De Word a Markdown: guía completa de migración 2026
Convierte documentos Word a Markdown limpio para flujos Git y Obsidian. Métodos reales probados en DOCX, con soluciones para tablas, listas e imágenes.

La petición suele llegar sonando muy sencilla: "¿Puedes pasar estos documentos de Word a nuestra wiki del equipo?"
Abres la unidad compartida. Trescientos archivos .docx. Una década de documentación interna — políticas, runbooks, notas de reuniones, especificaciones — repartidos en carpetas con nombres inconsistentes. Nada hace diff limpio. Nada se busca bien. Y alguien ha decidido que todo tiene que vivir como Markdown versionado en Git antes de fin de trimestre.
He pasado por esta migración dos veces. Una para un archivo de compliance (unos 200 archivos) y otra para una base de conocimiento de ingeniería (unos 500 archivos). En ambas ocasiones la lección fue la misma: convertir Word a Markdown no es una operación de un solo clic. Es un pipeline — conversión, inspección, limpieza — y el paso de limpieza es donde realmente se va el tiempo.
Esta guía cubre lo que funciona en la práctica: los tres métodos de conversión que vale la pena conocer, qué características de Word sobreviven al viaje (y cuáles desaparecen en silencio) y la checklist post-conversión que te ahorra horas de trabajo manual.
¿Por qué mover los documentos de Word a Markdown?
Antes del cómo, un rápido por qué. Porque si tu equipo no ha articulado la razón, la migración no va a cuajar.
- Historial con diff legible. El
.docxde Word es un paquete XML comprimido. Dos versiones le parecen a Git dos blobs binarios aleatorios. Markdown es texto plano — cada cambio es un diff legible. - Búsqueda y grep.
rg "incident response" docs/corre en milisegundos sobre miles de archivos Markdown. El equivalente sobre documentos Word requiere una herramienta de búsqueda propietaria. - Automatización. El Markdown lo consumen generadores de sitios estáticos, herramientas de documentación (Docusaurus, MkDocs, Nextra), pipelines de ingesta para LLM, sistemas CI y linters. Word básicamente solo lo consume Word.
- Longevidad. Los archivos de texto plano sobreviven a los proveedores de software. DOCX es hoy un formato estable, pero el horizonte de compatibilidad para
.doc(el viejo binario) ya es borroso.
Si nada de esto aplica a tu equipo, probablemente no necesitas migrar. Si al menos una cosa sí aplica, estás en el sitio correcto.
Qué sobrevive a la conversión y qué no
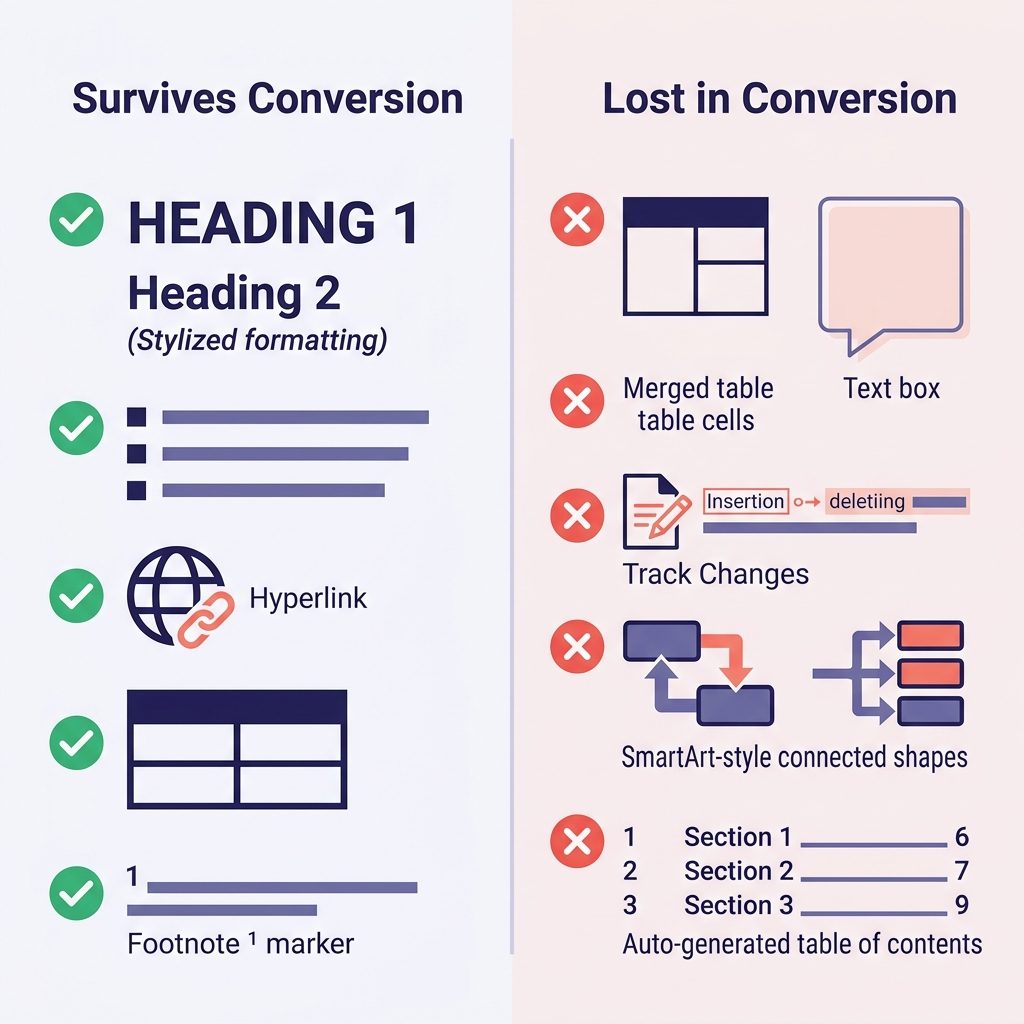
Ajustar las expectativas de entrada es lo que más tiempo ahorra. Esto es lo que he observado en cientos de conversiones:
| Característica de Word (Word Feature) | ¿Sobrevive? | Notas |
|---|---|---|
| Encabezados (estilos Heading 1–6) | Sí | Mapean directamente a # hasta ###### |
