كيف تحوّل PDF إلى Markdown في 2026 (مجانًا وجاهز لـ RAG)
حوّل PDF إلى Markdown بالطريقة الصحيحة في 2026. مقارنة بين أدوات الإنترنت المجانية وPandoc ومستخرِجات الذكاء الاصطناعي — مع تدفقات جاهزة لـ RAG وحلول OCR.

إذا سبق أن نسخت فقرة من ملف PDF ولصقتها لتراها تتحوّل إلى فوضى من فواصل الأسطر والشرطات المكسورة والتنسيق الضائع، فأنت تعرف بالفعل لماذا أصبح تحويل PDF إلى Markdown مشكلة سير عمل جدية في 2026.
ملفات PDF هي العملة العالمية لمشاركة المستندات. وهي في الوقت نفسه تنسيق مصدر سيّئ. في اللحظة التي تريد فيها إدخال محتواها إلى خط أنابيب RAG، أو وضعها في موقع توثيق، أو حتى تخزينها في تطبيق ملاحظاتك، فأنت تحتاج نصًا مهيكلًا — العناوين عناوين، والجداول جداول، والشفرة شفرة.
يستعرض هذا الدليل ثلاث طرق صادقة لتحويل PDF إلى Markdown: محوّل عبر الإنترنت بلا تنصيب، وPandoc من سطر الأوامر، والموجة الجديدة من مستخرجات الذكاء الاصطناعي مثل marker وDocling. سأريك أيها تختار لأيّ مهمة، وكيف تصلح ما تكسره (الجداول، المعادلات، الصفحات الممسوحة ضوئيًا)، وكيف تشحن المخرجات إلى خط أنابيب LLM دون أن تنظّفها مرتين.
لماذا تحوّل PDF إلى Markdown؟
نفس مشكلة التحويل تطلّ برأسها في ثلاث مجتمعات مختلفة. لكلٍّ منها سبب مختلف قليلًا للاهتمام، لكن تنسيق الوجهة واحد.
تغذية نص نظيف لخطوط أنابيب RAG وLLM
خطوط أنابيب التوليد المعزّز بالاسترجاع لا تحب نص PDF الخام. آثار فواصل الصفحات، والتخطيطات ثنائية الأعمدة المنهارة إلى عمود واحد، وترويسات الصفحات وتذييلاتها المتكرّرة في كل صفحة — كل ذلك يتحوّل إلى ضوضاء داخل قاعدة بيانات المتجهات ويلوّث الاسترجاع.
Markdown أقرب إلى "نص عادي مهيكل" من أي تنسيق عملي آخر. النماذج الضخمة المدرّبة على بيانات الويب رأت مليارات مستندات Markdown (ملفات README، إجابات Stack Overflow، تدوينات)، لذا تتعرّف على عناوين # كحدود أقسام، وعلى الـ pipes | كفواصل جدول، دون الحاجة إلى تلميح.
نقل ملفات PDF القديمة إلى أنظمة التوثيق الحديثة
Docusaurus وMkDocs وAstro Starlight وHugo كلها تريد Markdown. إذا كان لدى فريقك 200 ملف PDF من توثيق داخلي قديم، فأنت لا تريد جيشًا من النسخ واللصق — تريد محوّلًا يحافظ على هرمية العناوين كي يبني التنقّل نفسه بنفسه.
بناء "دماغ ثانٍ" قابل للبحث
Obsidian وLogseq وFoam وRoam — كل تطبيق ملاحظات حديث يتحدّث Markdown. الأكاديميون الذين يرقمنون الأرشيف الورقي، والعاملون بالمعرفة الذين يؤرشفون تقارير الاجتماعات، والباحثون الذين يبنون مكتبات أدبية، كلهم يحتاجون الشيء نفسه: ملف Markdown نظيفًا بعناوين سليمة، يمكنهم لاحقًا البحث فيه عبر مئات المستندات.
