Como converter PDF para Markdown em 2026 (grátis e pronto para RAG)
Converta PDF para Markdown do jeito certo em 2026. Compare ferramentas online grátis, Pandoc e extratores com IA — com fluxos prontos para RAG e correções de OCR.

Se você já copiou e colou um parágrafo de um PDF e viu o texto explodir num emaranhado de quebras de linha, hifens cortados e formatação perdida, já sabe por que converter PDF para Markdown virou um problema sério de fluxo de trabalho em 2026.
PDFs são a moeda universal para compartilhar documentos. Também são um péssimo formato de origem. No momento em que você quer alimentar esse conteúdo num pipeline RAG, jogar num site de documentação ou só guardar no seu app de notas, você precisa de texto estruturado — cabeçalhos como cabeçalhos, tabelas como tabelas, código como código.
Este guia percorre três caminhos honestos para converter PDF em Markdown: um conversor online sem instalação, Pandoc na linha de comando e a nova leva de extratores com IA como marker e Docling. Vou mostrar qual escolher para cada caso, como consertar o que eles quebram (tabelas, fórmulas, páginas digitalizadas) e como entregar a saída para um pipeline LLM sem precisar limpar duas vezes.
Por que converter PDF para Markdown?
O mesmo problema de conversão reaparece em três comunidades diferentes. Cada uma tem um motivo ligeiramente diferente para se importar, mas o formato de destino é o mesmo.
Alimentar texto limpo em pipelines RAG e LLM
Pipelines de retrieval-augmented generation não gostam de texto bruto de PDF. Artefatos de quebra de página, layouts de duas colunas colapsados em uma só, cabeçalhos e rodapés repetindo em cada página — tudo isso vira ruído no banco de vetores e polui a recuperação.
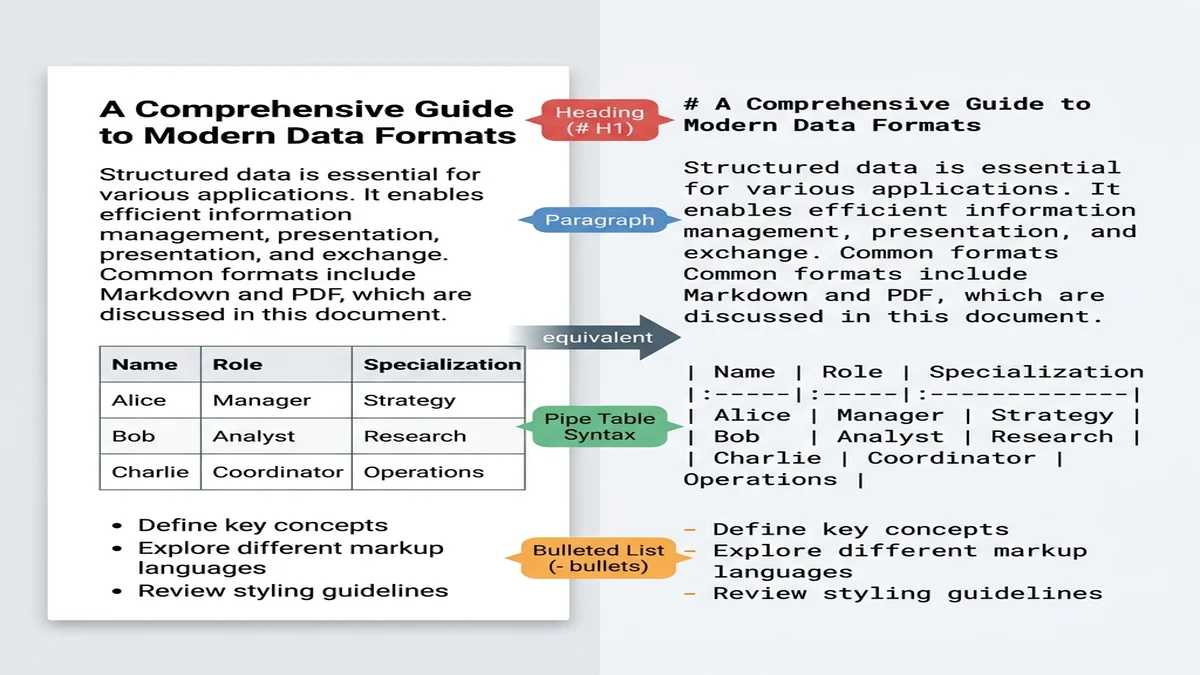
Markdown está mais próximo de "texto puro estruturado" do que qualquer outro formato prático. Grandes modelos treinados em dados da web viram bilhões de documentos markdown (arquivos README, respostas no Stack Overflow, posts de blog), então reconhecem cabeçalhos # como fronteiras de seção e pipes | como separadores de tabela sem precisar de instrução.
