Word para Markdown: Guia Completo de Migração em 2026
Converta documentos Word em Markdown limpo para fluxos Git e Obsidian. Métodos reais testados em arquivos DOCX, com correções para tabelas, listas e imagens.

O pedido costuma chegar com um ar enganosamente simples: "Dá pra mover esses documentos Word pro wiki da equipe?"
Você abre a pasta compartilhada. Trezentos arquivos .docx. Uma década de documentação interna — políticas, runbooks, atas de reunião, especificações — espalhada em pastas com nomes inconsistentes. Nada disso gera diff decente. Nada disso é pesquisável direito. E alguém decidiu que tudo precisa morar em Markdown versionado no Git até o fim do trimestre.
Já passei por essa migração duas vezes. Uma para um arquivo de compliance (~200 arquivos), outra para uma base de conhecimento de engenharia (~500 arquivos). Nas duas vezes a lição foi a mesma: converter Word para Markdown não é uma operação de um clique. É um pipeline — conversão, inspeção, limpeza — e é na etapa de limpeza que o tempo realmente some.
Este guia cobre o que funciona na prática: os três métodos de conversão que vale conhecer, quais recursos do Word sobrevivem à viagem (e quais somem em silêncio) e o checklist pós-conversão que evita horas de correção manual.
Por que mover documentos Word para Markdown, afinal?
Antes do como, um rápido porquê. Porque se a equipe não tem clareza sobre o motivo, a migração não pega.
- Histórico com diff legível. O
.docxdo Word é um pacote XML zipado. Para o Git, duas versões parecem dois blobs binários aleatórios. Markdown é texto puro — cada mudança vira um diff legível. - Busca e grep.
rg "resposta a incidentes" docs/roda em milissegundos em milhares de arquivos Markdown. O equivalente para documentos Word exige uma ferramenta de busca proprietária. - Automação. Markdown é consumível por geradores de sites estáticos, ferramentas de documentação (Docusaurus, MkDocs, Nextra), pipelines de ingestão de LLM, sistemas de CI e linters. Word é consumível, basicamente, pelo Word.
- Longevidade. Arquivos de texto puro sobrevivem a fornecedores de software. DOCX é um formato estável hoje, mas o horizonte de compatibilidade do
