Cómo convertir PDF a Markdown en 2026 (gratis y listo para RAG)
Convierte PDF a Markdown como se debe en 2026. Compara herramientas online gratuitas, Pandoc y extractores con IA — con flujos listos para RAG y arreglos de OCR.

Si alguna vez copiaste y pegaste un párrafo de un PDF y lo viste explotar en un revoltijo de saltos de línea, guiones rotos y formato perdido, ya sabes por qué convertir PDF a Markdown se volvió un problema serio de flujo de trabajo en 2026.
El PDF es la moneda universal para compartir documentos. También es un pésimo formato de origen. En cuanto quieres meter ese contenido en un pipeline RAG, llevarlo a un sitio de documentación o simplemente guardarlo en tu app de notas, necesitas texto estructurado — encabezados como encabezados, tablas como tablas, código como código.
Esta guía recorre tres formas honestas de convertir PDF a Markdown: un conversor online sin instalación, Pandoc en la línea de comandos y la nueva ola de extractores con IA como marker y Docling. Te muestro cuál elegir para cada tarea, cómo arreglar lo que rompen (tablas, matemáticas, páginas escaneadas) y cómo enviar la salida a un pipeline LLM sin tener que limpiarla dos veces.
¿Por qué convertir PDF a Markdown?
El mismo problema de conversión aparece en tres comunidades distintas. Cada una tiene un motivo algo diferente para preocuparse, pero el formato destino es el mismo.
Alimentar pipelines RAG y LLM con texto limpio
A los pipelines de generación aumentada por recuperación no les sienta bien el texto PDF en bruto. Artefactos de salto de página, diseños de dos columnas aplastados en una sola, encabezados y pies repitiéndose en cada página — todo eso se vuelve ruido en la base de datos vectorial y contamina la recuperación.
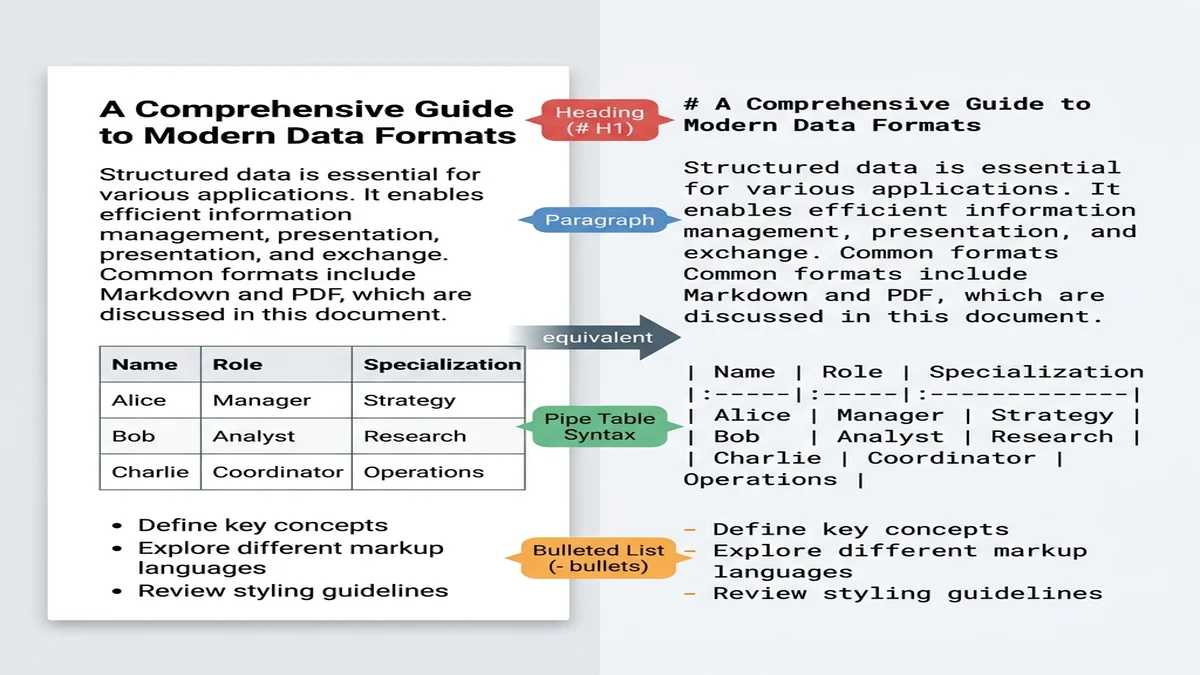
Markdown está más cerca del "texto plano estructurado" que cualquier otro formato práctico. Los modelos grandes entrenados con datos web han visto miles de millones de documentos Markdown (archivos README, respuestas de Stack Overflow, posts de blog), así que reconocen los encabezados # como límites de sección y las pipes | como separadores de tabla sin necesidad de prompts.