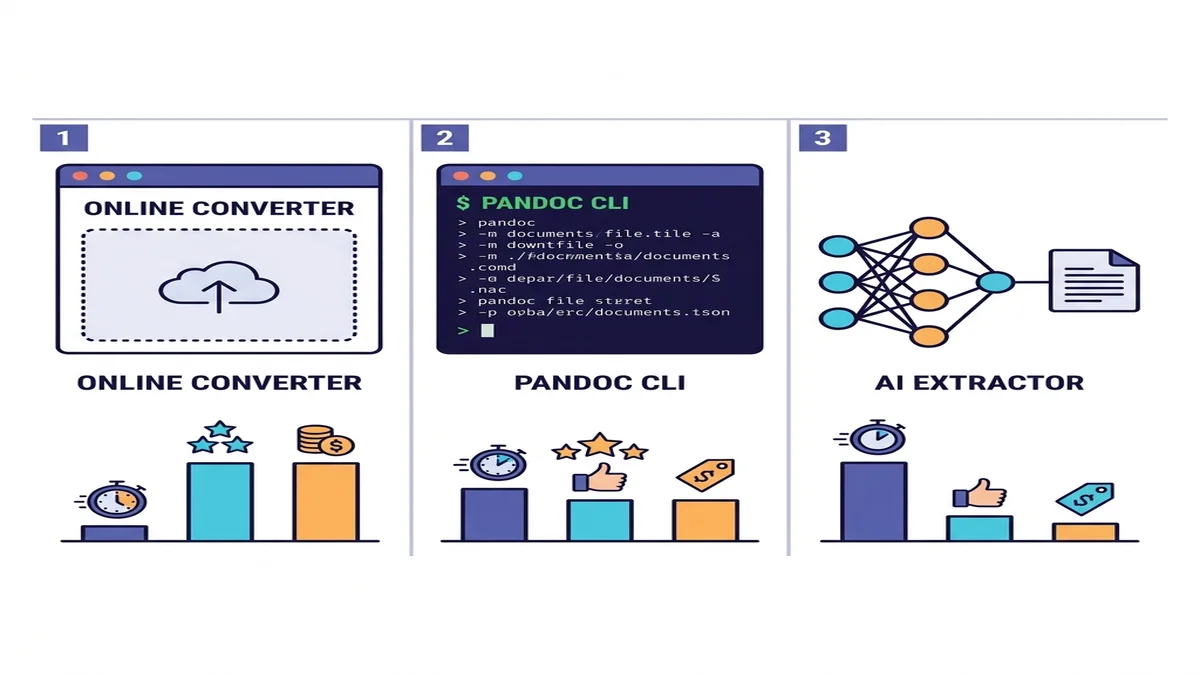
الطرق الثلاث (متى تستخدم أيّها)
ثمة عشرات الأدوات، لكن الفئات في الواقع ثلاث فقط. اختر الصف الذي يطابق وضعك.
| الطريقة | السرعة | PDFs بسيطة | PDFs معقّدة | OCR للمسح الضوئي | الإعداد |
|---|---|---|---|---|---|
| محوّل عبر الإنترنت | سريع | ممتاز | جيد | مدمج أو تلقائي | لا شيء |
| Pandoc + pdftotext | سريع | جيد | متوسط على الجداول | لا | تنصيب CLI |
| مستخرج ذكاء اصطناعي (marker / Docling) | بطيء | ممتاز | ممتاز | نعم | Python + اعتماديات ML |
إن لم تكن متأكدًا أيّها تختار، ابدأ بمحوّل عبر الإنترنت. يكلّفك دقيقة لتجريبه، ولمعظم المهام المنفردة أو الدفعات الصغيرة، تنتهي القصة هنا. لخطوط الأنابيب البرمجية أو المحتوى الأكاديمي الكثيف، انزل صفًا أو صفّين. نقارن المشهد الأوسع في جولتنا حول محوّلات Markdown المجانية.
الطريقة 1: تحويل PDF إلى Markdown عبر الإنترنت (مجاني، بلا تنصيب)
أسرع مسار هو أيضًا الذي يتخطّاه معظم الناس لأنه يبدو بسيطًا أكثر من اللازم. لقسط ساحق من الأعمال اليومية — ملاحظات الاجتماعات، المقالات، التقارير المؤلّفة من فصل واحد — المحوّل المستند إلى المتصفح يفي بالغرض وأكثر.