.doc(o antigo formato binário) já está nebuloso.
Se nada disso se aplica ao seu time, provavelmente você não precisa migrar. Se pelo menos um se aplica, você está no lugar certo.
O que sobrevive à conversão, e o que não
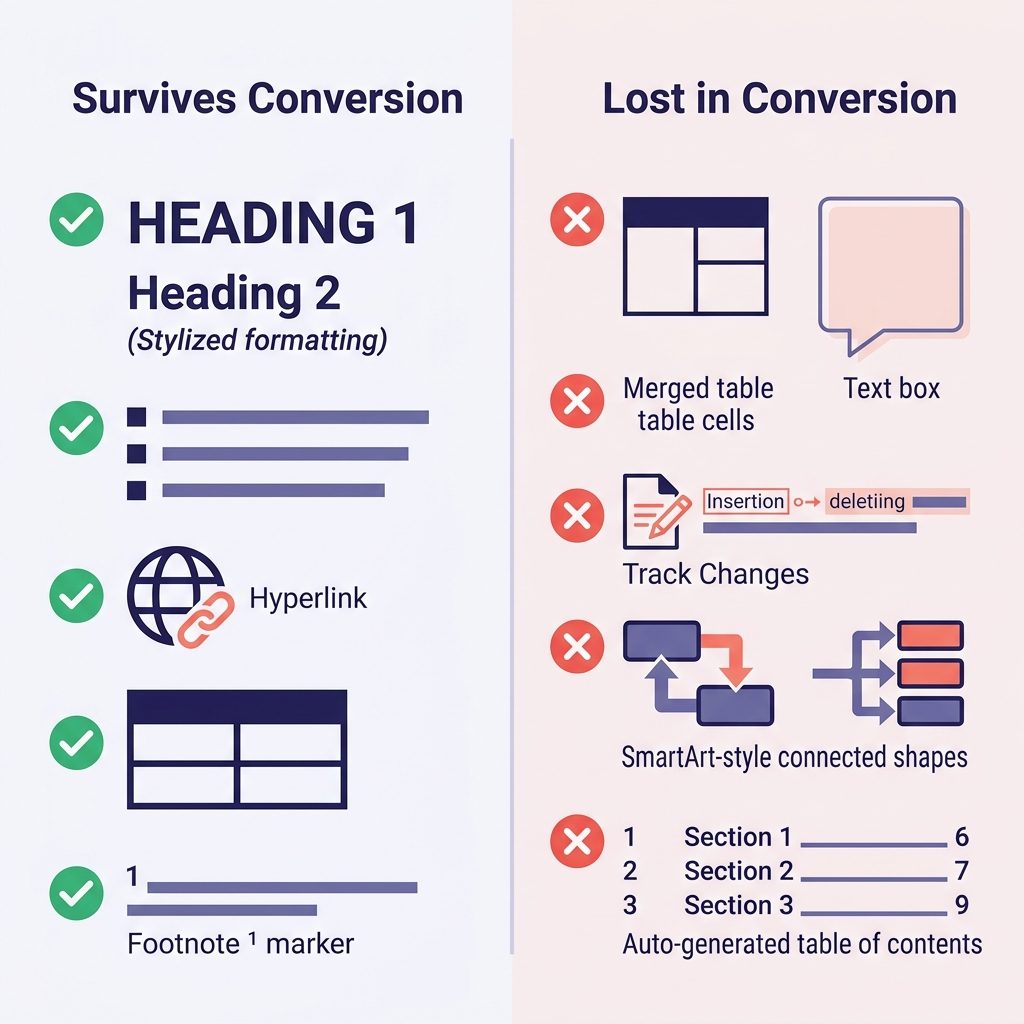
Ajustar expectativas logo no começo é o que mais economiza tempo. Aqui está o que observei ao longo de centenas de conversões:
| Recurso do Word (Word Feature) | Sobrevive? | Observações |
|---|---|---|
| Títulos (estilos Heading 1–6) | Sim | Mapeiam direto para # até ###### |
| Negrito, itálico, sublinhado | Negrito/itálico sim | Sublinhado não tem equivalente em Markdown (vira itálico ou HTML <u>) |
| Listas com marcadores e numeradas | Geralmente sim | Aninhamentos profundos às vezes achatam |
| Hyperlinks | Sim | URL e texto do link preservados |
| Tabelas | Tabelas simples sim | Células mescladas, cores e bordas se perdem |
| Imagens inline | Sim | Extraídas para uma pasta; links reescritos |
| Notas de rodapé (footnotes) | Sim (GFM) | Convertem para a sintaxe [^1] |
Código (se estilizado como parágrafo Code) | Depende | Costuma virar texto puro sem cerca de código |
| Equações matemáticas | Parcial | Pode converter para LaTeX; às vezes achata |
| Controle de Alterações (Track Changes) | Não | Aceite ou rejeite todas as alterações antes |
| Comentários | Não | Resolva ou exporte separadamente antes de converter |
| Caixas de texto, SmartArt, formas | Não | Perdidas por completo — substitua por imagens ou texto primeiro |
| Sumário gerado automaticamente | Não | Regenere na ferramenta de documentação |
| Campos do Word (data, referências cruzadas) | Não | Converta para texto puro antes de exportar |
As surpresas mais comuns em migração costumam ser (1) formatação que parece um título mas era só negrito manual + fonte maior — isso vira texto em negrito sem estrutura semântica — e (2) tabelas com células mescladas, que desmoronam de um jeito feio e exigem reconstrução manual.
Antes de começar uma conversão em lote, olhe dez documentos-fonte aleatórios e marque esses problemas. Leva trinta minutos e previne um bocado de retrabalho.