Migrar PDFs legados para sistemas de documentação modernos
Docusaurus, MkDocs, Astro Starlight e Hugo querem markdown. Se seu time tem 200 PDFs de documentação interna legada, você não quer um exército de copia-e-cola — quer um conversor que preserve a hierarquia de cabeçalhos para que a navegação se construa sozinha.
Construir um segundo cérebro pesquisável
Obsidian, Logseq, Foam, Roam — todo app de notas moderno fala markdown. Acadêmicos digitalizando arquivos em papel, profissionais do conhecimento arquivando atas de reunião e pesquisadores construindo bibliotecas de literatura precisam todos da mesma coisa: um arquivo markdown limpo com os cabeçalhos intactos, para depois conseguir fazer grep em centenas de documentos.
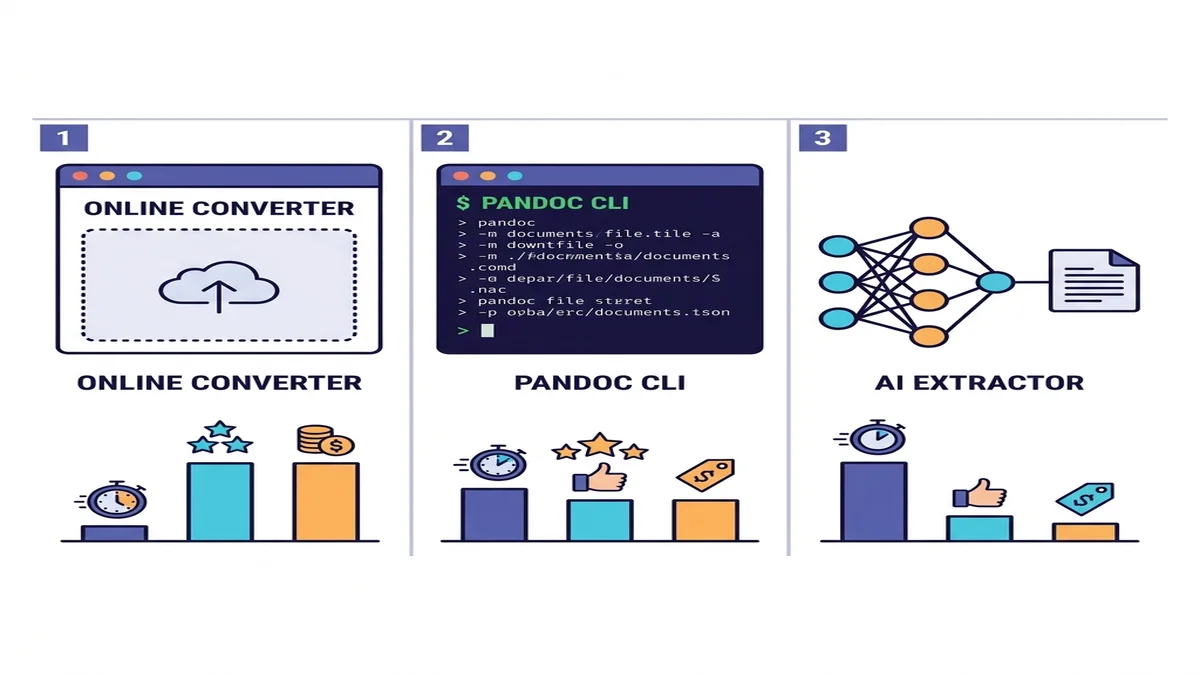
As três abordagens (quando usar cada uma)
Existem dezenas de ferramentas, mas só três categorias de verdade. Escolha a linha que combina com sua situação.