Migrar PDFs heredados a sistemas de documentación modernos
Docusaurus, MkDocs, Astro Starlight y Hugo todos quieren Markdown. Si tu equipo tiene 200 PDFs de documentación interna heredada, no quieres un ejército copia-pega — quieres un conversor que preserve la jerarquía de encabezados para que la navegación se construya sola.
Construir un segundo cerebro buscable
Obsidian, Logseq, Foam, Roam — toda app de notas moderna habla Markdown. Académicos digitalizando archivos en papel, profesionales del conocimiento archivando informes de reuniones e investigadores armando bibliotecas de literatura necesitan lo mismo: un archivo Markdown limpio con los encabezados intactos, para poder hacer grep entre cientos de documentos más tarde.
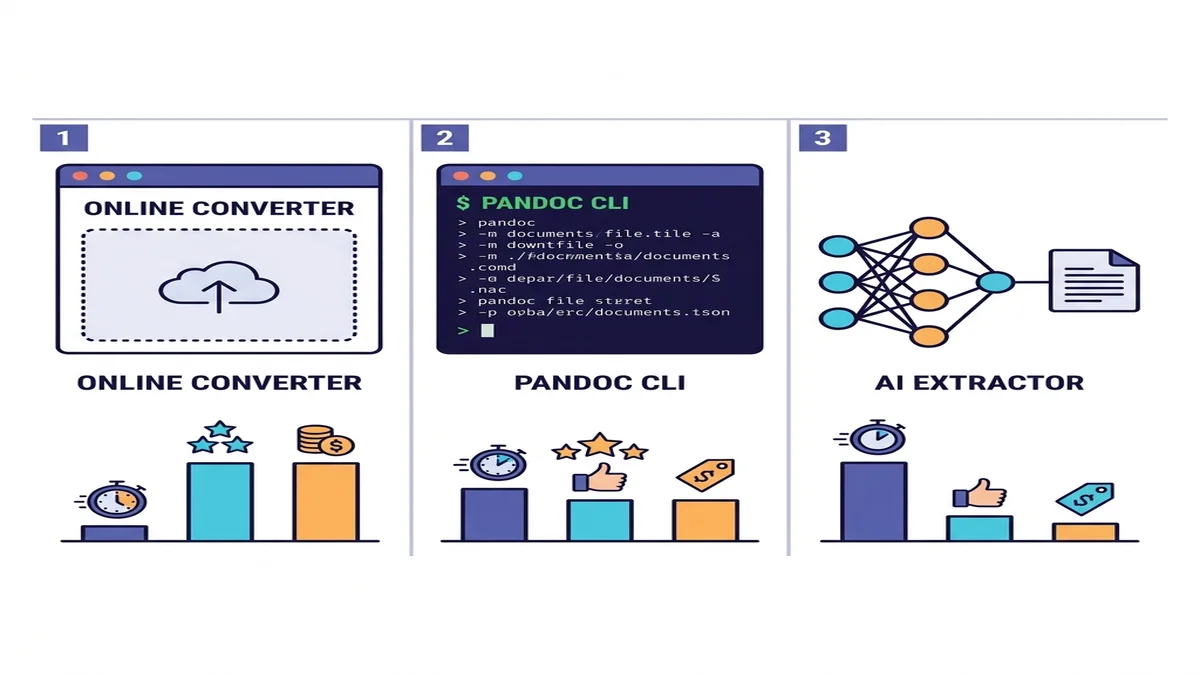
Los tres enfoques (cuándo usar cada uno)
Hay decenas de herramientas, pero realmente solo tres categorías. Elige la fila que coincide con tu situación.
| Método | Velocidad | PDFs simples | PDFs complejos | OCR para escaneos | Setup |
|---|---|---|---|---|---|
| Conversor online | Rápido | Excelente | Bueno | Incorporado o automático | Ninguno |
| Pandoc + pdftotext | Rápido | Bueno | Mediocre en tablas | No | Instalación CLI |
| Extractor con IA (marker / Docling) | Lento | Excelente | Excelente | Sí | Python + dependencias ML |
Si no estás seguro de cuál elegir, empieza por un conversor online. Cuesta un minuto probarlo y, para la mayoría de tareas puntuales o de lotes pequeños, ahí termina la historia. Para pipelines programáticos o contenido académico denso, baja una fila. Comparamos el panorama más amplio en nuestra ronda de conversores Markdown gratuitos.