| Negrita, cursiva, subrayado | Negrita/cursiva sí | El subrayado no tiene equivalente en Markdown (acaba como cursiva o HTML <u>) |
| Listas con viñetas y numeradas | Generalmente sí | Los niveles muy profundos a veces se aplanan |
| Hipervínculos | Sí | Se conservan la URL y el texto del enlace |
| Tablas | Solo las simples | Celdas combinadas, colores de celda y bordes se pierden |
| Imágenes en línea | Sí | Se extraen a una carpeta y se reescriben los enlaces |
| Notas al pie (Footnotes) | Sí (GFM) | Se convierten a la sintaxis [^1] |
Código (si está con el estilo de párrafo Code) | Depende | Muchas veces se aplana a texto plano sin fence |
| Ecuaciones matemáticas | Parcial | A veces se convierte a LaTeX, a veces se aplana |
| Track Changes (cambios registrados) | No | Acepta o rechaza todos los cambios primero |
| Comentarios (Comments) | No | Resuélvelos o expórtalos aparte antes de convertir |
| Cuadros de texto, SmartArt, formas | No | Se pierden por completo — sustitúyelos por imágenes o texto plano antes |
| Tabla de contenidos autogenerada | No | Regénerala con tu herramienta de documentación |
| Campos de Word (fecha, referencias cruzadas) | No | Conviértelos a texto plano antes de exportar |
Las dos sorpresas más habituales de una migración son (1) formato que parece un encabezado pero en realidad es negrita manual + tamaño de letra mayor — esos acaban como texto en negrita plano y tu salida se queda sin estructura — y (2) tablas con celdas combinadas, que colapsan de formas feas y exigen reconstrucción manual.
Antes de empezar una conversión en lote, revisa diez documentos fuente al azar y marca estos problemas. Son treinta minutos que evitan mucho retrabajo.
Método 1: convertidor online
Es lo que recomiendo para archivos sueltos y lotes pequeños (menos de unos 50 documentos). Es el camino más rápido de .docx a Markdown limpio sin tener que instalar nada.
- Abre nuestro convertidor de Word a Markdown
- Arrastra el archivo
.docxal área de subida - Previsualiza el Markdown convertido
- Descarga el archivo
.md(las imágenes vienen empaquetadas aparte cuando las hay)
La salida usa GitHub Flavored Markdown (GFM), así que se conservan tablas, listas de tareas y notas al pie. Los encabezados mapean a los niveles #, las listas mantienen su jerarquía y los hipervínculos preservan el texto del enlace.
Vale la pena señalar: para documentos estándar toda la conversión ocurre en el navegador. Para archivos muy grandes o cuando estás manejando material sensible, que el archivo no salga a servidores externos es una ventaja real, no solo marketing.
Las limitaciones de cualquier convertidor online (el nuestro o el de otros) son las mismas: el procesamiento por lotes no es lo ideal y no puedes scriptearlo como parte de un pipeline. Para esos casos, salta al Método 2.