| Método | Velocidade | PDFs simples | PDFs complexos | OCR para digitalizados | Setup |
|---|---|---|---|---|---|
| Conversor online | Rápido | Excelente | Bom | Embutido ou automático | Nenhum |
| Pandoc + pdftotext | Rápido | Bom | Médio em tabelas | Não | Instalação CLI |
| Extrator com IA (marker / Docling) | Lento | Excelente | Excelente | Sim | Python + dependências de ML |
Se não tem certeza qual escolher, comece pelo conversor online. Custa um minuto para testar, e para a maioria dos trabalhos pontuais ou em pequenos lotes a história acaba aí. Para pipelines programáticos ou conteúdo acadêmico denso, desça uma linha. Comparamos o cenário mais amplo na nossa análise de conversores Markdown grátis.
Método 1: Converter PDF para Markdown online (grátis, sem instalação)
O caminho mais rápido também é o que mais gente pula porque parece simples demais. Para uma fatia esmagadora do trabalho cotidiano — atas de reunião, artigos, relatórios de um único capítulo — um conversor no navegador já dá conta com folga.
Você pode arrastar seu arquivo direto para o nosso conversor de PDF para Markdown grátis e pular o resto desta seção.
Fluxo passo a passo
- Arraste e solte o PDF na zona de upload (ou clique para escolher um arquivo).
- Espere alguns segundos pelo parser terminar. Qualquer coisa abaixo de 20 páginas costuma converter antes de você reler esta frase.
- Pré-visualize o markdown renderizado ao lado do código-fonte à direita.
- Copie o código-fonte ou baixe um arquivo
.md.
É isso. Sem contas, sem barreira de e-mail, sem marca d'água na saída.
Quando funciona melhor
- Conversões avulsas em que você não quer instalar nada.
- Testes rápidos antes de decidir investir num pipeline programático.
- Arquivos sensíveis em que você prefere não enviar o documento para uma API de terceiros. Nosso conversor processa os arquivos em memória e os descarta na hora — sem armazenamento persistente.
Limitações
Conversores online em geral (não só o nosso) têm dois modos de falha que vale conhecer.
O primeiro são PDFs muito grandes ou incomuns. Uma intimação jurídica digitalizada de 600 páginas com fontes embutidas e campos de formulário dinâmicos não é um cenário "arrasta e baixa" para ferramenta nenhuma. Se você tem uma dessas, pule para a seção de extratores com IA.
O segundo são PDFs digitalizados sem camada de texto. Não há texto a extrair — a página é só uma imagem. Você precisa de OCR primeiro; veja Lidando com conteúdo complicado mais abaixo.
Método 2: Pandoc na linha de comando
Pandoc é o canivete suíço da conversão de documentos. É a ferramenta certa quando você precisa de um pipeline reprodutível e roteirizável e não quer depender de um serviço web.
O porém honesto: o próprio Pandoc não tem um leitor de PDF forte. O fluxo da comunidade passa pelo pdftotext (das utilidades Poppler) e canaliza o resultado para o Pandoc.
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
Para um PDF simples e pesado em texto — um memorando, um artigo de coluna única — esse combo funciona bem e roda em milissegundos.
Quando a fidelidade importa
Se seu PDF é majoritariamente prosa, esse pipeline te dá um arquivo markdown limpo com a estrutura de parágrafos intacta. Adicione as flags -V e --wrap=none para ajustar a saída a ferramentas downstream que não gostam de linhas com quebra forçada.
Onde o Pandoc tropeça
- Layouts multi-coluna (artigos acadêmicos, revistas):
pdftotextintercala as colunas e você obtém uma saída ilegível. - Tabelas: qualquer coisa além da grade simples de duas colunas costuma chegar como colunas separadas por espaço, em vez de pipes markdown.
- Fórmulas e blocos de código: não há preservação semântica; equações LaTeX viram texto, e código monoespaçado vira parágrafo comum.
- PDFs digitalizados: suporte zero — Pandoc/pdftotext não conseguem extrair texto de imagens.
Para tabelas especificamente, nosso guia de sintaxe Markdown estendida cobre o formato de tabela GFM ao qual você vai querer alinhar a saída.