يمكنك إفلات ملفك مباشرة في محوّلنا المجاني من PDF إلى Markdown وتجاوز بقية هذا القسم.
سير العمل خطوة بخطوة
- اسحب ملف PDF وأفلته على منطقة الرفع (أو انقر لاختيار ملف).
- انتظر بضع ثوانٍ حتى ينتهي المحلّل. أي شيء دون 20 صفحة يُحوَّل عادةً قبل أن تقرأ هذه الجملة مرتين.
- عاين Markdown المرسوم بجانب الشفرة المصدر على اليمين.
- انسخ المصدر، أو حمّل ملف
.md.
هذا كل شيء. لا حسابات، ولا بوّابة بريد إلكتروني، ولا علامة مائية على المخرجات.
متى يصلح هذا أفضل ما يكون
- التحويلات الفردية حين لا ترغب في تنصيب أي شيء.
- الفحوص السريعة قبل قرار الاستثمار في خط أنابيب برمجي.
- الملفات الحسّاسة للخصوصية التي تفضّل ألّا تدفعها إلى واجهة API خارجية. محوّلنا يعالج الملفات داخل الذاكرة ويُسقطها فورًا — بلا تخزين دائم.
القيود
محوّلات الإنترنت بشكل عام (لا محوّلنا فحسب) لها وضعا فشل يستحقّان المعرفة.
الأول هو ملفات PDF الكبيرة جدًا أو غير المألوفة. مستند إفصاح قانوني ممسوح ضوئيًا من 600 صفحة، بخطوط مضمّنة وحقول نموذج ديناميكية، ليس سيناريو "أفلت ونزّل" لأي أداة. إن كان لديك واحد من هذه، فاقفز إلى قسم مستخرج الذكاء الاصطناعي.
الثاني هو ملفات PDF الممسوحة ضوئيًا بلا طبقة نصّ. لا يوجد نص لاستخراجه — الصفحة مجرد صورة. تحتاج OCR أولًا؛ انظر التعامل مع المحتوى الصعب أدناه.
الطريقة 2: Pandoc على سطر الأوامر
Pandoc هو سكين الجيش السويسري لتحويل المستندات. إنه الأداة الصحيحة حين تحتاج خط أنابيب قابلًا للتكرار وللبرمجة دون الاعتماد على خدمة ويب.
المأخذ بصراحة: Pandoc بحدّ ذاته ليس لديه قارئ PDF قوي. سير العمل المعتمد لدى المجتمع يمرّ عبر pdftotext (من أدوات Poppler) ويُغذّي النتيجة إلى Pandoc.
# Extract text preserving layout, then convert to GFM markdown
pdftotext -layout input.pdf - | pandoc -f markdown -t gfm -o output.md
لـ PDF بسيط مزدحم بالنصوص — مذكّرة، مقال أحادي العمود — يعمل هذا المزيج جيدًا ويُنفَّذ في أجزاء من الثانية.
حين تهم الدقّة
إن كان PDF لديك نثرًا في معظمه، فهذا الخط يمنحك ملف Markdown نظيفًا ببنية فقرات سليمة. أضف العلامات -V و--wrap=none لضبط المخرجات للأدوات النهائية التي لا تحبّ الأسطر الملفوفة بصرامة.
أين يتعثّر Pandoc
- التخطيطات متعدّدة الأعمدة (الأوراق الأكاديمية، المجلات): يمزج
pdftotextالأعمدة فتحصل على مخرجات غير قابلة للقراءة. - الجداول: أي شيء يتجاوز أبسط شبكة بعمودين يصل عادةً كأعمدة مفصولة بمسافات بدل أنابيب Markdown.
- المعادلات وكتل الشفرة: لا حفاظ دلاليًا؛ تتحوّل معادلات LaTeX إلى نص، وتتحوّل الشفرة أحادية العرض إلى فقرات عادية.
- PDFs الممسوحة ضوئيًا: لا دعم البتّة — لا يستطيع Pandoc/pdftotext استخراج نصّ من الصور.
