Word vers Markdown : guide complet de migration en 2026
Convertissez vos documents Word en Markdown propre pour Git et Obsidian. Méthodes éprouvées sur des fichiers DOCX réels, avec les correctifs pour tableaux, listes et images.

La demande arrive souvent sous une forme trompeusement simple : « Tu peux migrer ces documents Word dans notre wiki d'équipe ? »
Vous ouvrez le lecteur partagé. Trois cents fichiers .docx. Une décennie de documentation interne — politiques, runbooks, comptes rendus de réunion, spécifications — éparpillée dans des dossiers aux noms incohérents. Rien ne produit un diff propre. Rien n'est vraiment recherchable. Et quelqu'un a décidé que tout cela devait vivre dans du Markdown versionné avec Git d'ici la fin du trimestre.
J'ai fait cette migration deux fois. Une première pour une archive de conformité (environ 200 fichiers), une seconde pour une base de connaissances d'ingénierie (environ 500 fichiers). À chaque fois, la même leçon : la conversion Word vers Markdown n'est pas une opération en un clic. C'est un pipeline — conversion, inspection, nettoyage — et c'est l'étape de nettoyage qui absorbe réellement le temps.
Ce guide couvre ce qui fonctionne en pratique : les trois méthodes de conversion à connaître, ce que les fonctionnalités Word conservent (ou perdent silencieusement) pendant le trajet, et la checklist post-conversion qui vous épargne des heures de correction manuelle.
Pourquoi migrer vos documents Word vers Markdown ?
Avant le comment, un rapide pourquoi. Parce que si votre équipe n'a pas clairement formulé la raison, la migration ne tiendra pas dans le temps.
- Historique diffable. Le format
.docxde Word est une archive ZIP de XML. Pour Git, deux versions ressemblent à deux blobs binaires aléatoires. Le Markdown est du texte brut — chaque changement devient un diff lisible. - Recherche et grep.
rg "incident response" docs/s'exécute en quelques millisecondes sur des milliers de fichiers Markdown. L'équivalent sur des fichiers Word exige un outil de recherche propriétaire. - Automatisation. Le Markdown est consommable par les générateurs de sites statiques, les outils de documentation (Docusaurus, MkDocs, Nextra), les pipelines d'ingestion pour LLM, les systèmes de CI/CD et les linters. Word n'est consommable que par Word, à peu de choses près.