Método 1: Conversor Online
É o que eu recomendo para arquivos únicos e lotes pequenos (abaixo de ~50 documentos). É o caminho mais rápido de .docx para Markdown limpo, sem configuração.
- Abra nosso conversor de Word para Markdown
- Arraste o arquivo
.docxpara a área de upload - Visualize o Markdown convertido
- Baixe o arquivo
.md(as imagens vêm em um pacote à parte quando existem)
A saída usa GitHub Flavored Markdown (GFM), então tabelas, listas de tarefas e notas de rodapé ficam preservadas. Títulos mapeiam para níveis de #, listas preservam a hierarquia e hyperlinks mantêm o texto âncora.
Vale a observação: toda a conversão acontece no navegador para documentos padrão. Para arquivos muito grandes ou quando você lida com material sensível, manter o arquivo fora de servidores externos é uma vantagem concreta, não só texto de marketing.
As limitações de qualquer conversor online (o nosso ou qualquer outro) são as mesmas: processamento em lote não é ideal e não dá para automatizar dentro de um pipeline. Para esses casos, pule para o Método 2.
Método 2: Pandoc (para lotes e scripts)
O Pandoc é o conversor universal de documentos. É a ferramenta que uso para qualquer coisa que envolva mais do que um punhado de arquivos ou quando preciso de ajuste fino na saída.
O comando básico
pandoc document.docx -o document.md
É isso para um arquivo único. Roda rápido, produz saída legível e lida com a maioria dos recursos comuns do Word de cara. Mas o real valor do Pandoc aparece quando você adiciona flags.
Três flags que valem conhecer
pandoc document.docx \
-o document.md \
--extract-media=./images \
--wrap=none \
--markdown-headings=atx
--extract-media=./images— extrai as imagens embutidas no DOCX, coloca-as em uma pasta e reescreve os links de imagem na saída. Sem essa flag, as imagens inline são descartadas em silêncio.--wrap=none— impede que o Pandoc quebre linhas em ~80 caracteres. Isso importa porque quebras rígidas prejudicam a leitura do diff do Git em documentos com muita prosa.--markdown-headings=atx— força a sintaxe# Títuloem vez do estilo antigo setext (linhas sublinhadas com====). ATX é a convenção moderna.
Convertendo uma pasta em lote
for f in *.docx; do
pandoc "$f" -o "${f%.docx}.md" --extract-media=./images --wrap=none
done
Jogue isso num shell script e você processa centenas de arquivos em minutos. Para arquivos maiores, adicione um trap e logging para conseguir retomar se algo quebrar no meio.
Percalços do mundo real pra ficar de olho
- Marcadores de lista variam. O Pandoc às vezes usa
-, às vezes*. Se você se importa com consistência, rodesed -i 's/^\* /- /g'sobre a saída, ou configure o formatador de Markdown do seu editor. - Listas numeradas reiniciam do nada. O Word tem diretivas de "continuar numeração" que o Pandoc não consegue interpretar. Você vai ver listas contando
1, 2, 1, 2, 3quando a fonte parecia contínua. Dá pra arrumar com uma revisão rápida. - Tabelas com células longas viram uma bagunça. O Pandoc faz o que pode, mas tabelas GFM não suportam quebras de linha dentro das células do jeito que o Word suporta. Para tabelas especialmente complexas, considere converter manualmente em blocos HTML.
O Pandoc não tem GUI, o que é ao mesmo tempo uma desvantagem (colegas não técnicos não conseguem rodar) e uma vantagem (ele se encaixa em qualquer pipeline de CI/CD).