للجداول تحديدًا، يغطّي دليل صياغة Markdown الموسّعة صيغة جداول GFM التي تريد أن تطابقها المخرجات.
الطريقة 3: استخراج بالذكاء الاصطناعي (marker، Docling، pymupdf4llm)
موجة 2024-2025 من المستخرجات الواعية بالتخطيط غيّرت ما هو ممكن. تجمع هذه الأدوات بين الكشف البصري للتخطيط وOCR وتوليد المخرجات المهيكلة، فتفهم أن هذه المنطقة جدول وأن تلك المنطقة جسم نصّ بعمودين. المخرجات أنظف بشكل لافت على ملفات PDF المعقّدة.
ثلاثة مشاريع تستحق المعرفة:
- marker — يستخدم surya (نموذج تخطيط) مع heuristics. قوي على الأوراق الأكاديمية والمعادلات وكتل الشفرة. Apache 2.0.
- Docling — من IBM Research. إعادة بناء ممتازة للجداول، ويتصل بـ LlamaIndex وLangChain بشكل أصلي. مرخّص MIT.
- pymupdf4llm — غلاف خفيف حول PyMuPDF. أسرع من الاثنين الآخرين، اعتماديات ML أقل، مصمَّم خصّيصًا لاستيعاب LLM.
مثال Python أدنى
إليك أصغر خط أنابيب Docling مفيد:
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("paper.pdf")
markdown = result.document.export_to_markdown()
with open("paper.md", "w") as f:
f.write(markdown)
أو مع pymupdf4llm للمسار الأخف:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("paper.pdf")
with open("paper.md", "w") as f:
f.write(md_text)
المقايضات
هذه الأدوات أبطأ من خط Pandoc. على حاسوب محمول بمعالج عادي، توقّع أن تستغرق ورقة من 30 صفحة عشرات الثواني بدل أجزاء من الثانية؛ مع GPU، يهبط ذلك إلى بضع ثوانٍ لـ marker. pymupdf4llm هو الأسرع بين الثلاثة لأنه يتخطّى نماذج الرؤية الثقيلة.
المقايضة الأخرى وزن الاعتماديات. pip install marker-pdf يجلب PyTorch وبضع مئات من الميغابايتات من أوزان النماذج. إذا كنت ستشحن ذلك في حاوية، خطّط للحجم.
التعامل مع المحتوى الصعب
تظهر الفروق بين الطرق جليّةً حين تتوقّف عن الاختبار على مذكّرات نظيفة من صفحتين وتبدأ بتمرير ملفات PDF حقيقية.
الجداول التي لا تنجو
الجداول هي حيث تفشل أغلب المحوّلات. مسار pdftotext + Pandoc يُنتج تقريبًا دائمًا حساء أعمدة محاذاة بالمسافات لا يستطيع أي عارض Markdown تحليله بشكل صحيح. المحوّلات عبر الإنترنت ومستخرجات الذكاء الاصطناعي تبلي بلاءً أفضل بكثير هنا، لأنها تكتشف منطقة الجدول أولًا ثم تعيد بناء الخلايا.
الحيلة: افحص أوّل جدول مخرَج قبل أن تثق في البقية. إن كان الأول مشوّهًا، فالخمسون الباقون سيكونون كذلك.
المعادلات وكتل LaTeX
إن كان PDF لديك يحتوي على معادلات، فأنت تحتاج أداة تكتشف مناطق الرياضيات وتُصدر كتل LaTeX ($$...$$) في Markdown. marker يفعل ذلك؛ Pandoc لا. للكتابة العلمية هذا هو السبب الأوحد الأكبر لدفع تكلفة سرعة مستخرج الذكاء الاصطناعي.
كتل الشفرة والشفرة السطرية
كثير من ملفات PDF تعرض الشفرة بخط أحادي العرض لكنها تفقد الوسم الدلالي "هذا شفرة" في التصدير. تعيد مستخرجات الذكاء الاصطناعي اكتشاف مناطق الشفرة عبر الأسلوب البصري — الخط أحادي العرض والمسافات البادئة — وتعيد لفّها بأسوار ثلاث علامات backtick. الخطوط المعتمدة على Pandoc تُسطّح الشفرة عادةً إلى فقرات عادية.