Método 1: Convertir PDF a Markdown online (gratis, sin instalar)
El camino más rápido es también el que más gente se salta porque parece demasiado simple. Para una mayoría aplastante del trabajo diario — notas de reunión, artículos, informes de un solo capítulo — un conversor en el navegador sobra.
Puedes soltar tu archivo directamente en nuestro conversor gratuito PDF a Markdown y saltarte el resto de esta sección.
Flujo paso a paso
- Arrastra y suelta el PDF en la zona de subida (o haz clic para elegir un archivo).
- Espera unos segundos a que el parser termine. Cualquier cosa por debajo de 20 páginas suele convertirse antes de que leas esta frase dos veces.
- Previsualiza el Markdown renderizado junto al código fuente a la derecha.
- Copia la fuente o descarga un archivo
.md.
Eso es todo. Sin cuentas, sin muro de email, sin marcas de agua en la salida.
Cuándo funciona mejor
- Conversiones puntuales en las que no quieres instalar nada.
- Verificaciones rápidas antes de decidir invertir en un pipeline programático.
- Archivos sensibles a la privacidad donde prefieres no mandar el documento a una API de terceros. Nuestro conversor procesa los archivos en memoria y los purga inmediatamente — sin almacenamiento persistente.
Limitaciones
Los conversores online en general (no solo el nuestro) tienen dos modos de fallo que conviene conocer.
El primero son PDFs muy grandes o atípicos. Una divulgación legal escaneada de 600 páginas con fuentes embebidas y campos de formulario dinámicos no es un escenario de "arrastra y descarga" para ninguna herramienta. Si tienes uno de esos, salta a la sección de extractor con IA.
El segundo son PDFs escaneados sin capa de texto. No hay texto que extraer — la página es solo una imagen. Necesitas OCR primero; ver Manejar contenido difícil más abajo.
Método 2: Pandoc en la línea de comandos
Pandoc es la navaja suiza de la conversión de documentos. Es la herramienta correcta cuando necesitas un pipeline reproducible y scriptable, y no quieres depender de un servicio web.
La trampa honesta: Pandoc en sí no tiene un lector de PDF potente. El flujo de la comunidad pasa por pdftotext (de las utilidades de Poppler) y canaliza el resultado a Pandoc.
# Extraer texto preservando la maquetación, luego convertir a GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
Para un PDF simple cargado de texto — un memo, un artículo de una sola columna — esta combinación funciona bien y corre en milisegundos.
Cuando la fidelidad importa
Si tu PDF es mayormente prosa, este pipeline te da un archivo Markdown limpio con la estructura de párrafos intacta. Añade los flags -V y --wrap=none para ajustar la salida a herramientas downstream a las que no les gustan las líneas con saltos duros.
Dónde Pandoc sufre
- Diseños multicolumna (artículos académicos, revistas):
pdftotextintercala las columnas y obtienes salida ilegible. - Tablas: cualquier cosa más allá de la cuadrícula más simple de dos columnas suele llegar como columnas separadas por espacios en lugar de pipes Markdown.
- Matemáticas y bloques de código: no hay preservación semántica; las ecuaciones LaTeX se vuelven texto y el monoespaciado del código se vuelve párrafo normal.
- PDFs escaneados: soporte cero — Pandoc/pdftotext no pueden extraer texto de imágenes.
Para tablas en concreto, nuestra guía de sintaxis Markdown extendida cubre el formato de tablas GFM con el que querrás que coincida la salida.
Método 3: Extracción con IA (marker, Docling, pymupdf4llm)
La ola 2024-2025 de extractores conscientes de la maquetación cambió lo que es posible. Estas herramientas combinan detección visual de layout con OCR y generación de salida estructurada, así que entienden que esta región es una tabla y aquella región es un cuerpo de texto a dos columnas. La salida es drásticamente más limpia en PDFs complejos.