Método 2: Pandoc (para lotes y scripts)
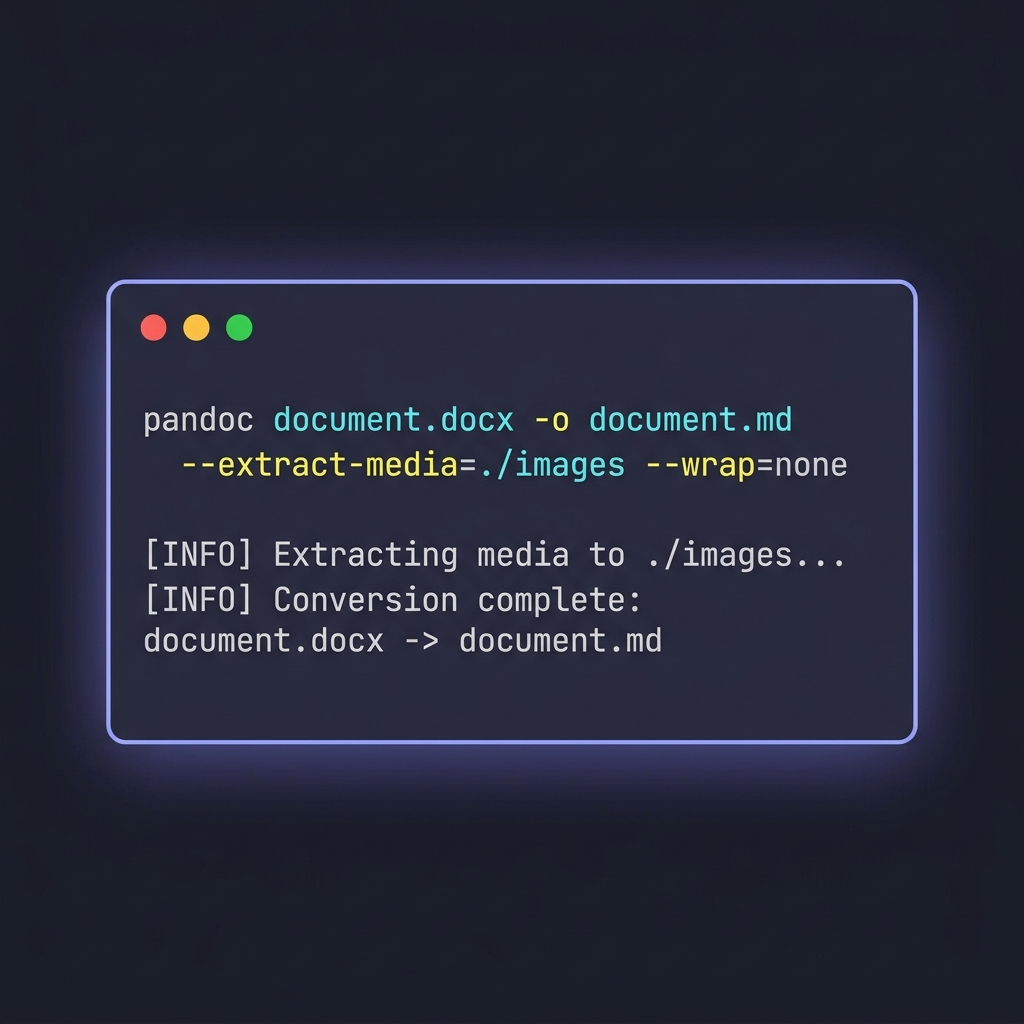
Pandoc es el conversor de documentos universal. Es la herramienta que uso para cualquier cosa que implique más de un puñado de archivos, o cuando necesito ajustar fino la salida.
El comando básico
pandoc document.docx -o document.md
Eso es todo para un archivo suelto. Corre rápido, produce salida legible y gestiona la mayoría de las características de Word de serie. Pero el verdadero valor de Pandoc aparece cuando le añades flags.
Tres flags que vale la pena conocer
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— saca las imágenes incrustadas del DOCX, las deja en una carpeta y reescribe los enlaces de imagen en la salida. Sin este flag, las imágenes en línea se descartan silenciosamente.--wrap=none— impide que Pandoc haga hard-wrap de las líneas a unos 80 caracteres. Esto importa porque los hard wraps rompen la legibilidad de los diffs de Git en documentos con mucho texto corrido.--markdown-headings=atx— fuerza la sintaxis# Headingen lugar del viejo estilo setext (líneas subrayadas con====). ATX es la convención moderna.
Convertir una carpeta en lote
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
Suelta esto en un shell script y puedes procesar cientos de archivos en minutos. Para archivos más grandes, añade un trap y logging para poder retomar si algo se cae a mitad de camino.