- Longévité. Les fichiers texte brut survivent aux éditeurs logiciels. DOCX est un format stable aujourd'hui, mais l'horizon de compatibilité du
.doc(l'ancien format binaire) est déjà flou.
Si aucun de ces arguments ne concerne votre équipe, vous n'avez probablement pas besoin de migrer. Si ne serait-ce qu'un seul s'applique, vous êtes au bon endroit.
Ce qui survit à la conversion, et ce qui disparaît
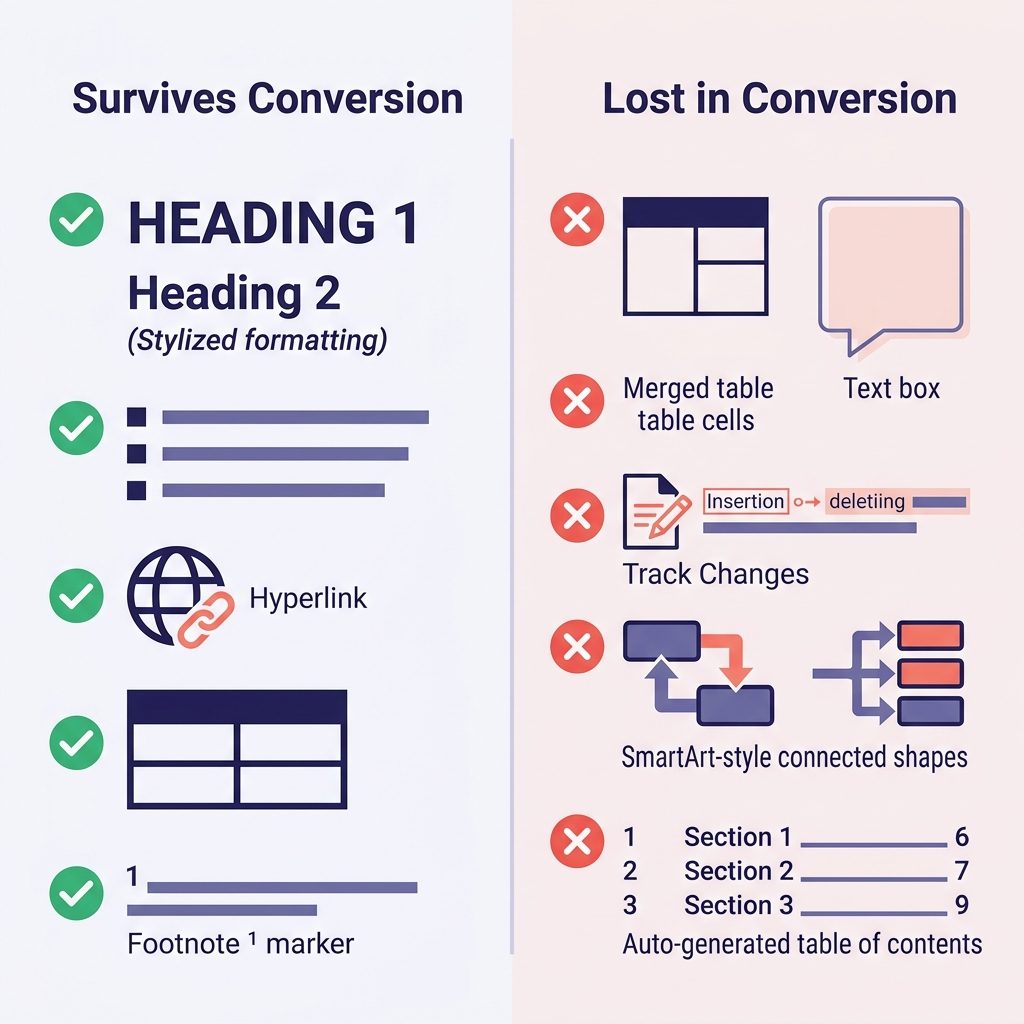
Poser d'emblée les bonnes attentes, c'est ce qui fait gagner le plus de temps. Voici ce que j'ai observé sur des centaines de conversions :
| Fonctionnalité Word (Word Feature) | Survit ? | Remarques |
|---|---|---|
| Titres (styles Heading 1–6) | Oui | Se mappent directement sur # à ###### |
| Gras, italique, souligné (bold, italic, underline) | Gras/italique oui | Le souligné n'a pas d'équivalent Markdown (devient italique ou HTML <u>) |
| Listes à puces et numérotées | Généralement | L'imbrication profonde s'aplatit parfois |
| Liens hypertextes | Oui | URL et texte du lien préservés |
| Tableaux | Simples oui | Cellules fusionnées, couleurs, bordures sont perdues |
| Images intégrées | Oui | Extraites dans un dossier ; les liens sont réécrits |
| Notes de bas de page | Oui (GFM) | Converties en syntaxe [^1] |
Code (si stylé en paragraphe Code) | Dépend | Souvent aplati en texte brut sans bloc de code |
| Équations mathématiques | Partiel | Peut se convertir en LaTeX ; parfois aplati |
| Suivi des modifications (Track Changes) | Non | Acceptez ou rejetez toutes les modifications avant |
| Commentaires | Non | Résolvez ou exportez séparément avant de convertir |
| Zones de texte, SmartArt, formes | Non | Totalement perdus — remplacez par des images ou du texte avant |
| Table des matières auto-générée | Non | Régénérez avec votre outil de documentation |
| Champs Word (date, renvois croisés) | Non | Convertissez en texte brut avant l'export |
Les plus grosses surprises lors d'une migration viennent généralement (1) d'une mise en forme qui ressemble à un titre mais qui n'est en réalité que du gras manuel avec une police plus grosse — cela devient du texte en gras sans structure dans la sortie — et (2) des tableaux avec cellules fusionnées, qui s'effondrent de façon peu esthétique et doivent être reconstruits à la main.