Tres proyectos que vale la pena conocer:
- marker — usa surya (un modelo de layout) más heurísticas. Fuerte en artículos académicos, matemáticas y bloques de código. Licencia Apache 2.0.
- Docling — de IBM Research. Excelente reconstrucción de tablas, se enchufa nativamente con LlamaIndex y LangChain. Licencia MIT.
- pymupdf4llm — wrapper ligero alrededor de PyMuPDF. Más rápido que los otros dos, menos dependencias ML, diseñado específicamente para ingesta a LLM.
Un ejemplo mínimo en Python
Aquí va el pipeline Docling útil más pequeño:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
O con pymupdf4llm para la ruta más ligera:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
Compromisos
Estas herramientas son más lentas que el pipeline Pandoc. En un portátil CPU típico, espera que un paper de 30 páginas tarde decenas de segundos en vez de milisegundos; con GPU, eso vuelve a bajar a unos pocos segundos para marker. pymupdf4llm es el más rápido de los tres porque salta los modelos de visión pesados.
El otro compromiso es el peso de las dependencias. Un pip install marker-pdf arrastra PyTorch y unos cientos de megas de pesos de modelo. Si vas a desplegar esto en un contenedor, planifica el tamaño.
Manejar contenido difícil
Las diferencias entre métodos se vuelven obvias cuando dejas de probar con memos limpios de dos páginas y empiezas a meterles PDFs del mundo real.
Tablas que no sobreviven
Las tablas son donde fallan la mayoría de los conversores. La ruta pdftotext + Pandoc casi siempre produce una sopa de columnas alineadas con espacios que ningún renderer Markdown va a parsear correctamente. Los conversores online y los extractores con IA lo hacen mucho mejor aquí porque detectan la región de tabla primero y luego reconstruyen las celdas.
El truco: revisa tu primera salida de tabla antes de fiarte del resto. Si la primera tabla está destrozada, las otras 50 también lo estarán.
Ecuaciones matemáticas y bloques LaTeX
Si tu PDF tiene ecuaciones, necesitas una herramienta que detecte las regiones matemáticas y emita bloques LaTeX ($$...$$) en el Markdown. marker hace esto; Pandoc no. Para escritura científica, esta es la única razón más grande para pagar el coste de velocidad del extractor con IA.
Bloques de código y código en línea
Muchos PDFs renderizan código con una fuente monoespaciada pero pierden la etiqueta semántica de "esto es código" en la exportación. Los extractores con IA vuelven a detectar las regiones de código por estilo visual — la fuente monoespaciada y la indentación — y las reenvuelven en cercos de triple acento grave. Los pipelines basados en Pandoc suelen aplastar el código en párrafos normales.
Notas al pie y citas
Los artículos académicos usan notas al pie numeradas con el cuerpo de la nota al pie de página. La ruta pdftotext pierde el vínculo entre el marcador de referencia y el cuerpo de la nota. Docling y marker los preservan como sintaxis Markdown adecuada de notas al pie (referencia [^1] + definición [^1]: cuerpo).
PDFs escaneados (OCR obligatorio)
Un PDF escaneado es una imagen de una página, no texto. No hay nada que extraer hasta que corras OCR primero.

Tres rutas fiables:
-
ocrmypdf — añade una capa OCR de texto invisible a un PDF escaneado sin cambiar su apariencia visual. Una vez añadida la capa, cualquier conversor downstream funciona:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
Extractores con IA con modo OCR — marker y Docling pueden detectar cuándo una página no tiene capa de texto y correr OCR automáticamente. La salida está integrada, así que obtienes un archivo Markdown en vez de un PDF intermedio.
-
Conversores online con OCR automático — algunas herramientas de navegador (la nuestra incluida para PDFs solo de imagen) corren OCR de forma transparente. Cómodo, pero vigila el soporte de idiomas si tu documento no está en inglés.
Una sutileza traicionera: los PDFs "born-digital" (creados desde un documento Word, no escaneados) pueden seguir sin tener capa de texto si se exportaron como imágenes aplanadas. Comprueba siempre si puedes seleccionar texto dentro del visor de PDF primero. Si puedes, salta el OCR. Si no, córrelo.