Método 3: Extração com IA (marker, Docling, pymupdf4llm)
A leva de extratores cientes de layout de 2024-2025 mudou o que é possível fazer. Essas ferramentas combinam detecção visual de layout com OCR e geração de saída estruturada, então elas entendem que esta região é uma tabela e aquela região é um corpo de texto em duas colunas. A saída fica drasticamente mais limpa em PDFs complexos.
Três projetos que vale conhecer:
- marker — usa surya (um modelo de layout) somado a heurísticas. Forte em artigos acadêmicos, fórmulas e blocos de código. Apache 2.0.
- Docling — da IBM Research. Excelente reconstrução de tabelas, integra nativamente com LlamaIndex e LangChain. Licença MIT.
- pymupdf4llm — wrapper leve em torno do PyMuPDF. Mais rápido que os outros dois, menos dependências de ML, desenhado especificamente para ingestão por LLM.
Um exemplo mínimo em Python
Aqui está o menor pipeline útil com Docling:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
Ou com pymupdf4llm, para o caminho mais enxuto:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
Trade-offs
Essas ferramentas são mais lentas que o pipeline com Pandoc. Num notebook com CPU comum, espere que um artigo de 30 páginas leve dezenas de segundos em vez de milissegundos; com GPU, isso cai para poucos segundos no caso do marker. pymupdf4llm é o mais rápido dos três porque dispensa os modelos de visão pesados.
O outro trade-off é o peso das dependências. Um pip install marker-pdf traz junto o PyTorch e algumas centenas de megabytes de pesos de modelo. Se você vai distribuir isso num contêiner, planeje o tamanho.
Lidando com conteúdo complicado
As diferenças entre os métodos ficam óbvias quando você para de testar com memorandos de duas páginas e começa a passar PDFs do mundo real pelo pipeline.
Tabelas que não sobrevivem
Tabelas são onde a maioria dos conversores falha. O caminho pdftotext + Pandoc quase sempre produz uma sopa de colunas alinhadas por espaço que nenhum renderizador markdown vai parsear corretamente. Conversores online e extratores com IA se saem muito melhor aqui porque detectam a região da tabela primeiro e depois reconstroem as células.
O truque: confira sua primeira tabela de saída antes de confiar no resto. Se a primeira tabela está destruída, as outras 50 também vão estar.
Equações matemáticas e blocos LaTeX
Se seu PDF tem equações, você precisa de uma ferramenta que detecte regiões de fórmula e emita blocos LaTeX ($$...$$) no markdown. O marker faz isso; o Pandoc não. Para escrita científica, esse é o motivo número um para pagar o custo de velocidade do extrator com IA.
Blocos de código e código inline
Muitos PDFs renderizam código numa fonte monoespaçada mas perdem a etiqueta semântica "isto é código" na exportação. Extratores com IA re-detectam regiões de código pelo estilo visual — a fonte monoespaçada e a indentação — e as reembrulham em cercas de três crases. Pipelines baseados em Pandoc costumam achatar o código de volta em parágrafos comuns.
Notas de rodapé e citações
Artigos acadêmicos usam notas de rodapé numeradas com o corpo da nota na base da página. O caminho pdftotext perde o vínculo entre o marcador de referência e o corpo da nota. Docling e marker preservam isso como sintaxe própria de footnote do markdown (referência [^1] + definição [^1]: corpo).
PDFs digitalizados (OCR obrigatório)
Um PDF digitalizado é a imagem de uma página, não texto. Não há nada para extrair até você rodar OCR primeiro.

Três caminhos confiáveis:
-
ocrmypdf — adiciona uma camada invisível de texto OCR a um PDF digitalizado sem mexer na aparência visual. Uma vez aplicada a camada, qualquer conversor downstream funciona:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
Extratores com IA em modo OCR — marker e Docling detectam quando uma página não tem camada de texto e rodam OCR automaticamente. A saída é integrada, então você recebe um arquivo markdown único em vez de um PDF intermediário.
-
Conversores online com OCR automático — algumas ferramentas no navegador (a nossa inclusive, para PDFs só de imagem) rodam OCR de forma transparente. Conveniente, mas fique de olho no suporte de idiomas se seu documento não for em inglês.
Uma armadilha sutil: PDFs "born-digital" (criados a partir de um documento Word, não digitalizados) ainda podem não ter camada de texto se foram exportados como imagens achatadas. Sempre cheque primeiro se consegue selecionar texto dentro do visualizador de PDF. Se conseguir, pule o OCR. Se não, rode.