Avant de lancer une conversion en lot, parcourez dix documents sources au hasard et repérez ces problèmes. Cela prend trente minutes et évite beaucoup de retouches.
Méthode 1 : convertisseur en ligne
C'est la méthode que je recommande pour les fichiers isolés et les petits lots (moins de ~50 documents). C'est le chemin le plus rapide entre un .docx et un Markdown propre, sans aucune installation.
- Ouvrez notre convertisseur Word vers Markdown
- Glissez le fichier
.docxdans la zone d'upload - Prévisualisez le Markdown converti
- Téléchargez le fichier
.md(les images sont fournies séparément le cas échéant)
La sortie utilise GitHub Flavored Markdown (GFM), donc les tableaux, listes de tâches et notes de bas de page sont préservés. Les titres se mappent sur les niveaux #, les listes conservent leur hiérarchie, et les liens hypertextes gardent leur texte d'ancre.
À noter : pour les documents standards, toute la conversion se fait dans le navigateur. Pour de très gros fichiers ou quand vous manipulez du contenu sensible, garder le fichier hors des serveurs externes est un vrai atout, pas seulement un argument marketing.
Les limites de n'importe quel convertisseur en ligne (le nôtre comme les autres) sont les mêmes : le traitement par lots n'est pas idéal, et on ne peut pas le scripter dans un pipeline. Pour ces cas-là, passez à la méthode 2.
Méthode 2 : Pandoc (pour les lots et les scripts)
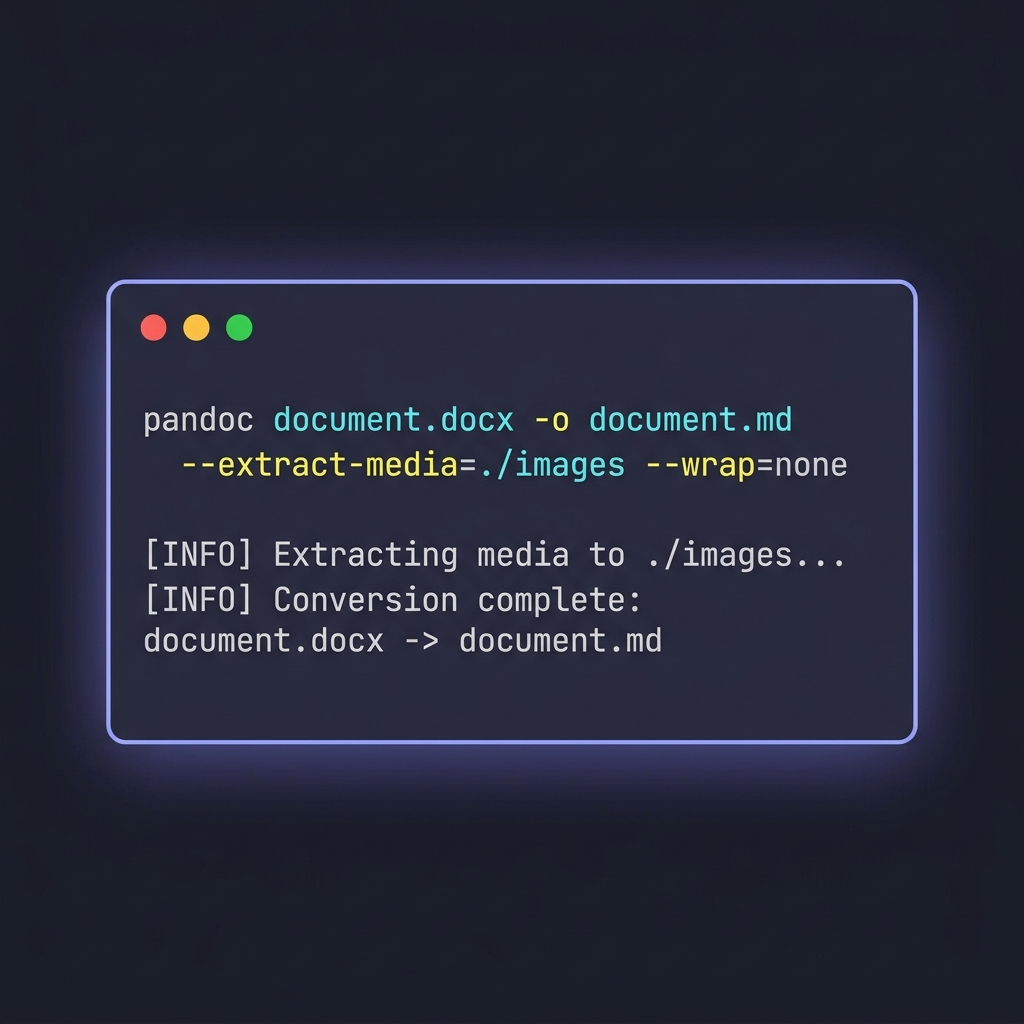
Pandoc est le convertisseur de documents universel. C'est l'outil que j'utilise dès qu'il s'agit de plus d'une poignée de fichiers, ou quand j'ai besoin d'affiner la sortie.