Preparar el Markdown para ingesta RAG / LLM
Si el destino es una base de datos vectorial, unas pocas decisiones pequeñas durante la conversión hacen que la calidad de recuperación mejore notablemente aguas abajo.
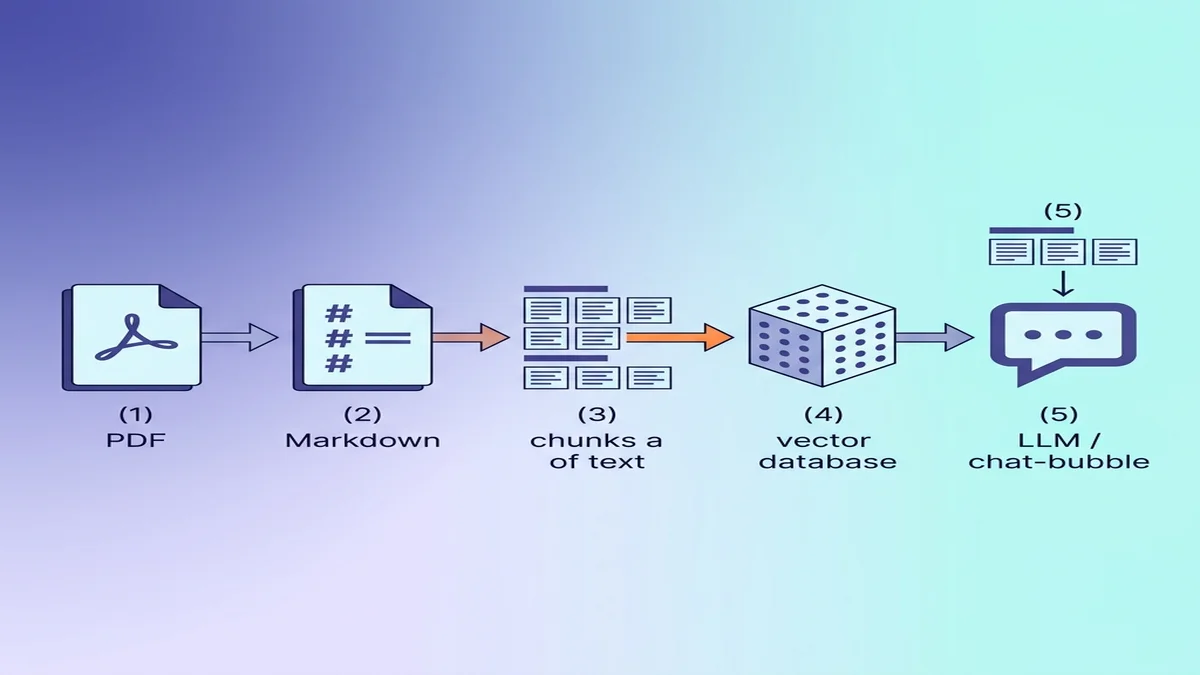
Por qué Markdown le gana al texto plano para LLMs
Markdown lleva estructura que el texto plano pierde. Un modelo que lee ## Métodos sabe que ha entrado en una sección nueva; un modelo que lee el mismo texto con todo el formato eliminado solo ve párrafos de peso igual. Si eres nuevo en la sintaxis, nuestra guía básica de Markdown es una lectura de 5 minutos.
Chunking por jerarquía de encabezados
El error más común de RAG es el chunking de tamaño fijo — partir el documento en bloques de 500 tokens sin importar la estructura. Markdown te deja chunkear semánticamente — corta en las fronteras ## H2 y obtienes secciones coherentes en vez de fragmentos a media frase.
# Chunk grueso: cortar en H2
sections = markdown.split("\n## ")
# Cada sección ahora empieza en un encabezado de sección y contiene su sub-árbol
Mejor: recorre los encabezados como un árbol, adjuntando cada H3 a su H2 padre en los metadatos del chunk.
Preservar metadatos en frontmatter
Añade frontmatter YAML al inicio de cada archivo convertido para que la información de origen viaje con cada chunk:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
Cuando el LLM recupera un chunk, este metadato se convierte en el pie de cita. También es como acabas respondiendo la pregunta "¿de dónde salió esta afirmación?" sin volver a ejecutar la recuperación. Si estás construyendo este tipo de pipeline a partir de exports de chat, la misma idea aplica a transcripciones de ChatGPT/Claude.