الحواشي والاقتباسات
تستخدم الأوراق الأكاديمية حواشي مرقّمة مع نصّ الحاشية في أسفل الصفحة. مسار pdftotext يفقد الصلة بين علامة المرجع ونصّ الحاشية. Docling وmarker يحافظان عليها كصيغة حواشي Markdown سليمة (مرجع [^1] + تعريف [^1]: body).
ملفات PDF الممسوحة ضوئيًا (OCR مطلوب)
ملف PDF ممسوح ضوئيًا هو صورة لصفحة، لا نصّ. لا شيء لاستخراجه قبل تشغيل OCR أولًا.

ثلاثة مسارات موثوقة:
-
ocrmypdf — يضيف طبقة نص OCR غير مرئية إلى ملف PDF ممسوح ضوئيًا دون تغيير المظهر البصري. بمجرّد طبقتها، يعمل أي محوّل لاحق:
ocrmypdf scan.pdf scan-with-ocr.pdf pandoc scan-with-ocr.pdf -o scan.md -
مستخرجات الذكاء الاصطناعي مع وضع OCR — يستطيع marker وDocling اكتشاف أن الصفحة بلا طبقة نص وتشغيل OCR تلقائيًا. المخرجات متكاملة، فتحصل على ملف Markdown واحد بدل ملف PDF وسيط.
-
محوّلات عبر الإنترنت مع OCR تلقائي — بعض أدوات المتصفح (محوّلنا من بينها لملفات PDF التي هي صور فقط) تشغّل OCR بشفافية. مريح، لكن انتبه لدعم اللغة إن لم يكن مستندك بالإنجليزية.
فخّ دقيق: ملفات PDF "المولودة رقميًا" (المُصدَّرة من مستند Word، لا الممسوحة ضوئيًا) قد تفتقر إلى طبقة نص إن صُدِّرت كصور مسطّحة. تحقّق دائمًا أولًا أن باستطاعتك تحديد النص داخل عارض PDF. إن استطعت، تخطّ OCR. إن لم تستطع، شغّله.
تجهيز Markdown لاستيعاب RAG / LLM
إن كانت الوجهة قاعدة بيانات متجهات، فبضعة اختيارات صغيرة أثناء التحويل تجعل جودة الاسترجاع لاحقًا أفضل بشكل ملحوظ.
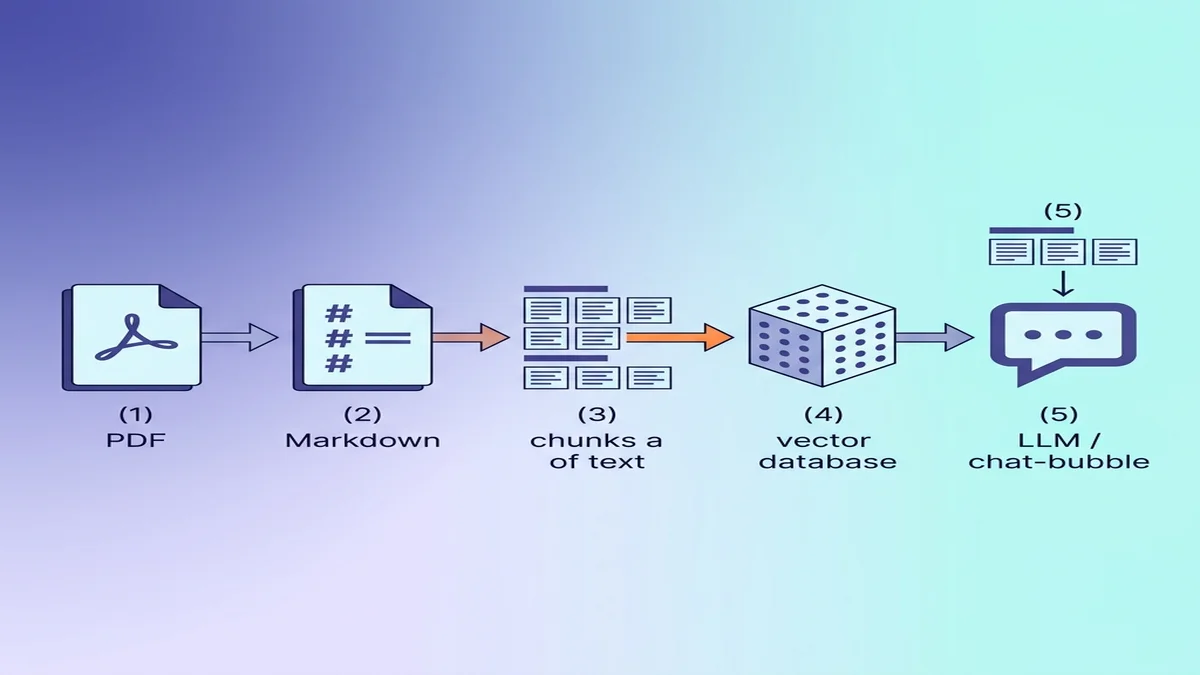
لماذا يتفوّق Markdown على النص الخام أمام LLMs
Markdown يحمل بنية يفقدها النص العادي. النموذج الذي يقرأ ## Methods يعرف أنه دخل قسمًا جديدًا؛ النموذج الذي يقرأ النص ذاته مجرّدًا من كل التنسيق لا يرى سوى فقرات بوزن متساوٍ. إن كنت جديدًا على الصياغة، فـدليلنا الأساسي في Markdown قراءة من 5 دقائق.