La commande de base
pandoc document.docx -o document.md
C'est tout pour un fichier unique. Ça s'exécute vite, produit une sortie lisible, et gère la plupart des fonctionnalités Word courantes d'entrée de jeu. Mais la vraie valeur de Pandoc se révèle quand on ajoute des flags.
Trois flags à connaître
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— extrait les images intégrées au DOCX, les place dans un dossier et réécrit les liens d'image dans la sortie. Sans ce flag, les images intégrées sont silencieusement perdues.--wrap=none— empêche Pandoc d'ajouter des retours à la ligne forcés autour de 80 caractères. Important, car ces retours forcés cassent la lisibilité des diffs Git sur des documents riches en prose.--markdown-headings=atx— force la syntaxe# Titreplutôt que l'ancien style setext (lignes soulignées par====). ATX est la convention moderne.
Convertir un dossier en lot
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
Mettez ça dans un script shell et vous pouvez traiter des centaines de fichiers en quelques minutes. Pour de plus grosses archives, ajoutez un trap et des logs pour pouvoir reprendre si quelque chose plante en cours de route.
Les petits accrocs du monde réel
- Les marqueurs de puces varient. Pandoc utilise parfois
-, parfois*. Si la cohérence vous importe, lancezsed -i 's/^\* /- /g'sur la sortie, ou configurez le formateur Markdown de votre éditeur. - Les listes numérotées redémarrent de façon inattendue. Word a souvent des directives « continuer la numérotation » que Pandoc ne sait pas interpréter. Vous verrez des listes qui comptent
1, 2, 1, 2, 3là où la source paraissait continue. Corrigeable avec une passe de relecture rapide. - Les tableaux avec des cellules longues deviennent peu lisibles. Pandoc fait de son mieux, mais les tableaux GFM ne gèrent pas les retours à la ligne dans les cellules comme Word. Pour les tableaux particulièrement complexes, envisagez de les passer en blocs HTML à la main.
Pandoc n'a pas d'interface graphique, ce qui est à la fois un inconvénient (vos collègues non techniques ne peuvent pas l'utiliser) et un avantage (il s'intègre à n'importe quel pipeline CI/CD).
Méthode 3 : conversion programmatique avec Mammoth.js
Si vous construisez un pipeline — disons, un script de migration qui récupère des fichiers DOCX depuis SharePoint, convertit et commit sur Git — ni une interface web ni un appel à Pandoc en sous-processus ne conviendront forcément à votre stack. Mammoth.js est une bibliothèque JavaScript qui convertit DOCX en HTML propre ou en Markdown directement dans Node.js.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // the Markdown output
console.log(result.messages); // warnings about unsupported features
});
Ce qui rend Mammoth utile, c'est son parti pris : il ignore complètement le style visuel de Word et se concentre sur la structure sémantique (titres, listes, tableaux). La sortie est plus propre que celle de Pandoc par défaut, au prix d'un moindre contrôle. Pour migrer une archive historique où la plupart des documents ont une structure homogène, je me tournerais vers Mammoth. Pour des documents capricieux avec une mise en forme lourde, la flexibilité de Pandoc l'emporte.
