni file convertito così le informazioni sulla sorgente viaggiano con ogni chunk:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
Quando l'LLM recupera un chunk, questi metadati diventano il piè di pagina della citazione. È anche il modo in cui rispondi prima o poi alla domanda "da dove arriva questa affermazione?" senza ri-eseguire il retrieval. Se stai costruendo questo tipo di pipeline partendo da export di chat, la stessa idea vale per le trascrizioni ChatGPT/Claude.
Trappole comuni e come evitarle
Alcune cose pungono chi affronta questo lavoro per la prima volta.
- Saltare la normalizzazione della codifica. I PDF adorano i trucchi Unicode: legature (
fi,fl), virgolette tipografiche ("vs"), trattini lunghi che sembrano trattini. Fai passare l'output attraverso una normalizzazione Unicode (NFKC in Python) prima di darlo in pasto a qualsiasi cosa. - Lasciare dentro intestazioni e piè di pagina. Ogni piè di pagina
Pagina 4 di 12diventa rumore nel tuo retrieval. Elimina le righe ripetute che compaiono a intervalli regolari. - Fidarsi della prima tabella che vedi. Controlla a campione almeno le prime due tabelle prima di dare per scontato che il resto sia a posto.
- Assumere che "born-digital" significhi "ha un livello di testo". Alcuni PDF vengono esportati come immagini appiattite anche se sono partiti come documenti Word. Prova sempre prima a selezionare il testo.
- Frammentare troppo documenti piccoli. Per un memo di 3 pagine, dai semplicemente l'intero markdown al modello e salta del tutto lo step RAG. Il retrieval è esagerato quando la finestra di contesto è più grande del documento.
FAQ
Qual è il miglior convertitore gratuito PDF a Markdown?
Per la maggior parte degli utenti un convertitore online è la strada più veloce: trascina, lascia, fatto. Per il lavoro batch o programmatico, pymupdf4llm (Python) e Pandoc (CLI) coprono i casi semplici. Per paper accademici con tabelle e formule, marker e Docling producono output sensibilmente migliori. La scelta "migliore" dipende dal fatto che tu ottimizzi per tempo di setup o per fedeltà di output.
ChatGPT o Claude possono convertire PDF in Markdown?
Possono, con riserve. Entrambi sanno leggere un PDF direttamente e produrre output markdown, ma su documenti lunghi puoi sbattere contro i limiti di contesto e l'accuratezza su tabelle e formule varia da una run all'altra. Per conversioni batch deterministiche un convertitore dedicato è più affidabile. Vedi esportare ChatGPT in Word/PDF/HTML per il workflow di andata e ritorno correlato.
Come si converte un PDF scansionato in Markdown?
Esegui prima l'OCR. La strada più pulita è ocrmypdf per aggiungere un livello di testo, poi qualunque convertitore funziona sul PDF con OCR. In alternativa, marker e Docling hanno l'OCR integrato e producono markdown direttamente da PDF di sole immagini.
La conversione online PDF-Markdown è privata?
Con il nostro convertitore, i file vengono elaborati in memoria ed eliminati dopo la conversione: nessun account richiesto, nessuna archiviazione persistente. Altri servizi variano; controlla la privacy policy di qualunque strumento usi, specie per documenti riservati.
Come tengo intatte le tabelle quando converto PDF in Markdown?
Evita la pipeline pdftotext + Pandoc per PDF ricchi di tabelle: le maciulla quasi sempre. Usa un convertitore online che emette tabelle GFM, oppure un estrattore IA come marker o Docling. In entrambi i casi controlla a campione le prime tabelle.
Conviene tenere il PDF originale o solo il Markdown?
Tieni entrambi. Il markdown è per ingestion, ricerca e modifica. Il PDF è la tua fonte di verità per citazione e audit. Riporta il nome del file PDF e l'intervallo di pagine nel frontmatter markdown così puoi sempre risalire da un'affermazione alla sua sorgente.
Pronto a convertire il tuo primo PDF?
Se vuoi solo il risultato, il nostro convertitore gratuito PDF a Markdown gestisce i casi quotidiani senza registrazione. Per il passo successivo — trasformare quel markdown in un documento Word rifinito o in un PDF pronto per la condivisione — vedi la nostra guida Markdown a Word.
Riferimenti
- Pandoc User's Guide — il riferimento canonico per la conversione da CLI.
- GitHub Flavored Markdown Spec — il dialetto che questa guida prende come target di output.
- Docling (IBM Research) — estrattore PDF open source consapevole del layout.
- marker — convertitore PDF-markdown open source con forte gestione dei paper accademici.
- pymupdf4llm — wrapper leggero per estrazione markdown attorno a PyMuPDF.
- OCRmyPDF — aggiunge un livello di testo cercabile ai PDF scansionati.