Errores comunes y cómo evitarlos
Hay un puñado de cosas que muerden a quienes hacen esto por primera vez.
- Saltarse la normalización de encoding. Los PDFs adoran los trucos Unicode: ligaduras (
fi,fl), comillas tipográficas ("vs"), guiones em que parecen guiones cortos. Pasa la salida por una normalización Unicode (NFKC en Python) antes de meterla en cualquier sitio. - Dejar dentro encabezados y pies de página. El pie
Página 4 de 12de cada página se convierte en ruido en tu recuperación. Elimina las líneas repetidas que aparecen a intervalos regulares. - Confiar en la primera tabla que ves. Revisa al menos las dos primeras tablas antes de asumir que el resto está bien.
- Asumir que "born-digital" significa "tiene capa de texto". Algunos PDFs se exportan como imágenes aplanadas aunque empezaron como documentos Word. Intenta siempre seleccionar texto primero.
- Sobre-chunkear documentos pequeños. Para un memo de 3 páginas, mete el Markdown entero al modelo y salta el paso RAG por completo. La recuperación es excesiva cuando la ventana de contexto > documento.
Preguntas frecuentes
¿Cuál es el mejor conversor gratuito de PDF a Markdown?
Para la mayoría de usuarios, un conversor online es el camino más rápido — arrastras, sueltas, listo. Para trabajo en lote o programático, pymupdf4llm (Python) y Pandoc (CLI) cubren los casos simples. Para artículos académicos con tablas y matemáticas, marker y Docling producen salida notablemente mejor. La "mejor" elección depende de si optimizas por tiempo de setup o por fidelidad de salida.
¿Pueden ChatGPT o Claude convertir PDF a Markdown?
Pueden, con matices. Ambos pueden leer un PDF directamente y producir salida Markdown, pero en documentos largos puedes pegarte con los límites de contexto, y la precisión en tablas y matemáticas varía entre ejecuciones. Para conversiones deterministas en lote, un conversor dedicado es más fiable. Ver exportar ChatGPT a Word/PDF/HTML para el flujo de ida y vuelta relacionado.
¿Cómo convierto un PDF escaneado a Markdown?
Corre OCR primero. La ruta más limpia es ocrmypdf para añadir una capa de texto y luego cualquier conversor funciona sobre el PDF con OCR. Alternativamente, marker y Docling tienen OCR incorporado y producen Markdown directamente desde PDFs solo de imagen.
¿La conversión PDF a Markdown online es privada?
Con nuestro conversor, los archivos se procesan en memoria y se purgan tras la conversión — sin cuenta, sin almacenamiento persistente. Otros servicios varían; revisa la política de privacidad de cualquier herramienta que uses, especialmente para documentos confidenciales.
¿Cómo mantengo las tablas intactas al convertir PDF a Markdown?
Salta el pipeline pdftotext + Pandoc para PDFs con muchas tablas — casi siempre las destroza. Usa un conversor online que emita tablas GFM, o un extractor con IA como marker o Docling. Revisa las primeras tablas de cualquier forma.
¿Debo conservar el PDF original o solo el Markdown?
Conserva ambos. El Markdown sirve para ingesta, búsqueda y edición. El PDF es tu fuente de verdad para cita y auditoría. Referencia el nombre del archivo PDF y el rango de páginas en el frontmatter del Markdown para poder rastrear siempre una afirmación de vuelta a su origen.
¿Listo para convertir tu primer PDF?
Si solo quieres el resultado, nuestro conversor gratuito de PDF a Markdown maneja los casos cotidianos sin registro. Para el siguiente paso — convertir ese Markdown en un documento Word pulido o un PDF listo para compartir — mira nuestra guía de Markdown a Word.
Referencias
- Pandoc User's Guide — la referencia canónica de conversión por CLI.
- GitHub Flavored Markdown Spec — el dialecto al que apunta esta guía para la salida.
- Docling (IBM Research) — extractor PDF open-source consciente de la maquetación.
- marker — conversor PDF-a-Markdown open-source con manejo fuerte de artículos académicos.
- pymupdf4llm — wrapper ligero de extracción Markdown alrededor de PyMuPDF.
- OCRmyPDF — añade una capa de texto buscable a PDFs escaneados.