Tropiezos del mundo real a vigilar
- Los marcadores de viñeta varían. Pandoc unas veces usa
-, otras*. Si te importa la consistencia, pasa unsed -i 's/^\* /- /g'sobre la salida, o configura el formateador de Markdown de tu editor. - Las listas numeradas reinician sin razón aparente. Word suele tener directivas de "continuar numeración" que Pandoc no sabe interpretar. Verás listas que cuentan
1, 2, 1, 2, 3cuando el original parecía continuo. Se arregla con una pasada rápida de revisión. - Tablas con celdas largas se vuelven ilegibles. Pandoc hace lo que puede, pero las tablas GFM no soportan saltos de línea en celdas como lo hace Word. Plantéate convertir manualmente las tablas especialmente complejas a bloques HTML.
Pandoc no tiene GUI, lo cual es a la vez una pega (los compañeros no técnicos no pueden ejecutarlo) y una ventaja (se scriptiza en cualquier pipeline CI/CD).
Método 3: conversión programática con Mammoth.js
Si estás construyendo un pipeline — por ejemplo, un script de migración que saca DOCX de SharePoint, los convierte y los commitea a Git — puede que ni una UI web ni una llamada a Pandoc por subproceso encajen en tu stack. Mammoth.js es una librería JavaScript que convierte DOCX a HTML o Markdown limpio directamente en Node.js.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // the Markdown output
console.log(result.messages); // warnings about unsupported features
});
Lo que hace útil a Mammoth es su postura opinada: ignora por completo el estilo visual de Word y se centra en la estructura semántica (encabezados, listas, tablas). La salida es, por defecto, más limpia que la de Pandoc, a cambio de menos control. Para migrar un archivo heredado donde la mayoría de los documentos tienen estructura consistente, tiraría de Mammoth. Para documentos idiosincrásicos con mucho formato, gana la flexibilidad de Pandoc.
Quienes usan Python tienen una opción parecida en python-docx combinado con un escritor de Markdown, aunque es más una ruta DIY que una herramienta llave en mano.
El paso de limpieza del que nadie te avisa

La conversión te lleva a un archivo .md. No te lleva a un archivo .md que quieras commitear.
Esta es mi checklist estándar post-conversión. Toma unos cinco minutos por documento cuando ya tienes práctica:
- Escanea encabezados estructurales perdidos. Busca en la salida líneas que parecen encabezados pero en realidad son
**Texto en negrita**solos en su línea. Alguien los estilizó a mano en Word en lugar de usar los estilos Heading. Promuévelos a##reales. - Revisa la primera tabla. Si las tablas se ven bien aquí, probablemente se vean bien en todas partes. Si la primera está rota, todas lo están.
- Elimina líneas vacías dentro de elementos de lista. Pandoc a veces mete líneas en blanco que rompen la continuidad de la lista.
- Verifica los enlaces de imágenes. Abre el archivo en una vista previa de Markdown (la incorporada de VS Code sirve) y confirma que las imágenes cargan.
- Busca artefactos sueltos. Residuos habituales:
\al final de las líneas (saltos de línea forzados que Word oculta pero Markdown muestra), atributos de estilo{.underline}, etiquetas<span>que se colaron. - Revisa las primeras y últimas 10 líneas. Las cabeceras, pies y números de página de Word suelen filtrarse a la salida como contenido vacío o como artefactos raros.
Para una migración grande, automatiza los puntos 5 y 6 con un script de limpieza. El resto se beneficia de ojos humanos — al menos hasta que hayas construido suficiente reconocimiento de patrones para confiar en la salida de una clase concreta de documento.
Una migración real: archivo de compliance de 200 archivos
Este es el flujo que usé para la migración del archivo de compliance. De principio a fin, fueron dos días de trabajo sobre un archivo de 200 ficheros.
Mañana del día 1: triaje del origen
Escribí un script en Python que abría cada DOCX, contaba encabezados, imágenes y tablas, y marcaba cualquiera que tuviese Track Changes aún activado o comentarios presentes. La salida fue un CSV con los archivos ordenados por complejidad. El objetivo no era arreglar nada todavía — solo saber a qué me enfrentaba.
Tarde del día 1: conversión por lotes de los archivos fáciles
Unos 140 de los 200 archivos eran directos: sin imágenes, tablas simples, estructura de encabezados limpia. Los pasé por Pandoc en un bucle con --extract-media y --wrap=none. Revisé al azar 20 muestras. Todo correcto.