التقسيم بحسب هرمية العناوين
الخطأ الأكثر شيوعًا في RAG هو التقسيم بحجم ثابت — تقطيع المستند إلى كتل من 500 رمز بصرف النظر عن البنية. Markdown يتيح لك التقسيم دلاليًا — اقطع على حدود ## H2 فتحصل على أقسام متماسكة بدل شظايا في منتصف الفقرة.
# Coarse chunk: split on H2
sections = markdown.split("\n## ")
# Each section now starts at a section header and contains its sub-tree
أفضل: امشِ على العناوين كشجرة، مرفقًا كل H3 بأبيه H2 في بيانات وصف الكتلة.
الحفاظ على البيانات الوصفية في frontmatter
أضف YAML frontmatter في أعلى كل ملف محوَّل بحيث تسافر معلومات المصدر مع كل كتلة:
---
source: research-paper-2025.pdf
authors: ["Smith, J.", "Doe, A."]
year: 2025
section: "Introduction"
page_range: "1-3"
---
حين يسترجع LLM كتلة، تصبح هذه البيانات الوصفية تذييل اقتباس. وهي أيضًا كيف ستجيب لاحقًا عن سؤال "من أين جاءت هذه الفِكرة؟" دون إعادة تشغيل الاسترجاع. إن كنت تبني هذا النوع من خطوط الأنابيب من تصديرات الدردشة، الفكرة نفسها تنطبق على نسخ ChatGPT/Claude.
أخطاء شائعة وكيف تتفاداها
بضعة أمور تعضّ من يخوض هذا للمرة الأولى.
- تخطّي تطبيع الترميز. ملفات PDF تحب حيل Unicode: الـ ligatures (
fi,fl)، علامات الاقتباس الذكية ("مقابل")، شَرَطات em التي تبدو كشرطات. مرّر المخرجات عبر تمرير تطبيع Unicode (NFKC في Python) قبل تغذيتها لأي شيء. - ترك ترويسات الصفحات وتذييلاتها. تذييل كل صفحة
Page 4 of 12يصبح ضوضاء في استرجاعك. جرّد الأسطر المكرّرة التي تظهر على فواصل منتظمة. - الثقة بأول جدول تراه. افحص على الأقل أول جدولَين قبل افتراض أن البقية بخير.
- افتراض أن "مولود رقميًا" يعني "له طبقة نص". بعض ملفات PDF تُصدَّر كصور مسطّحة رغم أنها بدأت كمستندات Word. حاول دائمًا تحديد النص أولًا.