Método 3: Conversão programática com Mammoth.js
Se você está montando um pipeline — digamos, um script de migração que puxa DOCX do SharePoint, converte e faz commit no Git — nem uma interface web nem uma chamada subprocess ao Pandoc podem caber na sua stack. O Mammoth.js é uma biblioteca JavaScript que converte DOCX para HTML ou Markdown limpos direto no Node.js.
const mammoth = require("mammoth");
mammoth.convertToMarkdown({ path: "document.docx" })
.then(result => {
console.log(result.value); // the Markdown output
console.log(result.messages); // warnings about unsupported features
});
O que torna o Mammoth útil é sua postura opinativa: ele ignora totalmente o estilo visual do Word e foca em estrutura semântica (títulos, listas, tabelas). A saída é mais limpa que a do Pandoc por padrão, ao custo de menos controle. Para migrar um acervo legado em que a maioria dos docs tem estrutura consistente, eu escolheria o Mammoth. Para documentos peculiares com formatação pesada, a flexibilidade do Pandoc vence.
Usuários Python têm uma opção parecida com o python-docx combinado com um escritor de Markdown, embora esse seja mais um caminho "faça você mesmo" do que uma ferramenta pronta.
A etapa de limpeza que ninguém te avisa

A conversão te leva até um arquivo .md. Ela não te leva até um arquivo .md que você queira commitar.
Aqui está o checklist padrão que uso depois da conversão. Leva cerca de cinco minutos por documento quando você pega o jeito:
- Procure títulos estruturais perdidos. Busque na saída linhas que parecem títulos mas são
**Texto em Negrito**sozinhas na linha. Alguém estilizou à mão no Word em vez de usar os estilos de Heading. Promova essas linhas para títulos##de verdade. - Confira a primeira tabela. Se as tabelas estão certas aqui, provavelmente estão certas em todo lugar. Se a primeira está quebrada, todas estão.
- Remova linhas em branco dentro de itens de lista. O Pandoc às vezes insere linhas vazias que quebram a continuidade da lista.
- Verifique os links das imagens. Abra o arquivo numa prévia de Markdown (a do VS Code já resolve) e confirme que as imagens carregam.
- Procure artefatos perdidos. Resíduos comuns:
\no fim das linhas (quebras rígidas que o Word esconde mas o Markdown mostra), atributos de estilo{.underline}, tags<span>que escaparam. - Confira as 10 primeiras e 10 últimas linhas. Cabeçalhos, rodapés e números de página do Word muitas vezes vazam para a saída como conteúdo vazio ou artefatos esquisitos.
Para uma migração grande, automatize os itens 5 e 6 com um script de limpeza. O resto ganha muito com olho humano — pelo menos até você ter formado padrão de reconhecimento suficiente para confiar na saída de uma classe específica de documento.
Uma migração real: arquivo de compliance com 200 arquivos
Aqui está o fluxo que usei na migração do arquivo de compliance. Do começo ao fim, foram dois dias de trabalho para um acervo de 200 arquivos.
Dia 1 pela manhã: triagem da origem
Escrevi um script em Python que abria cada DOCX, contava títulos, imagens e tabelas, e marcava qualquer arquivo com Track Changes ainda ativo ou comentários presentes. A saída era um CSV com os arquivos ordenados por complexidade. O objetivo não era corrigir nada ainda — era só saber onde eu estava me metendo.
Dia 1 à tarde: conversão em lote dos arquivos simples
Cerca de 140 dos 200 arquivos eram tranquilos: sem imagens, tabelas simples, estrutura de títulos limpa. Rodei pelo Pandoc em loop com --extract-media e --wrap=none. Conferi 20 amostras aleatórias. Tudo certo.
Dia 2 pela manhã: tratar os arquivos complexos um a um
Os 60 restantes tinham problemas — células mescladas em tabelas, objetos de planilha embutidos ou histórico considerável de Track Changes que alguém precisava revisar antes. Para esses, usei o conversor online caso a caso, às vezes rodando o Pandoc com flags diferentes, às vezes limpando o DOCX de origem primeiro.
Dia 2 à tarde: limpeza e commit
Rodei um script de limpeza sobre os 200 arquivos convertidos (removendo artefatos {.underline}, padronizando marcadores de lista, consertando saídas do Pandoc com quebras de linha). Revisei diffs, commitei em lotes de 50, e empurrei para o branch de migração.