Mañana del día 2: tratar los archivos complejos uno a uno
Los 60 restantes tenían problemas — celdas de tabla combinadas, objetos de hoja de cálculo incrustados o un historial de Track Changes sustancioso que alguien tenía que revisar primero. Para estos usé el convertidor online caso por caso, a veces ejecutando Pandoc con flags distintos, a veces limpiando antes el DOCX de origen.
Tarde del día 2: limpieza y commit
Ejecuté un script de limpieza sobre los 200 archivos convertidos (quitando artefactos {.underline}, estandarizando marcadores de viñeta, arreglando las salidas con wrap de Pandoc). Revisé diffs, commiteé en lotes de 50 y empujé a la rama de migración.
Si hubiese intentado hacer cualquier parte de esto a mano — abriendo cada documento Word y pegándolo en un editor de Markdown — habrían sido al menos dos semanas de trabajo. Las herramientas de conversión no son opcionales; son lo que hace el proyecto viable.
Problemas comunes y sus soluciones
Las tablas se ven mal en la vista previa de Markdown
El noventa por ciento de las veces, el origen tenía celdas combinadas o contenido muy largo en las celdas. Las tablas GFM no soportan ninguno de los dos casos con elegancia. Tus opciones: reconstruir la tabla manualmente en GFM, usar un bloque HTML <table> dentro del Markdown (soportado por la mayoría de renderizadores) o partir la tabla en varias tablas más simples.
Las imágenes no aparecen
Comprueba si el convertidor las extrajo. Pandoc no lo hace a menos que uses --extract-media. Los convertidores online suelen descargar un zip con el archivo Markdown y una carpeta images/ — asegúrate de que ambos acaben en el sitio correcto y de que las rutas de imagen en el Markdown coincidan.
La salida tiene barras invertidas raras al final de las líneas
Son saltos de línea forzados de Word que Markdown renderiza como breaks obligados. Si el Word original estaba lleno de interlineado apretado que usaba saltos de línea en lugar de saltos de párrafo, Pandoc los preserva. Un buscar-y-reemplazar rápido de \\$ (fin de línea) suele limpiarlos.
Los niveles de encabezado quedan mal tras la conversión
Los documentos Word suelen empezar en Heading 2 o Heading 3 (porque Heading 1 estaba reservado para la portada). La convención en Markdown es empezar desde # (H1). Dependiendo de cómo muestre tu sistema de docs los encabezados, puede que tengas que subir todos los niveles en uno. Con sed funciona: sed -i 's/^## /# /; s/^### /## /; ...' file.md.
El Markdown no se parece visualmente al documento Word
Esto es lo esperado. Markdown describe estructura, no apariencia. El estilo lo pone el sistema que renderice el Markdown (GitHub, tu sitio de documentación, el tema de MkDocs, etc.). Si la fidelidad visual es crítica, PDF es un mejor destino — mira nuestra guía de Markdown a PDF para flujos que preservan el diseño visual.
Ida y vuelta: de Markdown a Word
Una pregunta natural tras migrar: "¿Y si necesito mandarle un documento en Markdown a alguien que solo abre Word?" Esa es la conversión inversa — y es una operación bastante más limpia, porque las limitaciones de Markdown hacen que haya menos cosas que traducir. La guía de Markdown a Word cubre ese flujo.
Para equipos que saltan mucho entre ambos formatos, el flujo que he visto funcionar es: Markdown es la fuente de verdad en Git, las exportaciones a Word ocurren bajo demanda cuando alguien necesita revisar o anotar. Nada se edita nunca en Word y se vuelve a mergear — así la migración no se deshilacha poco a poco.
Cerrando
Convertir de Word a Markdown es una migración, no un apretón de botón. Las herramientas hacen el trabajo pesado — nuestro convertidor online para archivos sueltos, Pandoc para lotes, Mammoth.js para pipelines — pero el trabajo real está en la inspección previa y en la limpieza posterior.
Los dos patrones que más tiempo ahorran:
- Haz triaje primero. Entiende qué hay en tu archivo de origen antes de empezar a convertir. Quince minutos de muestreo evitan horas de reaccionar a sorpresas.
- Cuenta con la limpieza. Presupuesta cinco minutos por documento para la pasada de revisión y pulido. Tratarlo como un paso inevitable te mantiene honesto sobre cuánto va a durar la migración.
Si eres nuevo en Markdown y te preguntas cómo se verá la salida, empieza con qué es Markdown y la guía de sintaxis básica. Para las funcionalidades avanzadas — tablas, notas al pie, listas de tareas — la referencia de sintaxis extendida cubre lo que soporta GFM.
Y si tu migración sale de Obsidian en lugar de Word, la guía de exportación de Obsidian cubre ese flujo de extremo a extremo.