Preparando o Markdown para ingestão RAG / LLM
Se o destino é um banco de vetores, algumas pequenas escolhas durante a conversão deixam a qualidade da recuperação notavelmente melhor lá na frente.
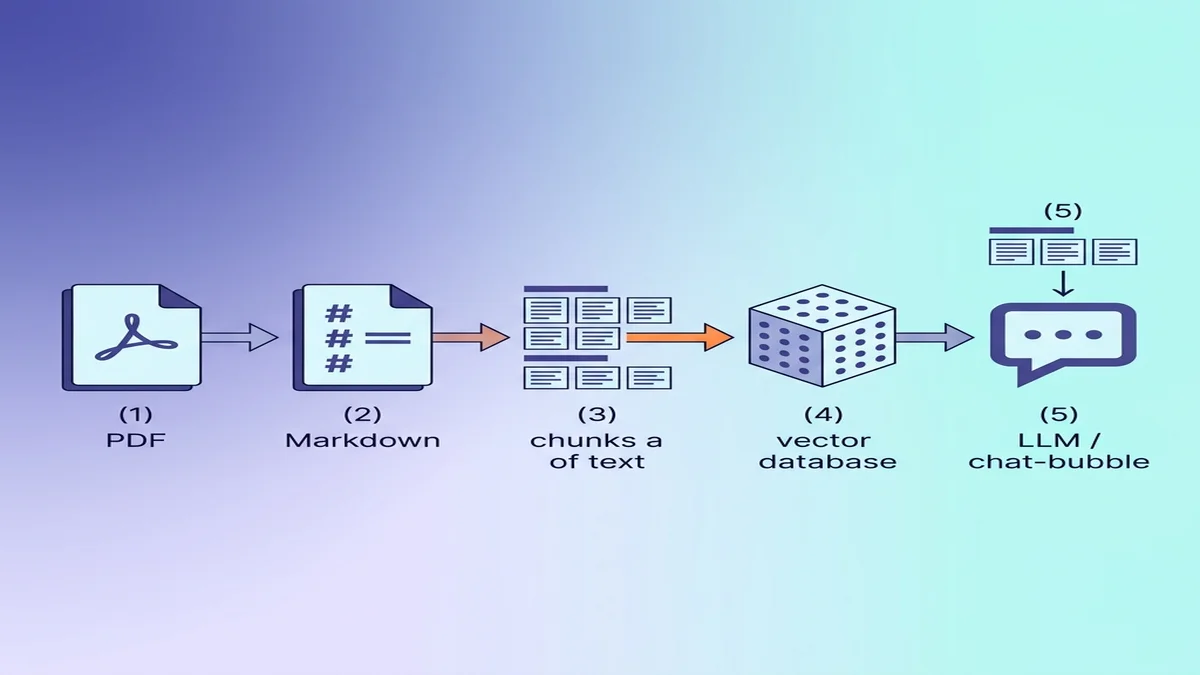
Por que Markdown ganha do texto puro para LLMs
Markdown carrega estrutura que o texto puro perde. Um modelo lendo ## Métodos sabe que entrou numa nova seção; um modelo lendo o mesmo texto com toda a formatação removida vê apenas parágrafos de peso igual. Se a sintaxe é novidade para você, nosso guia básico de Markdown é leitura de 5 minutos.
Fragmentação pela hierarquia de cabeçalhos
O erro mais comum em RAG é fragmentação por tamanho fixo — partir o documento em blocos de 500 tokens independentemente da estrutura. Markdown te deixa fragmentar semanticamente — quebre nas fronteiras de ## H2 e você ganha seções coerentes em vez de pedaços no meio de parágrafo.
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
Melhor: percorra os cabeçalhos como uma árvore, anexando cada H3 ao seu H2 pai nos metadados do chunk.
Preservando metadados no frontmatter
Adicione frontmatter YAML no topo de cada arquivo convertido para que a informação de origem viaje com cada chunk:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
Quando o LLM recupera um chunk, esses metadados viram o rodapé de citação. É assim também que você eventualmente responde à pergunta "de onde veio essa afirmação?" sem ter que rodar a recuperação de novo. Se você está montando esse tipo de pipeline a partir de exports de chat, a mesma ideia se aplica a transcrições do ChatGPT/Claude.