- الإفراط في تقسيم المستندات الصغيرة. لمذكّرة من 3 صفحات، غذِّ Markdown كاملًا للنموذج وتخطّ خطوة RAG برمّتها. الاسترجاع مبالغة حين تكون نافذة السياق > المستند.
الأسئلة الشائعة
ما أفضل محوّل مجاني من PDF إلى Markdown؟
لمعظم المستخدمين، المحوّل عبر الإنترنت هو الأسرع — اسحب، أفلت، انتهى. للأعمال الدفعية أو البرمجية، يغطّي pymupdf4llm (Python) وPandoc (CLI) الحالات البسيطة. للأوراق الأكاديمية بجداول ومعادلات، يُنتج marker وDocling مخرجات أفضل بشكل ملحوظ. الخيار "الأفضل" يتوقّف على ما إذا كنت تُحسِّن لزمن الإعداد أم لدقّة المخرجات.
هل يستطيع ChatGPT أو Claude تحويل PDF إلى Markdown؟
نعم، مع تحفّظات. كلاهما يستطيع قراءة PDF مباشرة وإنتاج Markdown، لكن في المستندات الطويلة قد تصطدم بحدود السياق، ودقّة الجداول والمعادلات تتذبذب بين التشغيلات. للتحويلات الدفعية الحتمية، محوّل متخصّص أكثر موثوقية. انظر تصدير ChatGPT إلى Word/PDF/HTML لسير العمل ذي العلاقة في الاتجاه المعاكس.
كيف أحوّل ملف PDF ممسوح ضوئيًا إلى Markdown؟
شغّل OCR أولًا. أنظف مسار هو ocrmypdf لإضافة طبقة نص، ثم يعمل أي محوّل على ملف PDF بعد OCR. بديلًا، يضمّ marker وDocling OCR داخليًا ويُنتجان Markdown مباشرة من ملفات PDF التي هي صور فقط.
هل تحويل PDF إلى Markdown عبر الإنترنت يحفظ الخصوصية؟
في محوّلنا، تُعالَج الملفات داخل الذاكرة وتُسقَط بعد التحويل — بلا حساب، بلا تخزين دائم. تختلف الخدمات الأخرى؛ راجع سياسة خصوصية أي أداة تستخدمها، خصوصًا للمستندات السرّية.
كيف أبقي الجداول سليمة عند التحويل من PDF إلى Markdown؟
تخطّ خط pdftotext + Pandoc للملفات الغنية بالجداول — يكاد يُشوّهها دائمًا. استخدم محوّلًا عبر الإنترنت يُصدر جداول GFM، أو استخدم مستخرج ذكاء اصطناعي مثل marker أو Docling. افحص أول بضعة جداول في الحالتين.
هل أحتفظ بـ PDF الأصلي أم بـ Markdown فقط؟
احتفظ بكليهما. Markdown للاستيعاب والبحث والتحرير. PDF هو مصدر الحقيقة للاقتباس والتدقيق. أشر إلى اسم ملف PDF ونطاق الصفحات في frontmatter الخاص بـ Markdown كي تستطيع دائمًا تتبّع ادعاء إلى مصدره.
جاهز لتحويل أول PDF لك؟
إن كنت تريد النتيجة فقط، فإن محوّلنا المجاني من PDF إلى Markdown يتولّى الحالات اليومية بلا تسجيل. للخطوة التالية — تحويل ذلك Markdown إلى مستند Word مصقول أو PDF جاهز للمشاركة — راجع دليلنا Markdown إلى Word.
المراجع
- دليل مستخدم Pandoc — المرجع المعتمد لتحويل CLI.
- مواصفات GitHub Flavored Markdown — اللهجة التي يستهدفها هذا الدليل في المخرجات.
- Docling (IBM Research) — مستخرج PDF واعٍ بالتخطيط مفتوح المصدر.
- marker — أداة مفتوحة المصدر من PDF إلى Markdown بمعالجة قوية للأوراق الأكاديمية.
- pymupdf4llm — غلاف خفيف لاستخراج Markdown حول PyMuPDF.
- OCRmyPDF — يضيف طبقة نصّ قابلة للبحث إلى ملفات PDF الممسوحة ضوئيًا.