Les utilisateurs Python ont une option similaire avec python-docx combiné à un writer Markdown, même si c'est plus un bricolage maison qu'un outil prêt à l'emploi.
L'étape de nettoyage dont personne ne vous parle

La conversion vous amène à un fichier .md. Elle ne vous amène pas à un fichier .md que vous avez envie de commiter.
Voici ma checklist post-conversion standard. Elle prend environ cinq minutes par document une fois que vous avez l'habitude :
- Cherchez les titres manqués structurellement. Repérez dans la sortie les lignes qui ressemblent à des titres mais sont en fait du
**Texte en gras**isolé. Quelqu'un les a stylés à la main dans Word au lieu d'utiliser les styles de titre. Promouvez-les en vrais titres##. - Vérifiez le premier tableau. Si les tableaux sont corrects ici, ils le seront probablement partout. Si le premier est cassé, ils le sont tous.
- Supprimez les lignes vides dans les éléments de liste. Pandoc insère parfois des lignes blanches qui cassent la continuité des listes.
- Vérifiez les liens d'images. Ouvrez le fichier dans un aperçu Markdown (celui intégré à VS Code fait l'affaire) et confirmez que les images se chargent.
- Cherchez les artefacts résiduels. Les plus courants :
\en fin de ligne (retours forcés que Word masque mais que Markdown affiche), attributs de style{.underline}, balises<span>qui se sont glissées dans la sortie. - Vérifiez les 10 premières et les 10 dernières lignes. Les en-têtes, pieds de page et numéros de page de Word finissent souvent dans la sortie sous forme de contenu vide ou d'artefacts bizarres.
Pour une grosse migration, automatisez les points 5 et 6 avec un script de nettoyage. Tout le reste gagne à être revu par un œil humain — au moins jusqu'à ce que vous ayez bâti assez de reconnaissance de motifs pour faire confiance à la sortie sur une classe de documents précise.
Une vraie migration : archive de conformité de 200 fichiers
Voici le workflow que j'ai utilisé pour la migration de l'archive de conformité. De bout en bout, c'était deux jours de travail sur 200 fichiers.
Jour 1 matin : triage de la source
J'ai écrit un script Python qui ouvrait chaque DOCX, comptait les titres, images et tableaux, et signalait tout ce qui avait encore Track Changes actif ou des commentaires présents. La sortie était un CSV de fichiers triés par complexité. L'objectif n'était pas encore de corriger quoi que ce soit — juste de savoir dans quoi je mettais les pieds.
Jour 1 après-midi : conversion en lot des fichiers simples
Environ 140 des 200 fichiers étaient simples : pas d'images, tableaux basiques, structure de titres propre. Je les ai passés dans Pandoc en boucle avec --extract-media et --wrap=none. J'ai échantillonné 20 fichiers au hasard. Tout bon.
Jour 2 matin : traitement individuel des fichiers complexes
Les 60 restants avaient des problèmes — cellules de tableau fusionnées, objets tableurs intégrés, ou historique de Track Changes conséquent que quelqu'un devait relire avant. Pour ceux-là, j'ai utilisé le convertisseur en ligne au cas par cas, parfois en relançant Pandoc avec d'autres flags, parfois en nettoyant d'abord le DOCX source.
Jour 2 après-midi : nettoyage et commit
J'ai fait tourner un script de nettoyage sur les 200 fichiers convertis (suppression des artefacts {.underline}, uniformisation des marqueurs de puces, correction des retours à la ligne laissés par Pandoc). J'ai relu les diffs, commité par lots de 50, et poussé sur la branche de migration.
Si j'avais tenté de faire quoi que ce soit de tout ça manuellement — ouvrir chaque document Word et coller dans un éditeur Markdown — ça aurait représenté au moins deux semaines de travail. Les outils de conversion ne sont pas optionnels ; ce sont eux qui rendent le projet faisable.