Armadilhas comuns e como evitá-las
Algumas coisas pegam quem está fazendo isso pela primeira vez.
- Pular a normalização de encoding. PDFs adoram truques de Unicode: ligaduras (
fi,fl), aspas curvas ("vs"), travessões que parecem hifens. Passe a saída por uma rodada de normalização Unicode (NFKC em Python) antes de jogar em qualquer lugar. - Deixar cabeçalhos e rodapés de página. O rodapé
Página 4 de 12de cada página vira ruído na sua recuperação. Remova linhas repetidas que aparecem em intervalos regulares. - Confiar na primeira tabela que aparece. Confira ao menos as duas primeiras tabelas antes de assumir que o resto está bom.
- Achar que "born-digital" significa "tem camada de texto". Alguns PDFs são exportados como imagens achatadas mesmo tendo nascido como documentos Word. Sempre tente selecionar texto primeiro.
- Fragmentar demais documentos pequenos. Para um memorando de 3 páginas, jogue o markdown inteiro no modelo e pule a etapa de RAG. Recuperação é overkill quando a janela de contexto > documento.
FAQ
Qual é o melhor conversor grátis de PDF para Markdown?
Para a maioria dos usuários, um conversor online é o caminho mais rápido — arrasta, solta, pronto. Para trabalho em lote ou programático, pymupdf4llm (Python) e Pandoc (CLI) cobrem os casos simples. Para artigos acadêmicos com tabelas e fórmulas, marker e Docling produzem uma saída visivelmente melhor. A "melhor" escolha depende se você otimiza por tempo de setup ou por fidelidade da saída.
ChatGPT ou Claude conseguem converter PDF para Markdown?
Conseguem, com ressalvas. Os dois leem um PDF diretamente e produzem saída markdown, mas em documentos longos você pode esbarrar nos limites de contexto, e a precisão em tabelas e fórmulas varia entre execuções. Para conversões em lote determinísticas, um conversor dedicado é mais confiável. Veja exportando ChatGPT para Word/PDF/HTML para o fluxo de ida e volta relacionado.
Como converter um PDF digitalizado para Markdown?
Rode OCR primeiro. O caminho mais limpo é usar ocrmypdf para adicionar uma camada de texto, e aí qualquer conversor funciona no PDF com OCR. Alternativamente, marker e Docling têm OCR embutido e produzem markdown direto a partir de PDFs só de imagem.
A conversão online de PDF para Markdown é privada?
Com o nosso conversor, os arquivos são processados em memória e descartados após a conversão — sem cadastro, sem armazenamento persistente. Outros serviços variam; cheque a política de privacidade de qualquer ferramenta que você use, especialmente para documentos confidenciais.
Como manter tabelas intactas ao converter PDF para Markdown?
Pule o pipeline pdftotext + Pandoc para PDFs cheios de tabela — ele quase sempre destrói. Use um conversor online que emita tabelas GFM, ou um extrator com IA como marker ou Docling. Faça spot-check das primeiras tabelas de qualquer jeito.
Devo manter o PDF original ou só o Markdown?
Mantenha os dois. O markdown é para ingestão, busca e edição. O PDF é sua fonte da verdade para citação e auditoria. Referencie o nome do arquivo PDF e o intervalo de páginas no frontmatter do markdown para sempre conseguir rastrear uma afirmação até sua origem.
Pronto para converter seu primeiro PDF?
Se você só quer o resultado, nosso conversor de PDF para Markdown grátis dá conta dos casos cotidianos sem cadastro. Para o próximo passo — transformar esse markdown num documento Word caprichado ou num PDF pronto para compartilhar — veja nosso guia de Markdown para Word.
Referências
- Pandoc User's Guide — a referência canônica para conversão via CLI.
- GitHub Flavored Markdown Spec — o dialeto que este guia mira na saída.
- Docling (IBM Research) — extrator open-source de PDF ciente de layout.
- marker — conversor open-source de PDF para markdown com bom desempenho em artigos acadêmicos.
- pymupdf4llm — wrapper leve de extração markdown em torno do PyMuPDF.
- OCRmyPDF — adiciona uma camada de texto pesquisável a PDFs digitalizados.