Se eu tivesse tentado fazer qualquer parte disso manualmente — abrindo cada documento Word e colando num editor Markdown — teriam sido pelo menos duas semanas de trabalho. As ferramentas de conversão não são opcionais; são o que torna o projeto viável.
Problemas comuns e como resolver
As tabelas parecem erradas na prévia do Markdown
Noventa por cento das vezes, a fonte tinha células mescladas ou conteúdo muito longo dentro da célula. Tabelas GFM não suportam nenhum dos dois com elegância. Suas opções: reconstruir a tabela manualmente em GFM, usar um bloco HTML <table> dentro do Markdown (a maioria dos renderizadores suporta) ou dividir a tabela em várias menores.
As imagens não estão aparecendo
Verifique se o conversor de fato extraiu as imagens. O Pandoc não extrai a não ser que você use --extract-media. Conversores online geralmente baixam um zip com o arquivo Markdown mais uma pasta images/ — confira se ambos foram parar no lugar certo e se os caminhos no Markdown batem.
A saída tem barras invertidas estranhas no fim das linhas
São quebras rígidas vindas do Word que o Markdown renderiza como quebras forçadas. Se o documento-fonte estava cheio de parágrafos apertados usando quebras de linha em vez de quebras de parágrafo, o Pandoc preserva essas quebras. Um find-and-replace rápido por \\$ (fim de linha) costuma limpar.
Os níveis de título estão errados após a conversão
Documentos Word com frequência começam no Heading 2 ou Heading 3 (porque o Heading 1 ficou reservado para a página de título). A convenção Markdown é começar do # (H1). Dependendo de como seu sistema de docs exibe títulos, pode ser que você precise subir todos os níveis em um. sed dá conta: sed -i 's/^## /# /; s/^### /## /; ...' file.md.
O Markdown não parece em nada com o documento Word visualmente
Isso é esperado. Markdown descreve estrutura, não aparência. O estilo vem de qualquer sistema que renderize o Markdown (GitHub, seu site de docs, tema do MkDocs, etc.). Se a fidelidade visual é crítica, PDF é um destino melhor — veja nosso guia de Markdown para PDF para fluxos que preservam o design visual.
Round-trip: voltar do Markdown para o Word
Uma pergunta natural depois de migrar: "E se eu precisar mandar um documento Markdown de volta para um stakeholder que só abre Word?" Essa é a conversão reversa — e é uma operação bem mais limpa, porque as limitações do Markdown significam que há menos coisa para traduzir. O guia de Markdown para Word cobre esse fluxo.
Para equipes que saltam entre os dois formatos com frequência, o fluxo que vi funcionar é: Markdown é a fonte da verdade no Git, exportações para Word acontecem sob demanda quando alguém precisa revisar ou anotar. Nada nunca é editado no Word e mesclado de volta — esse é o jeito de a migração não se desfazer aos poucos.
Encerrando
Converter Word para Markdown é uma migração, não um apertar de botão. As ferramentas fazem o trabalho pesado — nosso conversor online para arquivos avulsos, Pandoc para lotes, Mammoth.js para pipelines — mas o trabalho real é a inspeção antes de converter e a limpeza depois.
Os dois padrões que mais economizam tempo:
- Triagem primeiro. Entenda o que há no seu acervo antes de começar a converter. Quinze minutos de amostragem evitam horas reagindo a surpresas.
- Espere fazer limpeza. Reserve cinco minutos por documento para a passada de revisão e polimento. Tratar isso como etapa inevitável te mantém honesto quanto ao prazo da migração.
Se você é novo em Markdown e está se perguntando como vai ser a saída, comece pelo o que é Markdown e o guia de sintaxe básica. Para os recursos avançados — tabelas, notas de rodapé, listas de tarefas — a referência de sintaxe estendida cobre o que o GFM suporta.
E se sua migração é a partir do Obsidian em vez do Word, o guia de exportação do Obsidian trata desse fluxo de ponta a ponta.