Problèmes courants et correctifs
Les tableaux s'affichent mal dans l'aperçu Markdown
Dans 90 % des cas, la source contenait des cellules fusionnées ou du contenu de cellule très long. Les tableaux GFM ne gèrent ni l'un ni l'autre avec élégance. Vos options : reconstruire le tableau à la main en GFM, utiliser un bloc HTML <table> dans le Markdown (pris en charge par la plupart des moteurs de rendu), ou scinder le tableau en plusieurs tableaux plus simples.
Les images ne s'affichent pas
Vérifiez que le convertisseur les a bien extraites. Pandoc ne le fait pas sans --extract-media. Les convertisseurs en ligne fournissent généralement un zip avec le fichier Markdown plus un dossier images/ — assurez-vous que les deux atterrissent au bon endroit et que les chemins d'image dans le Markdown correspondent.
La sortie contient des antislashs bizarres en fin de ligne
Ce sont des retours à la ligne forcés venus de Word que Markdown rend comme des sauts de ligne imposés. Si le document Word source était plein d'espacements de paragraphe serrés utilisant des sauts de ligne au lieu de sauts de paragraphe, Pandoc les conserve. Un rapide rechercher-remplacer sur \\$ (fin de ligne) règle généralement le problème.
Les niveaux de titre sont faux après conversion
Les documents Word commencent souvent à Heading 2 ou Heading 3 (parce que Heading 1 était réservé à la page de titre). La convention Markdown est de partir de # (H1). Selon la façon dont votre système de documentation affiche les titres, il vous faudra peut-être remonter tous les niveaux d'un cran. sed fait le travail : sed -i 's/^## /# /; s/^### /## /; ...' file.md.
Le Markdown ne ressemble pas du tout visuellement au document Word
C'est normal. Le Markdown décrit la structure, pas l'apparence. Le style vient du système qui restitue le Markdown (GitHub, votre site de documentation, le thème MkDocs, etc.). Si la fidélité visuelle est cruciale, le PDF est une meilleure cible — voyez notre guide Markdown vers PDF pour des workflows qui préservent le design visuel.
Aller-retour : du Markdown vers Word
Une question naturelle après une migration : « Et si je dois renvoyer un document Markdown à une partie prenante qui n'ouvre que Word ? » C'est la conversion inverse — et c'est une opération bien plus propre, parce que les limitations du Markdown signifient qu'il y a moins de choses à traduire. Le guide Markdown vers Word détaille ce flux.
Pour les équipes qui font des allers-retours fréquents entre les deux formats, le workflow que j'ai vu fonctionner est le suivant : le Markdown est la source de vérité dans Git, les exports Word se font à la demande quand quelqu'un doit relire ou annoter. Rien n'est jamais modifié dans Word puis remis dans Git — c'est comme ça que la migration évite de se déliter lentement.
Pour conclure
La conversion Word vers Markdown est une migration, pas une pression de bouton. Les outils font le gros du travail — notre convertisseur en ligne pour les fichiers ponctuels, Pandoc pour les lots, Mammoth.js pour les pipelines — mais le vrai travail, c'est l'inspection avant conversion et le nettoyage après.
Les deux habitudes qui font gagner le plus de temps :
- Triez d'abord. Comprenez ce qu'il y a dans votre archive source avant de commencer à convertir. Quinze minutes d'échantillonnage évitent des heures à réagir aux surprises.
- Anticipez le nettoyage. Budgétez cinq minutes par document pour la passe de relecture et polissage. Le considérer comme une étape incontournable vous aide à rester honnête sur la durée réelle de la migration.
Si vous débutez en Markdown et vous demandez à quoi ressemblera la sortie, commencez par qu'est-ce que Markdown et le guide de la syntaxe de base. Pour les fonctionnalités avancées — tableaux, notes de bas de page, listes de tâches — la référence de la syntaxe étendue couvre ce que GFM prend en charge.
Et si votre migration part d'Obsidian plutôt que de Word, le guide d'export Obsidian traite ce flux de bout en bout.